Pythonで画像に対する文字認識 その2(NDLOCR)
はじめに
今回はNDLOCRを利用した画像に対する文字認識を試してみました。
NDLOCRはQiitaの記事で見つけました。国立国会図書館が提供しているライブラリということで、前回試したEasyOCRよりも日本語の認識精度が良いかもしれないと思い、試してみました。
▼以下の記事で紹介されていました。
https://qiita.com/yanosen_jp/items/9d3852c29c80dbb952f2
▼ndl-labのGitHubのリポジトリには、学習用のデータセットがいろいろありました。
https://github.com/orgs/ndl-lab/repositories
▼以前の記事はこちら
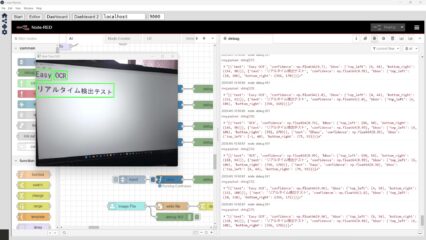
Pythonで画像に対する文字認識 その1(EasyOCR、Node-RED)
はじめに 今回はEasyOCRを利用して、画像に対する文字認識を試してみました。 OCR系のソフトウェアはいろいろあって、Tesseractも使ってみたのですが、リアルタイムで…
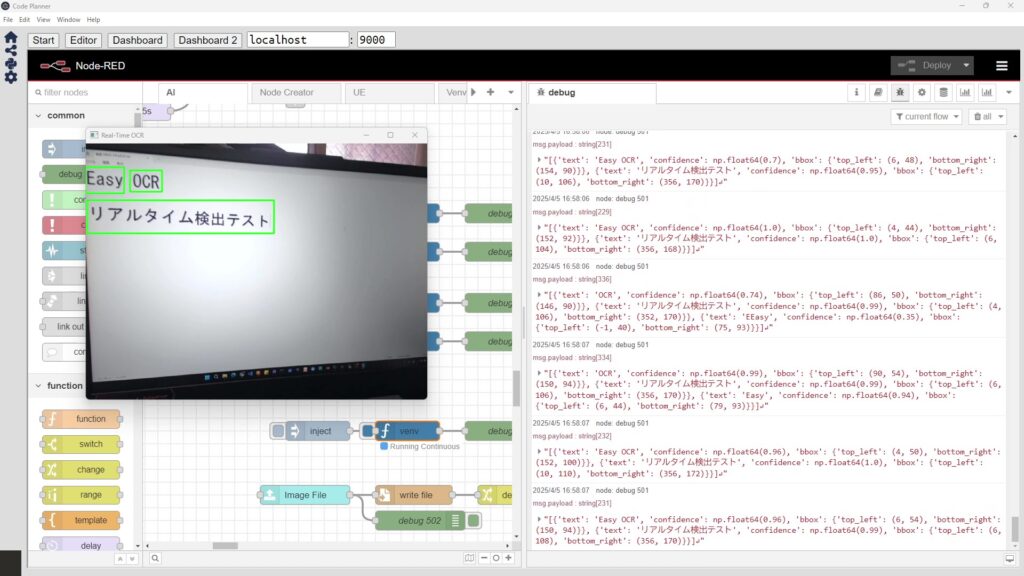
Pythonでテキストを翻訳する(Googletrans、Node-RED)
はじめに 今回はPythonでGoogletransを利用した翻訳を試してみました。 書いてはいないのですが、これまで翻訳するのにdeep-translatorも使ったことがあります。他に…
環境を構築する
Qiitaの記事のPCはメモリ容量が大きくてスペックが高そうだったのですが、私のPCはそれほどではありません。
▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


▼以下のGitHubのリポジトリを参考に環境を構築します。
https://github.com/ndl-lab/ndlocr_cli
以下のコマンドでリポジトリをクローンしておきます。
git clone --recursive https://github.com/ndl-lab/ndlocr_cliDockerの環境も必要です。
▼WindowsのDocker Desktopのダウンロードページはこちら
https://docs.docker.com/desktop/setup/install/windows-install
▼Docker DesktopはCVATでアノテーションするときにも利用しています。
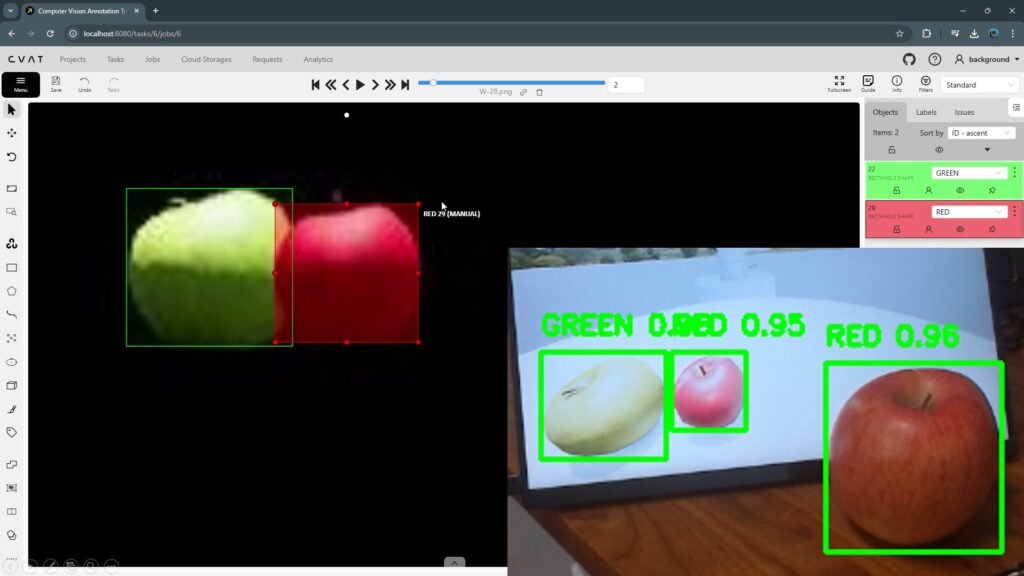
CVATでアノテーション(YOLO v8、Object Detection)
はじめに 今回はCVAT(Computer Vision Annotation Tool)でアノテーションを行ってみました。 画像に対してアノテーションを行い、YOLOで学習することで物体を検出でき…
Docker Desktopは起動した状態にしておきます。なお処理したい画像の入ったディレクトリのマウント方法について書かれていたのですが、今回は利用しません。後で画像ファイルを追加します。
以下のコマンドでクローンしたフォルダに入ってから、dockerbuild.batを実行しました。
cd ndlocr_cli
docker\dockerbuild.bat▼ビルドが始まりました。

▼一度実行したときはエラーが表示されていたのですが、もう一度実行すると問題なく進みました。
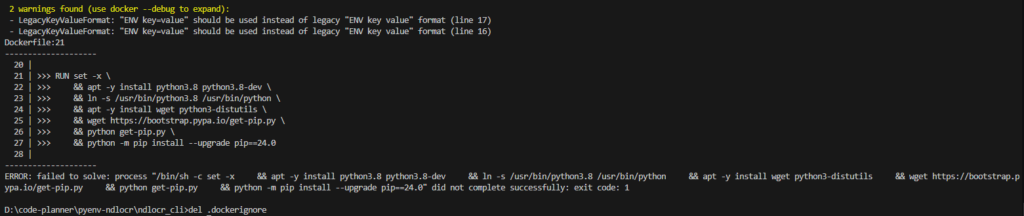

以下のコマンドでDockerのコンテナを起動します。
docker\run_docker.bat▼Docker Desktopに追加されていました。
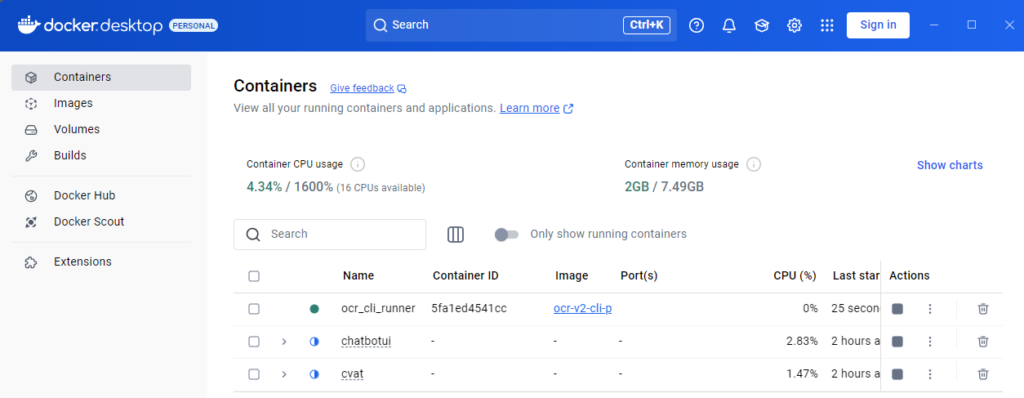
以下のコマンドでDockerのコンテナにログインします。
docker exec -it ocr_cli_runner bash▼ログインできました。

実行してみる
まずは画像ファイルをDocker環境に追加します。EasyOCRのexamplesフォルダにあった画像ファイルを利用しました。
私の場合、以下のdocker cpコマンドで以下のように実行しました。
docker cp "D:\code-planner\pyenv-ndlocr\ndlocr_cli\japanese.jpg" ocr_cli_runner:/root/ocr_cli▼Windows環境でdocker cpを実行後、コンテナでlsコマンドを実行すると、画像ファイルが追加されていました。


追加した画像ファイルに対して推論を実行します。基本的には以下のコマンドのように実行するようになっています。
python main.py infer input_data_dir output_dir -s s今回はフォルダではなく画像ファイルを指定して実行します。入力となる画像ファイルと出力先のフォルダ、画像ファイルに対する検出のオプションを指定しています。
python main.py infer japanese.jpg /root/ocr_cli/output -s f▼一度実行したときに処理が遅すぎて、一旦停止して再起動しました。
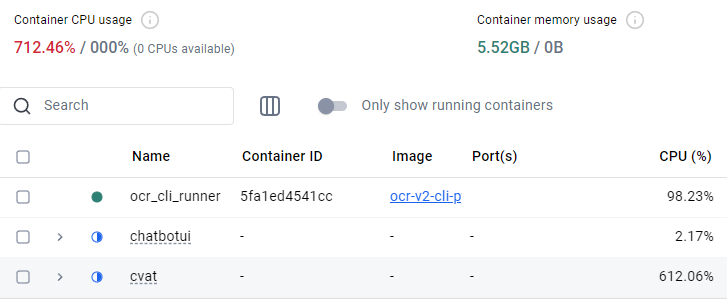
.
▼他のコンテナは停止して、dockerbuild.batから再度実行しました。その後は問題なく実行できました。
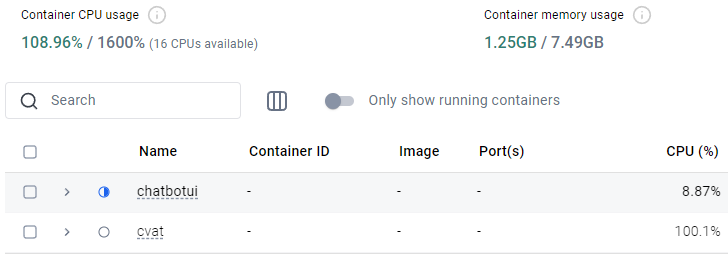
処理には1分ぐらいかかっていました。
▼処理後にoutputフォルダに結果が保存されています。

このoutputフォルダをWindows環境にdocker cpでコピーしました。
docker cp ocr_cli_runner:/root/ocr_cli/output D:\code-planner\pyenv-ndlocr\ndlocr_cli▼検出結果を確認できました。
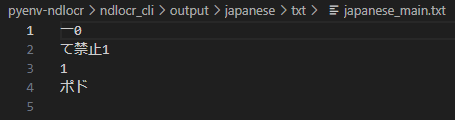
EasyOCRのときはポイ捨て禁止などが検出されていたのですが、今回は検出できていません。
国立国会図書館のライブラリなので、やはり文書の方が認識精度が高いのかな?と思い、文書の画像に対する認識を試してみました。
対象は私が書いた学会発表の要旨を、紙に印刷して撮影したものを利用しました。
▼所々おかしな部分はありますが、大体検出できています。

ここまで検出できているなら、ローカルLLMで文脈を踏まえて補正できるかもしれません。
▼EasyOCRでも検出してみたのですが、ほとんど認識できていませんでした。

最後に
NDLOCRの方が、EasyOCRよりも日本語の文書に対する検出精度が高いという結果になりました。やはり学習データの違いがあるのだろうなと思います。
NDLOCRは私のPCでは処理が重いという印象で、EasyOCRは文字が増えると遅くなるのですが、それでも軽量です。認識精度と速度のトレードオフですね。
私のPCはメモリが16GBなのですが、増設できるらしいので増やそうかなと考えています。