ReazonSpeechを使ってみる その2(Ubuntu 22.04、ReazonSpeech v2.0、Node-RED)
はじめに
以前の記事で日本語用の音声認識モデルであるReazonSpeechを使ってみたのですが、最近になって環境を構築しようとすると、いろいろ変わっていることに気づきました。
調べてみると、ReazonSpeech v2.0になっていたようです。
▼2/14なので、私の記事を公開した6日後ですね。何というタイミング...
https://research.reazon.jp/blog/2024-02-14-ReazonSpeech.html
改めてUbuntu環境にReazonSpeech v2.0の環境を構築して試してみました。Windows環境でも試したのですが、エラーが出て環境を構築できず、現在検証中です。
「推論速度を大幅に高速化」と書かれていたので、気になるところです。音声コーパスも35000時間に拡大しているようです。
なお、音声認識モデルには「NeMo」と「ESPnet」があるようなのですが、今回はNeMoを試してみました。
▼以前の記事はこちら
ReazonSpeechを使ってみる その1(音声認識、Python、ReazonSpeech v1.1.0)
はじめに 以前VOICEVOX COREを使った音声合成を試してみました。今回は音声認識です。 音声認識だとOpen AIのWhisperや、以前使ったGoogleのSpeech to Textも選択肢と…

Text-to-Speech API / Speech-to-Text APIを使ってみる(Google Cloud Platform)
はじめに 今回はGCP(Google Cloud Platform)のText-to-Speech APIとSpeech-to-Text APIを使ってみました。以下にまとめるように、音声系のAPIですね。 これを使 [&hel…

NeMo関連の情報
▼ReazonSpeech v2.0のブログ記事はこちら
https://research.reazon.jp/blog/2024-02-14-ReazonSpeech.html
▼Hugging Faceのページはこちら
https://huggingface.co/reazon-research/reazonspeech-nemo-v2
▼クイックスタートのページはこちら。こちらのページを参考に環境を構築します。
https://research.reazon.jp/projects/ReazonSpeech/quickstart.html
▼How toガイドはこちら。Pythonでの利用方法も書かれています。
https://research.reazon.jp/projects/ReazonSpeech/howto.html#nemo-asr
▼reazonspeech.nemo.asrのAPIリファレンスはこちら
https://research.reazon.jp/projects/ReazonSpeech/api/reazonspeech.nemo.asr.html
環境を構築する
基本的にはクイックスタートのページを参考に、コマンドを実行していきます。
▼まずはPythonの仮想環境を作成します。今回はreazonという名前にしました。
python3 -m venv reazon
source reazon/bin/activate
このとき、python3.10-venvやpipが入っていないとエラーが起きるかもしれません。
▼以下のコマンドでインストールしました。
sudo apt install python3.10-venv
sudo apt install python3-pip
必要なパッケージをインストールします。
▼以下のコマンドを実行しました。
sudo apt install ffmpeg
pip install Cython
git clone https://github.com/reazon-research/ReazonSpeech
pip install ReazonSpeech/pkg/nemo-asr
私の場合、ReazonSpeech/pkg/nemo-asrをpipでインストールするときに、エラーが起きました。
▼numpyが無いというエラーですね。
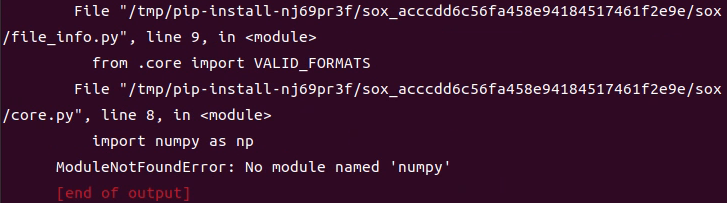
pip install numpy でnumpyをインストール後、もう一度コマンドを実行するとエラーが出ました。
▼今度はtyping_extensionsが無いというエラーが出ました。これも pip install typing_extensions でインストールしました。
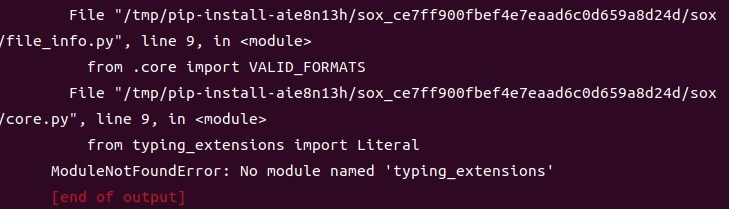
この後、再度 pip install ReazonSpeech/pkg/nemo-asr を実行すると、インストールできました。
ここまで完了すれば、以下のコマンドでreazonspeech-nemo-asrを実行できるかと思います。なお、初回は特に時間がかかります。
reazonspeech-nemo-asr speech-001.wav
▼実行してみると、モデルのロードの後にテキストが出力されました。
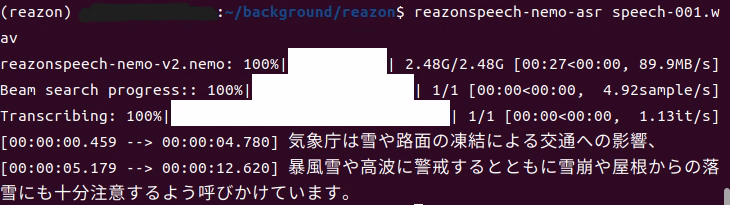
▼音声ファイルは、ReazonSpeechのこちらのページからダウンロードできます。
https://research.reazon.jp/projects/ReazonSpeech/index.html
動作したところで、PythonとPipのバージョンを確認しておきました。
▼Pythonは3.10.12、pipは22.0.2です。

Node-REDで実行してみる
Node-REDのexecノードでコマンドを実行してみました。これで実行できれば、ReazonSpeech用のノードを作成することができます。
▼execノードについてはこちら。コマンドを実行できるノードです。
Node-REDを使ってみる その1(execノード、Pythonプログラム実行)
はじめに 今回はNode-REDのexecノードを使ってみました。コマンドを実行できるノードです。 私はNode-RED MCUを先に使い始めたので、Node-RED自体はあまり使っていま…
▼フローはこちら。
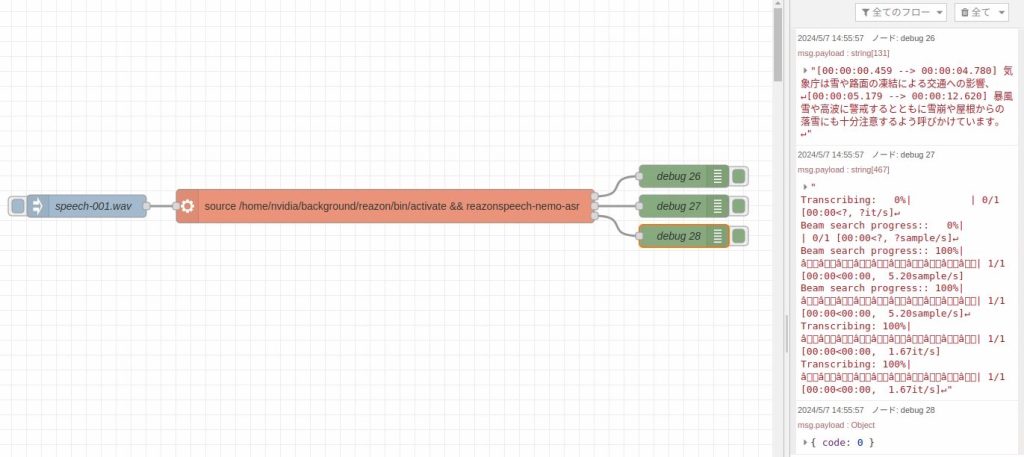
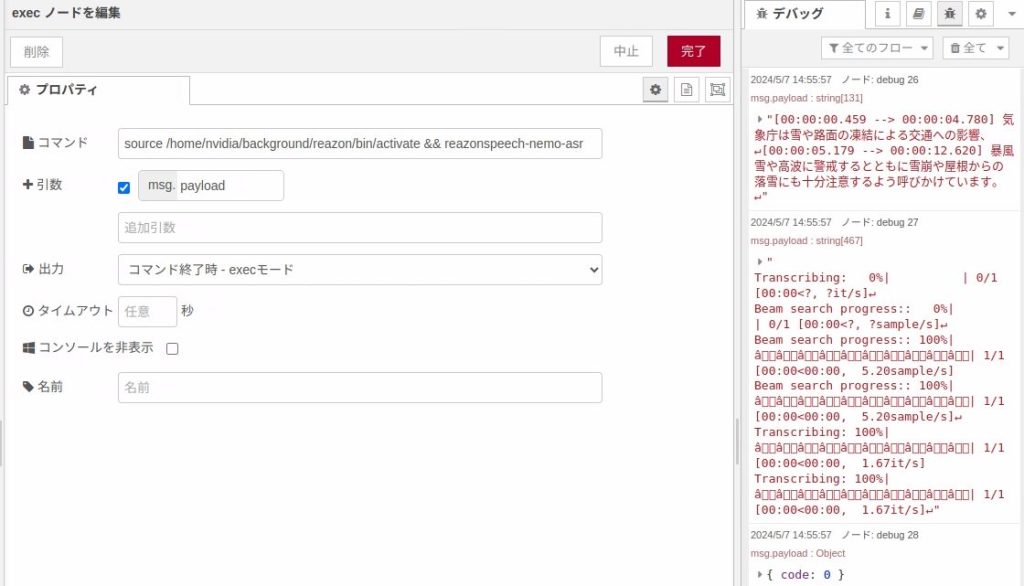
execノードでは仮想環境をactivateした後、reazonspeech-nemo-asrを実行しています。
▼音声ファイルの絶対パスを、msg.payloadで引数として受け取っています。
デバッグウィンドウに表示されているように、実行することができました。取得したテキストを加工して、他のノードと連携させるといったことができそうですね。
最後に
Ubuntuだと環境を構築できたのですが、Windowsは苦戦中です。
環境構築の際にsourceやaptが使われていたあたり、Windows向けでは無いのかもしれません。最近構築したWSL2でも試してみたのですが、なぜかpipでインストールしてもreazonspeech-nemo-asrが追加されていなかったりします。また時間があるときに検証します。
numpyなどは後からもインストールされているように見えたので、修正する必要があるのかもしれません。その点、OpenAIのWhisperを試したときはWindowsでもすぐに使えて便利でした。また記事にまとめようと思っています。
趣味的ロボット研究所をもっと見る
購読すると最新の投稿がメールで送信されます。