Whisperを使ってみる(音声認識、OpenAI、Python)
はじめに
今回はOpenAIのWhisperを使ってみました。
OpenAIのサービスはAPIキーを使って有料で利用するイメージがあったのですが、ソースコードはMIT Licenseで公開されているようですね。複数言語にも対応している、強力な音声認識モデルです。
Whisperを使って、音声で命令してロボットを動かしたいなと考えています。そのため、短い音声からテキストを抽出することを重視しています。
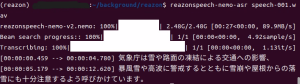
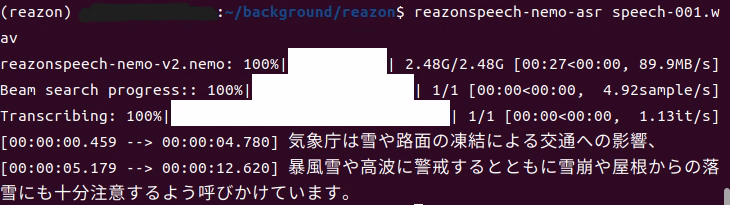
▼日本語の音声認識モデル用にReazonSpeechも試していたのですが、アップデートによって環境構築の方法が変わったようです。Ubuntuでは動きました。
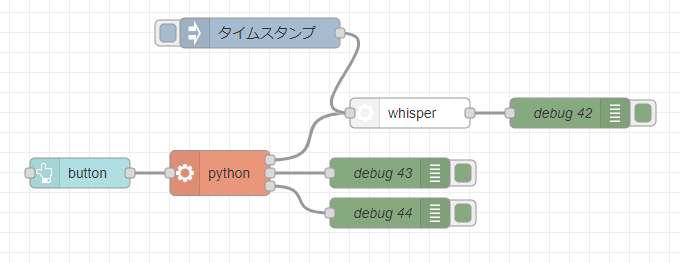
ReazonSpeechを使ってみる その2(Ubuntu 22.04、ReazonSpeech v2.0、Node-RED)
はじめに 以前の記事で日本語用の音声認識モデルであるReazonSpeechを使ってみたのですが、最近になって環境を構築しようとすると、いろいろ変わっていることに気づきま…
▼以前の記事はこちら
Node-REDのノードを作成してみる その1(python-venv)
はじめに 今回はNode-REDでPythonの仮想環境を利用できるノードを作成してみました。 これまでNode-RED MCU用のノードを作成したことはありますが、Node-RED用は2つ目…

ROS2を使ってみる その1(環境構築、Windows)
はじめに 今回はROS2の環境構築です。何度か挑戦して諦めていたのですが、今度こそちゃんと動かせるようにしてみます。 つい最近参加していたROS Japan UGでは、ROS1…

環境を構築してみる
今回はWindows環境で構築します。
▼GitHubのリポジトリの、READMEに従って構築しました。
https://github.com/openai/whisper
▼以下のコマンドでパッケージをインストールできます。
pip install -U openai-whisper
▼-Uオプションについて気になったのですが、こちらに書かれていました。Upgradeのことみたいです。
https://kurozumi.github.io/pip/reference/pip_install.html#options
あとはffmpegが必要で、インストール方法がいくつか提示されていました。私はWindows用のダウンロードページからインストールしました。
▼ffmpegのダウンロードページはこちら。
https://ffmpeg.org/download.html
▼パスの通し方は、こちらに書かれています。
WindowsにFFmpegをインストールして利用できるようにパスを通す | taziku / 生成AI開発・クリエイティブスタジオ | 東京・名古屋
生成AIでも利用されるFFmpeg。FFmpegとは何か?から、FFmpegダウンロードとインストール手順を順を追って紹介し、動作確認方法までお伝えします。

▼私の場合、 ffmpeg -version コマンドで、すでにバージョンを確認できる状態になっていました。
一応、ROS2の環境構築時にchocolateyをインストールしていたので、chocoコマンドでインストールしてみました。
▼chocolateyをインストールする場合はこちら
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
▼インストール用のコマンドはこちら
choco install ffmpeg
▼コマンドを実行すると、エラーが出ていました。インストール済みではあったので、後でプログラムを実行することはできました。
whisperコマンドを実行してみました。初回はモデルの読み込みがあるので時間がかかります。
▼以下のコマンドで実行してみました。ちゃんとテキストになっています。
whisper <音声ファイルの名前> --language Japanese

Pythonで実行してみる
READMEにPythonのプログラムがあったので、実行してみました。
他にも参考になりそうなプログラムがありました。
▼こちらのプログラムが、コメント付きで分かりやすそうでした。
https://gist.github.com/ThioJoe/e84c4e649857bf0a290b49a2caa670f7
▼こちらは自動文字起こしのためのプログラムのようですね。
https://github.com/tomchang25/whisper-auto-transcribe
注意点
注意点として、Pythonのプログラムを保存するファイルの名前はwhisper以外のものにしてください。インストールしたパッケージではなくwhisper.pyファイルが読み込まれてしまうと、以下のようなエラーが出ます。
▼whisperにはload_modelが無いというエラーです。内容の違う同名のファイルを読み込んでしまった状態ですね。
Traceback (most recent call last):
File ".\transcribe.py", line 1, in <module>
import whisper
File "C:\Users\mgs_1\Desktop\github-workspace\node-red-contrib-whisper\whisper.py", line 3, in <module>
model = whisper.load_model("base")
AttributeError: partially initialized module 'whisper' has no attribute 'load_model'
(most likely due to a circular import)
▼こちらでも議論されていました。私もやらかしたんですよね...
https://github.com/openai/whisper/discussions/143
プログラムを実行してみる
今回は自分の音声を録音して、試してみました。
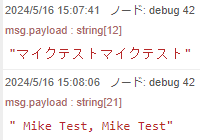
▼「マイクテストマイクテスト」と話しています。
▼3Dプリンターが動いている近くで録音してみたのですが、あまり雑音が入っていないようですね。
▼まずはシンプルなプログラムを実行してみました。
import whisper
model = whisper.load_model("base")
result = model.transcribe("マイクテスト.wav", language='japanese')
print(result["text"])▼実行後、テキストになって出力されました。

whisper.load_model()でモデルの大きさを選択できます。baseだと処理に7秒ぐらいかかって、tinyだと3秒ぐらいで終わりました。
READMEにも書かれているのですが、モデルによる相対的な速度が示されています。一番遅いlargeを1とすると、tinyは32倍、baseは16倍程度速いようです。
使いどころによって分けると良さそうですね。私のノートパソコンだとそれほど処理が早くないですし、短文を処理できればいいので、tinyでも良いように思います。
ただし精度は劣るようで、他にも録音した音声を試したのですが、同音異義語になったり変な文章になったりしていました。でも同音異義語はしょうがない気もしますね...
▼言語の種類は、tokenizer.pyに書かれているようです。
https://github.com/openai/whisper/blob/main/whisper/tokenizer.py
▼languageをjapaneseからenglishに変更したところ、ちゃんと変わっているようでした。
もう一つのサンプルプログラムを試してみました。
▼こちらのプログラムでは、30秒ごとのウィンドウをずらして処理されるようです。
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("マイクテスト.wav")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
path = 'whisper.tmp'
with open(path, mode='w', encoding='UTF-8') as f:
f.write(result.text)
こちらのプログラムだと処理が遅くて、50秒くらいかかったりしました。話していた言語を特定するのにも時間がかかっていました。
30秒ごとに処理を行うようですし、長時間の音声ファイルを処理するためのものでしょうね。今回は短い音声だったので、適していないように思います。
最後に出力されたテキストをファイルに保存しています。これは、Node-REDで実行してみると文字化けして表示されていたので、一旦保存してみようということで試しました。
▼ちゃんと日本語で表示されています。
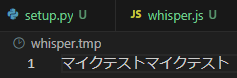
このファイルを読み込めば、文字化けせずにNode-REDで表示することができました。
最後に
tinyだと処理が速いとはいえ、3秒ぐらいかかってしまうようですね。リアルタイム性が求められる処理では工夫する必要がありそうです。
▼More examplesということで、Discussionのページが挙げられていました。ここで探すと、参考になるものがあるかもしれません。
https://github.com/openai/whisper/discussions/categories/show-and-tell
▼探していると、リアルタイムでの文字起こしに関する記事がありました。
▼QiitaにWhisperを高速化したという記事がありました!処理を速くするための工夫がされています。
https://qiita.com/halhorn/items/d2672eee452ba5eb6241
ローカルで実行する場合はマシンのスペックに依存するのも難点ですね。そう考えると、OpenAIが提供しているAPIの利用料を払う価値は十分にあると感じます。
大体の使い方は分かったので、後でNode-RED用のノードを作ろうかなと考えています。
▼すでに形にはなっているのですが、オプションをどうしようかなと考えているところです。