
ReazonSpeechを使ってみる その1(音声認識、Python、ReazonSpeech v1.1.0)
はじめに
2024年2月14日に、ReazonSpeech v2.0が公開されました。それに伴い、環境構築の方法が変わっています。
https://research.reazon.jp/blog/2024-02-14-ReazonSpeech.html
この記事を公開したのは2月8日で、現在のバージョンとは構築方法が異なります。
Windowsでは動かず、現在調査中です。
▼Ubuntuなら動きました。
https://404background.com/program/reazonspeech-2/
以前VOICEVOX COREを使った音声合成を試してみました。今回は音声認識です。
音声認識だとOpen AIのWhisperや、以前使ったGoogleのSpeech to Textも選択肢としてありますが、お金がかかります。そんな中、日本語用に公開されているReazonSpeechを見つけたので使ってみました。
▼商用利用可能として紹介されていますが、ライセンスはご確認ください。
https://research.reazon.jp/news/reazonspeech.html
▼ブラウザ上でも試すことができます。
https://research.reazon.jp/projects/ReazonSpeech/index.html
毎度のことながら、環境構築が一番大変だったりします。Hugging Faceを利用するのがはじめてなので、少し戸惑いました。
▼以前の記事はこちら
PythonでVOICEVOX COREを使ってみる(音声合成)
はじめに 以前の記事でGoogle Cloud Platformの音声合成・音声認識を試したのですが、利用回数が多いとお金がかかります。やっぱり無料で実行したいということで、今回…

Text-to-Speech API / Speech-to-Text APIを使ってみる(Google Cloud Platform)
はじめに 今回はGCP(Google Cloud Platform)のText-to-Speech APIとSpeech-to-Text APIを使ってみました。以下にまとめるように、音声系のAPIですね。 Text-to-Speech A…

環境を構築する
今回はWindows環境で実行しています。
概要
▼ReazonSpeechのクイックスタートはこちら。
https://research.reazon.jp/projects/ReazonSpeech/quickstart.html
▼How toはこちら。こちらには日本語音声コーパスにPythonでアクセスする方法について書かれています。
https://research.reazon.jp/projects/ReazonSpeech/howto.html
コーパス(corpus)は簡単に言うと、自然言語処理用のデータベースです。音声認識を行うだけなら、アクセスすることはないかもしれません。
▼こちらの記事も参考になりました。
https://qiita.com/e_e99/items/7f70bdfca3ce9a02d9cd
データセットは、GitHubに似た機械学習向けのHugging Faceで公開されています。
▼Hugging Faceのクイックスタートはこちら
https://huggingface.co/docs/huggingface_hub/quick-start
Pythonの仮想環境を用意する
機械学習関係の勉強をしていると、Pythonの仮想環境を用意することが多いように思います。パッケージの依存関係を環境ごとに切り替えることができるので便利です。
環境構築をするたびにバージョンの違いで悩まされた経験が無いと、馴染みがないかもしれません。
▼venvでreazonフォルダに仮想環境を作成し、Scriptsフォルダのactivateファイルを実行することで、仮想環境が有効になります。
python -m venv reazon
cd reazon/Scripts
activate
以降、仮想環境内でコマンドを実行します。
ReazonSpeechのインストール
pipでインストールします。コーパスにアクセスしないのであれば、これだけでOKです。
pip install wheel
pip install git+https://github.com/reazon-research/reazonspeech.git
Hugging Faceの準備
※日本語音声コーパスにアクセスする場合は必要になります。
まずはHugging Faceのアカウントを作成してください。SettingsのAccess Tokensから発行できるトークンが必要になります。
▼このトークンは後で使用します。
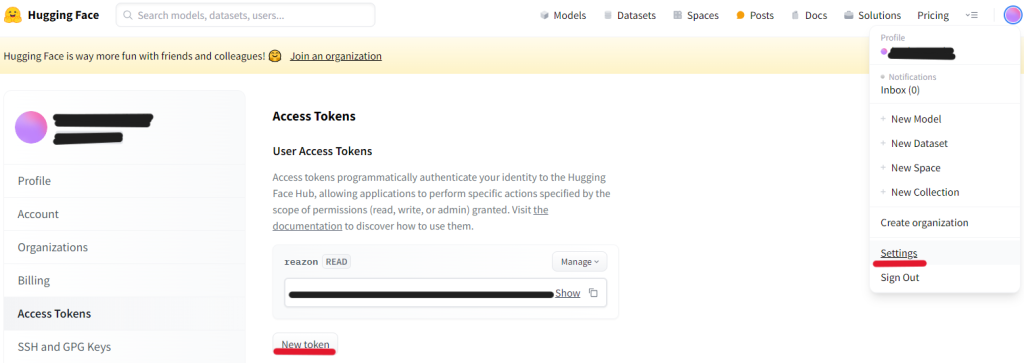
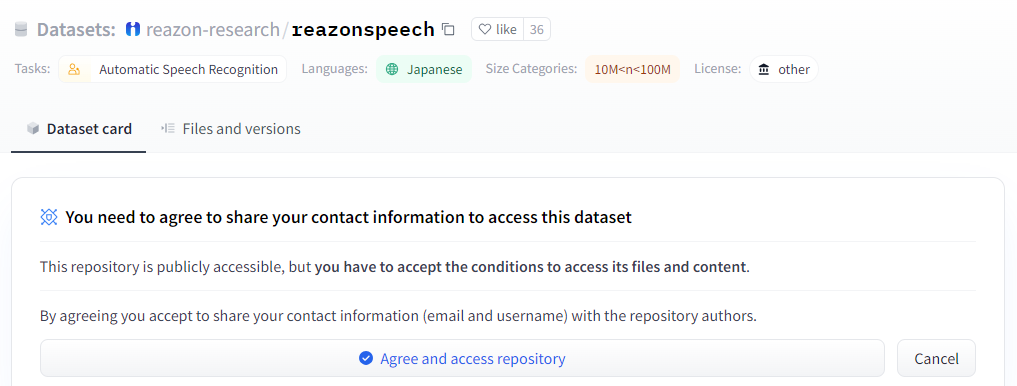
また、今回使用するreazonspeechのデータセットがあるページで、リポジトリにアクセスするために同意する必要があります。
▼Hugging Faceでのページはこちら。
https://huggingface.co/datasets/reazon-research/reazonspeech
▼これを設定していない場合、アクセスする権限がないというエラーが出ました。
Access to dataset reazon-research/reazonspeech is restricted and you are not in the authorized list.
Visit https://huggingface.co/datasets/reazon-research/reazonspeech to ask for access.
ターミナルでhuggingface_hubをインストールし、ログインします。コピーしたトークンは、右クリックでペーストできます。
▼コマンドの実行後、Access Tokenを聞かれます。
pip install --upgrade huggingface_hub
huggingface-cli login
途中で Add token as git credential? (Y/n) と聞かれたのですが、Yだとログインできました。
▼nだと以下のエラーが出ました。
ValueError: Invalid token passed!
音声ファイルからテキストを抽出する
reazonspeechを実行する
クイックスタートの記事にspeech-001.wavがあります。まずはこの音声ファイルからテキストを抽出してみました。
▼speech-001.wavを読み込む場合のコマンドはこちら。初回は特に時間がかかるかもしれません。
reazonspeech .\speech-001.wav
実行後、一分ぐらい経ってからテキストが出力されました。結構時間がかかりますね。私のノートパソコンのCPUがほぼ100%使われているような状態だったので、実行環境によって変わると思います。
▼コンソールでの表示はこちら
{"start_seconds": 0.528, "end_seconds": 5.325, "text": "気象庁は雪や路面の凍結による交通への影響"}
{"start_seconds": 5.325, "end_seconds": 12.521, "text": "暴風雪や高波に警戒するとともに雪崩や屋根からの落雪にも十分注意するよう呼びかけています"}
▼前回の記事で環境を構築したVOICEVOX COREの音声ファイルを読み込ませてみました。これで出力に13秒ぐらいかかりました。
{"start_seconds": 0.148, "end_seconds": 0.543, "text": "こんにちは"}
ストリーム処理を行う
ストリーム処理ができるとのことだったので、ソースコードを読んでみました。
▼APIリファレンスはこちら
https://research.reazon.jp/projects/ReazonSpeech/api.html
▼ソースコードはこちら
https://github.com/reazon-research/ReazonSpeech
interface.pyにあるTranscribeConfigクラスのwindowの値で、音声処理のウィンドウの長さが決められています。デフォルトでは320000 (20秒)です。この数値を変えられるようにしてみました。
▼プログラムはこちら
import reazonspeech as rs
config = rs.interface.TranscribeConfig()
config.window = 32000
for caption in rs.transcribe("speech-001.wav", config=config):
print(caption)▼config.window = 3200の場合はこんな感じ。短すぎて、何を言っているのか分からない状態です。
Caption(start_seconds=0.0, end_seconds=0.2, text='はい')
Caption(start_seconds=0.2, end_seconds=0.4, text='あ')
Caption(start_seconds=0.4, end_seconds=0.6, text='え')
Caption(start_seconds=0.6, end_seconds=0.8, text='でしょ')
Caption(start_seconds=0.8, end_seconds=1.0, text='部長')
Caption(start_seconds=1.0, end_seconds=1.2, text='うわ')
Caption(start_seconds=1.2, end_seconds=1.4, text='あっ')
Caption(start_seconds=1.4, end_seconds=1.6, text='あ')
Caption(start_seconds=1.6, end_seconds=1.8, text='あ')
Caption(start_seconds=1.8, end_seconds=2.0, text='ゆっくり')
Caption(start_seconds=2.0, end_seconds=2.2, text='ギア')
Caption(start_seconds=2.2, end_seconds=2.4, text='あっ')
Caption(start_seconds=2.4, end_seconds=2.6, text='ドン')
Caption(start_seconds=2.6, end_seconds=2.8, text='ペン')
▼config.window = 32000の場合はこんな感じ。大体あっています。ちょっとずつ出力されました。
Caption(start_seconds=0.5237964285714286, end_seconds=0.999975, text='気象庁は')
Caption(start_seconds=2.285651515151515, end_seconds=3.0951477272727272, text='雪や路面の凍結による')
Caption(start_seconds=3.3332361111111113, end_seconds=3.857034722222222, text='警察による交通')
Caption(start_seconds=4.666538461538462, end_seconds=4.9998629807692305, text='交通への影響')
Caption(start_seconds=5.904607142857143, end_seconds=6.523645089285714, text='暴風雪や高波に')
Caption(start_seconds=6.761732142857143, end_seconds=6.8093482142857145, text='いけ')
Caption(start_seconds=7.6188359375, end_seconds=8.142625, text='警戒するとともに')
Caption(start_seconds=8.714036637931034, end_seconds=9.761644396551725, text='左や屋根からの落下')
日本語音声コーパスにアクセスする場合
音声コーパスはsmall版で350MB、all版で1.3TBもあるみたいです。
▼必要なパッケージをインストールします。
pip install datasets soundfile librosa wheel
▼データセットを読み込むときのプログラムはこんな感じ
from datasets import load_dataset
ds = load_dataset("reazon-research/reazonspeech")
ds["train"]
print(ds["train"][2000])▼コンソールでの表示はこちら(パスは削除し、一部改行しています。)
{'name': '000/57b6f7027e24f.flac', 'audio': {'path': '...',
'array': array([-0.01190186, 0.05636597, 0.05853271, …, -0.03302002, -0.02532959, -0.01998901]),
'sampling_rate': 16000},
'transcription': '週末の天気を詳しく解説。'}
▼FutureWarningが出ているのが気になりました。読み込めてはいるようです。
FutureWarning: The repository for reazon-research/reazonspeech contains custom code which must be executed to correctly load the dataset.
You can inspect the repository content at https://hf.co/datasets/reazon-research/reazonspeech
You can avoid this message in future by passing the argument `trust_remote_code=True`.
Passing `trust_remote_code=True` will be mandatory to load this dataset from the next major release of `datasets`.
warnings.warn(
最後に
実行してみて、認識するまでに時間がかかるように感じました。データセットが巨大ですし、ノートパソコンで実行するとそうなるのかな?という印象です。
▼認識時間については、比較している記事を見つけました。結構かかるんですね。
https://dev.classmethod.jp/articles/reazon-speech-transcribe-meeting/
ストリーム処理ができるので、使い方次第かもしれません。音声合成、音声認識ができたので、次は質問応答を試したいところです。

