Text-to-Speech API / Speech-to-Text APIを使ってみる(Google Cloud Platform)

はじめに
今回はGCP(Google Cloud Platform)のText-to-Speech APIとSpeech-to-Text APIを使ってみました。以下にまとめるように、音声系のAPIですね。
- Text-to-Speech API:文字列から音声ファイルの出力、音声の種類なども選択できる
- Speech-to-Text API:音声ファイルから文字列の出力、ストリーミングでの音声認識もできる
これを使って何をしたいのかというと、ロボットと対話したいのです。スマートスピーカーのように日常生活を便利にするものではなく、ゲームに出てくるような言語を理解しながら自律して動くロボットにしようと思っています。カメラを使った画像認識なども取り入れる予定です。
書籍で見つけたので試してみることにしました。GCPは他にも面白そうなAPIがあります。なお、書籍で紹介されているサンプルプログラムについては、このページには掲載しません。予めご了承ください。
▼GCPのページに、今回のAPIに関連したサンプルプログラムがあります。
https://cloud.google.com/text-to-speech/docs/samples?hl=ja
https://cloud.google.com/speech-to-text/docs/tutorials?hl=ja
▼こちらの書籍で紹介されていました。

Text-to-Speech APIのプレビュー機能を試してみる
Text-to-Speech APIについてはプレビュー機能があって、クラウド上で音声ファイルの出力を試すことができます。
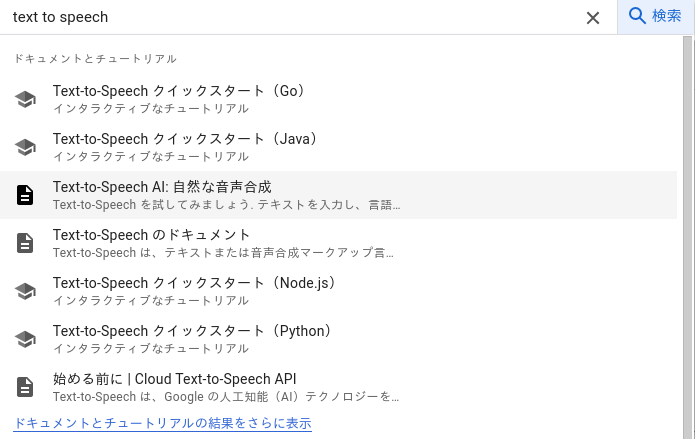
▼検索欄から開くことができます。
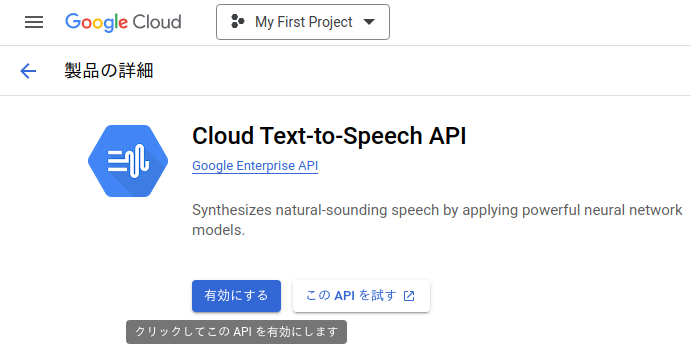
▼APIを有効にしておきます。APIを試すという選択肢から、プレビュー機能を試すことができます。
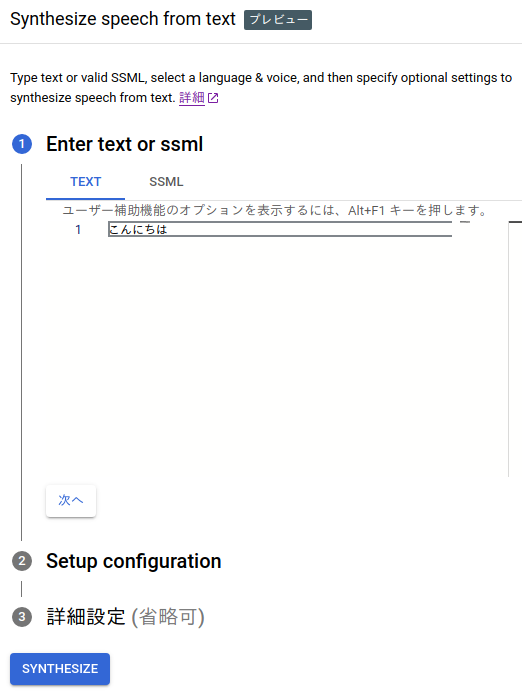
▼まずは発声させたいテキストを入力します。日本語にも対応しています。
▼SSMLという選択肢もあったのですが、これは音声合成用のマークアップ言語だそうです。
https://cloud.google.com/text-to-speech/docs/ssml?hl=ja
▼言語と音声の種類を選択します。男声だったり、女声だったりします。
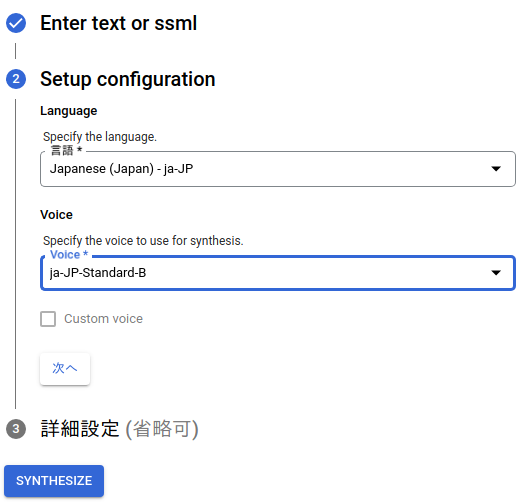
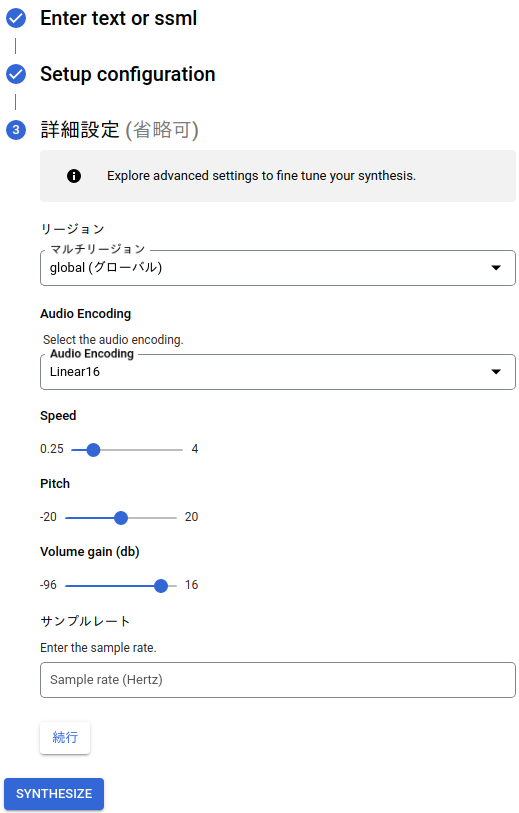
▼詳細設定も変更できます。最後にSYNTHESIZEを押すと、音声ファイルが作成されます。
SYNTHESIZE後は、.wav形式で音声ファイルをダウンロードできます。
サービスアカウントキーを準備する
あとでPythonからAPIを利用するために、サービスアカウントキーを用意する必要があります。
▼認証情報を作成の欄から、サービスアカウントを作成します。
▼必要項目を入力してください。
▼アカウントを作成後、メールアドレスを選択すると詳細な設定を見ることができます。
▼キーの選択肢から、新しい鍵を作成することができます。
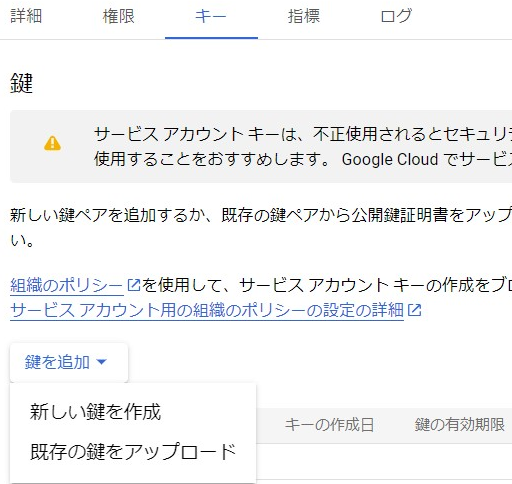
今回はjson形式の鍵をダウンロードしました。
Pythonで実行する
今回はWindows環境にインストールした、Anacondaの環境で実行しています。
GCPのAPIを使う前に、先ほど作成した鍵のパスを環境変数に設定する必要があります。Anacondaのコマンドプロンプトで以下のコマンドを実行すると、環境変数が設定されます。
▼鍵の場所は適宜変更してください。
set GOOGLE_APPLICATION_CREDENTIALS=鍵の場所
パッケージをインストールする
▼以下のコマンドで必要なパッケージをインストールしました。
pip install google-cloud-texttospeech
pip install google-cloud-speech
PyAudioというパッケージも使うのですが、書籍によるとPython 3.7以降ではWindows環境だと動作しないようです。私の場合はPython 3.8.5だったので、以下のリンクから「PyAudio‑0.2.11‑cp38‑cp38m‑win_amd64.whl」をダウンロードしました。
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio
書籍では「PyAudio‑0.2.11‑cp37‑cp37m‑win_amd64.whl」だったのですがエラーが出ていたので、Pythonのバージョンが違うからだと思います。プログラムを実行したところ、問題なく動作しました。
▼Pythonのバージョンを調べるコマンドはこちら
python -V
▼私の場合は先にpipでpyaudioをインストールしていたので、以下のコマンドで一旦削除しないとインストールできませんでした。
pip uninstall pyaudio
▼インストールするためのコマンドはこちら。
pip install PyAudio-0.2.11-cp38-cp38-win_amd64.whl
サンプルプログラムを実行してみる
プログラムはAnacondaの環境変数を設定したコマンドプロンプトで、 python プログラム名.py と入力して実行しています。
Text-to-Speech APIの場合、文字列を音声に変換することができました。
▼実際に生成された音声ファイルはこちら
Speech-to-Text APIの場合は、マイクで取得した音声が文字列に変換されました。
▼実際にストリーミング中に認識したテキストがこちら。反応が早いです。途中で補正しているような挙動が見られましたが、プログラム内で中間結果が表示されるようです。

オウム返しをするプログラムを書く
サンプルプログラムをもとに、Speech-to-Textで音声をテキストに変換し、Text-to-Speechでテキストから音声ファイルを生成して再生するプログラムを作成してみました。
▼プログラムはこちら
from google.cloud import texttospeech
from google.cloud import speech
import sys
import pyaudio
from six.moves import queue
# マイク音声のストリーム
class MicStream:
# 初期化
def __init__(self, rate, chunk):
self._rate = rate # サンプルレート
self._chunk = chunk # チャンクサイズ
self._buff = queue.Queue() # マイク入力データを貯めるバッファ
self.closed = True # クローズ
# リソース確保
def __enter__(self):
# PyAudioでマイク入力を開始
self._audio_interface = pyaudio.PyAudio()
self._audio_stream = self._audio_interface.open(
format=pyaudio.paInt16, # フォーマット
channels=1, # チャンネル数
rate=self._rate, # サンプルレート
input=True, # 入力
frames_per_buffer=self._chunk, # チャンクサイズ
stream_callback=self._fill_buffer, # コールバック
)
self.closed = False # オープン
return self
# リソース破棄
def __exit__(self, type, value, traceback):
self._audio_stream.stop_stream() # ストリーム停止
self._audio_stream.close() # ストリームクローズ
self.closed = True # クローズ
self._buff.put(None) # バッファ解放
self._audio_interface.terminate() # オーディオ解放
# マイク入力データをバッファに貯める
def _fill_buffer(self, in_data, frame_count, time_info, status_flags):
self._buff.put(in_data)
return None, pyaudio.paContinue
# ストリームの生成
def generator(self):
while not self.closed:
# 少なくとも1つのチャンクがあることを確認
chunk = self._buff.get()
if chunk is None:
return
data = [chunk]
# バッファリングされているデータを全て消費
while True:
try:
chunk = self._buff.get(block=False)
if chunk is None:
return
data.append(chunk)
except queue.Empty:
break
yield b''.join(data)
# ストリーミング音声認識の結果の取得
def listen_print_loop(responses):
num_chars_printed = 0
# メインループ
for response in responses:
# 入力リクエストが有効かどうか
if not response.results:
continue
result = response.results[0]
if not result.alternatives:
continue
# テキストの取得
transcript = result.alternatives[0].transcript
overwrite_chars = ' ' * (num_chars_printed - len(transcript))
# 音声認識中のテキスト出力
if not result.is_final:
sys.stdout.write(transcript + overwrite_chars + '\r')
sys.stdout.flush()
num_chars_printed = len(transcript)
# 音声認識確定後のテキスト出力
else:
print(transcript + overwrite_chars)
num_chars_printed = 0
'''Text-to-Speechの処理'''
text= transcript + overwrite_chars
synthesis_input = texttospeech.SynthesisInput(text=text)
voice = texttospeech.VoiceSelectionParams(
language_code='ja-JP',
ssml_gender=texttospeech.SsmlVoiceGender.NEUTRAL
)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.LINEAR16
)
client = texttospeech.TextToSpeechClient()
response = client.synthesize_speech(
input=synthesis_input,
voice=voice,
audio_config=audio_config
)
with open('parrot.wav', 'wb') as out:
out.write(response.audio_content)
#作成した音声ファイルの再生
from playsound import playsound
playsound("parrot.wav")
print('end')
break
# 録音パラメータの準備
RATE = 16000 # サンプルレート
CHUNK = int(RATE / 10) # チャンクサイズ (100ms)
# 音声認識設定の準備
config = speech.RecognitionConfig(
encoding=speech.RecognitionConfig.AudioEncoding.LINEAR16, # オーディオ種別
sample_rate_hertz=RATE, # サンプルレート
language_code='ja',
)
# ストリーミング音声認識設定の準備
streaming_config = speech.StreamingRecognitionConfig(
config=config, # 音声認識設定
interim_results=True # 中間結果の取得
)
# マイク音声のストリームの生成
with MicStream(RATE, CHUNK) as stream:
audio_generator = stream.generator()
# 入力リクエストの準備
requests = (
speech.StreamingRecognizeRequest(audio_content=content)
for content in audio_generator
)
# ストリーミング音声認識の実行
client = speech.SpeechClient()
responses = client.streaming_recognize(
config=streaming_config, # ストリーミング音声認識設定
requests=requests) # 入力リクエスト
# ストリーミング音声認識の結果の取得
listen_print_loop(responses)▼プログラムを実行したときのコマンドプロンプトと音声データはこちら。

プログラムを実行してみて、周囲が静かだと認識しやすいのですが、騒がしいと入力待ち状態になっていることがありました。パラメータを調整しないといけないかもしれません。
最後に
音声をテキストに変換できるようになったので、ロボットの操作に使えるようにしたいと思います。音声での応答もできそうですね。さらに自然言語処理や画像認識も取り入れたいところです。
GCPのサービスを使うのは初めてなのですが、自力でプログラムを書くと複雑になることが手軽に試せるのは便利ですね。あとは使いこなせるかどうか…
▼Pythonでの音声認識・音声合成に関する書籍を読んでみたのですが、全てを理解するのに時間がかかりそうでした。ハードウェアも作るので、ソフトウェアだけに時間をかけたくないのです。サービス化されているのはありがたいです。
趣味的ロボット研究所をもっと見る
購読すると最新の投稿がメールで送信されます。