Style-Bert-VITS2を使ってみる(Text to Speech、Node-RED)
はじめに
今回はStyle-Bert-VITS2を使ったText to Speech (TTS)を試してみました。
TTS系のソフトウェアで、日本語に対応していて高速なものを探していたのですが、知り合いの方からStyle-Bert-VITS2を使っていると聞きました。規約を守れば商用非商用問わず利用できるという点もありがたいです。
▼開発陣からのお願いとデフォルトモデルの利用規約がありました。利用する前に一読ください。
https://github.com/litagin02/Style-Bert-VITS2/blob/master/docs/TERMS_OF_USE.md
この記事では生成した音声ファイルにクレジットを表記しています。
▼以前の記事はこちら
Node-REDとVOICEVOX COREで音声合成(Python)
はじめに 今回はNode-REDとVOICEVOX COREで日本語の音声合成を試してみました。 Node-REDで実行できるようになると、HTTP通信やMQTT通信、音声再生など、他のノードと…
PythonでgTTSを使ってみる(音声合成、Node-RED)
はじめに 今回はPythonでgTTS(Google Text-to-Speech)を使ってみました。 以前VoiceVoxも使ったことがあるのですが、英語も話すことができて、ローカル環境での音声の…
関連情報
▼GitHubのリポジトリはこちら
https://github.com/litagin02/Style-Bert-VITS2
▼解説チュートリアル動画はこちら
▼READMEに書かれていたZennの記事はこちら。Bert-VITS2 JP-ExtraというBert-VITS2の日本語に特化したものがあって、さらに改良したものだそうです。
https://zenn.dev/litagin/articles/034819a5256ff4
▼オンラインデモのページがありました。私が試したときは実行できない?ようでした。
https://huggingface.co/spaces/litagin/Style-Bert-VITS2-Editor-Demo
▼デモでは話し方や感情を選択できるようになっていました。
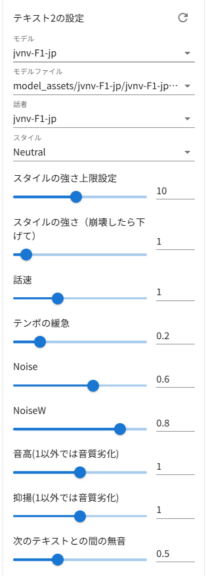
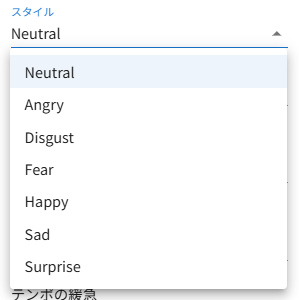
環境を構築する
READMEからGoogle Colaboratoryに移動できるので、そちらの方が簡単に実行できるかもしれません。今回は利用しません。
▼以下にGoogle Colaboratoryで実行できるNotebookのサンプルがありました。
https://github.com/litagin02/Style-Bert-VITS2/blob/master/library.ipynb
▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


まずはPythonの仮想環境を作成します。
py -3.10 -m venv pyenv-style-bert-vits2
cd .\pyenv-style-bert-vits2
.\Scripts\activate▼Pythonの仮想環境の作成については、以下の記事にまとめています。
Pythonの仮想環境を作成する(venv、Windows)
はじめに 今回はPythonの仮想環境の作成についてまとめてみました。 Pythonを利用したNode-REDのノードを開発するときに仮想環境を詳しく調べていました。作成した仮…

style-bert-vits2をpipでインストールします。
pip install style-bert-vits2READMEの内容をもとに他に必要なものをインストールするのですが、以下のコマンドは私の環境に合わせています。
git clone https://github.com/litagin02/Style-Bert-VITS2.git
cd Style-Bert-VITS2
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126
pip install -r requirements.txt
python initialize.py▼YOLOをGPUで実行するときにもtorch関連のパッケージをインストールしていたのですが、私はCUDA 12.6を利用しています。
YOLOで物体検出 その4(GPUの設定、CUDA 12.6)
はじめに 今回はGPUを利用したYOLOの物体検出を試してみました。 Ultralyticsのドキュメントではオプションで切り替えることができるようでしたが、GPUだとエラーが出…
エディタを利用する
以下のコマンドでエディタを起動しました。
python server_editor.py --inbrowser▼ブラウザが起動し、最初にお願いとモデルの利用規約が表示されました。
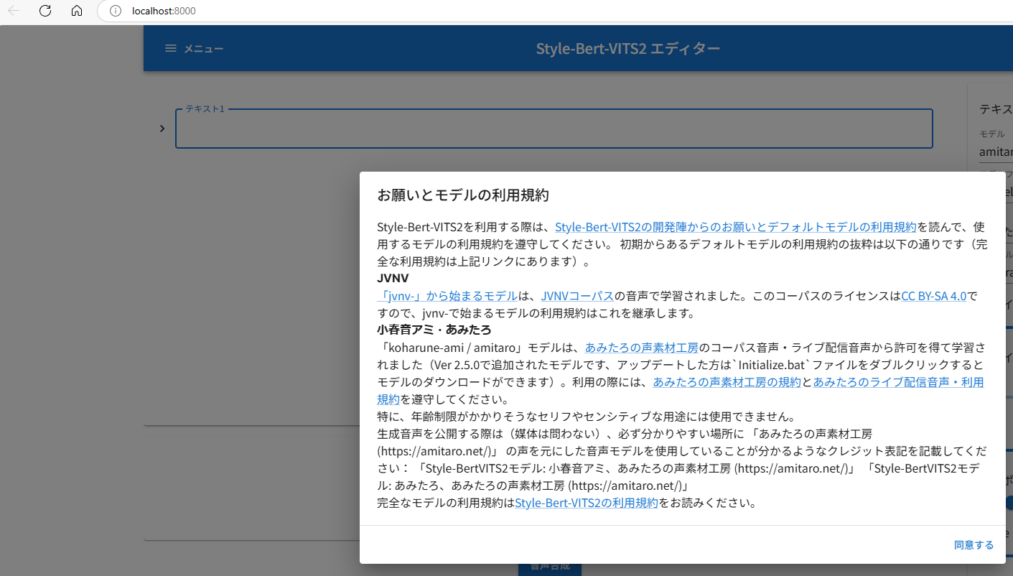
▼以下の画面が表示されました。オンラインデモと同じ画面ですね。
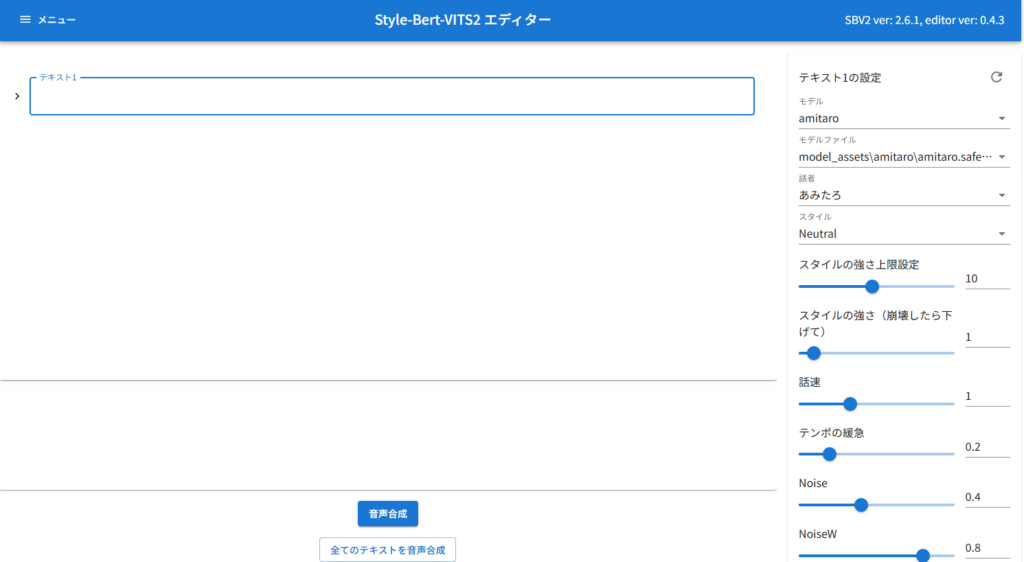
まずはこんにちはというテキストで音声合成を行いました。
▼少し時間が経って、音声ファイルが生成されました。
▼ダウンロードした音声ファイルはこちら
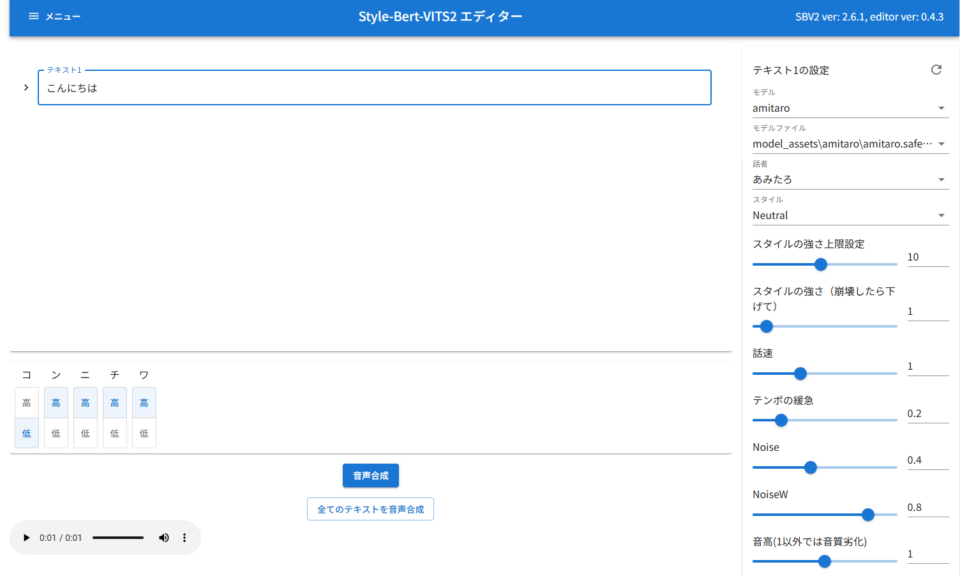
テキストを追加してみました。
▼テキスト1にカーソルを持って行くと、右側に行を追加するボタンが表示されました。

▼3秒ぐらいで音声ファイルが生成されました。
初回だけ音声合成に少し時間がかかっていた印象です。
▼さすがに英語はカタカナなどに変換する必要がありそうです。
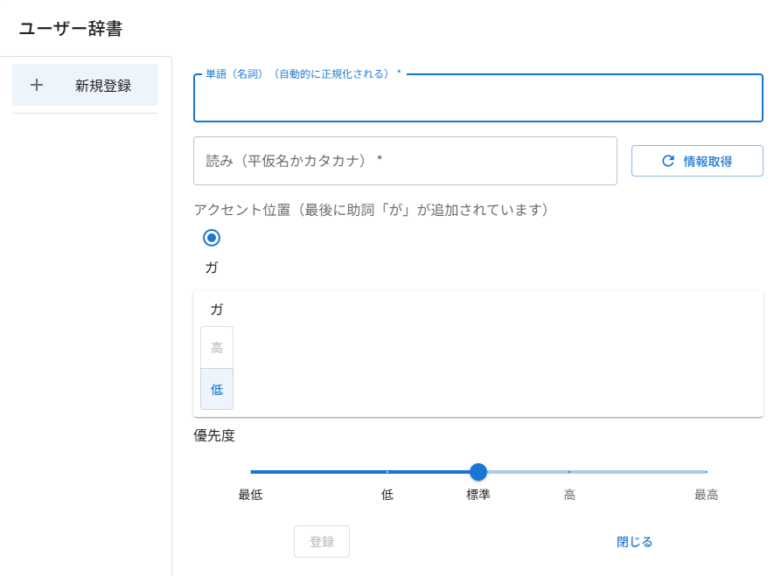
▼左上に、ユーザー辞書の編集がありました。
▼うまく使えば、ある程度補正できそうです。
Node-REDと通信する
Node-REDと通信して音声ファイルを生成できれば、他の処理にもつなげることができます。APIサーバーを起動して、通信してみました。
以下のコマンドでAPIサーバーを起動します。
python server_fastapi.py起動後、http://127.0.0.1:5000/docにアクセスすると、FastAPIのページが開きました。
▼Web系の開発でちょっとだけ見たことがある画面です。
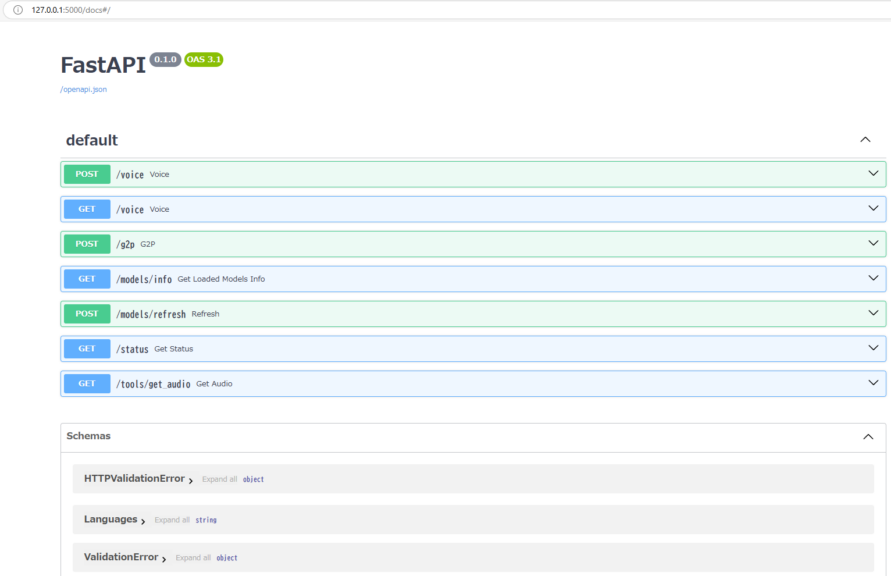
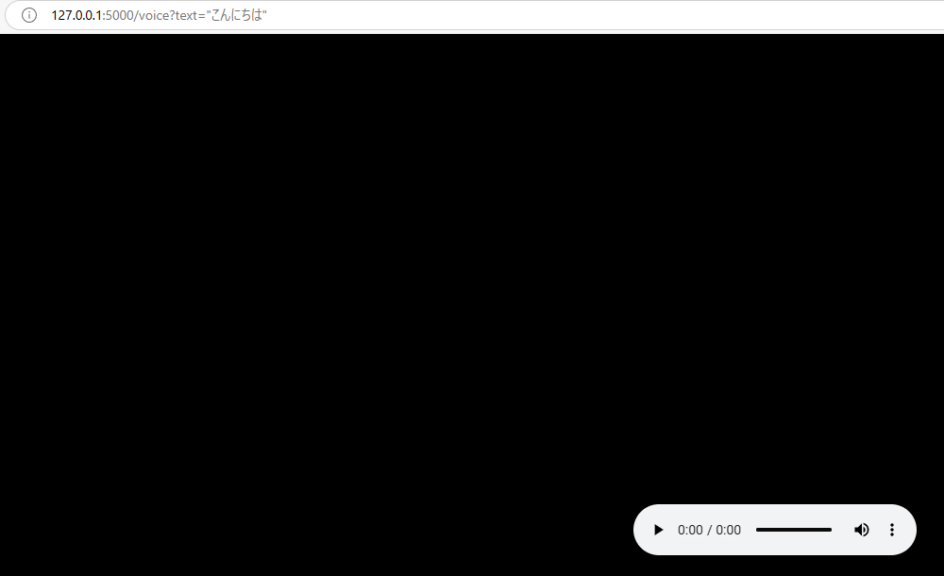
この画面の見方がよく分かっていないのですが、クエリ文字列でテキストを送信すればできそうな気がしたので送ってみました。
▼音声ファイルがブラウザに表示されました!
▼FastAPIの画面でこんにちはと入力してExecuteすると、音声ファイルが生成されていました。Request URLを見ると間違っていなかったようです。
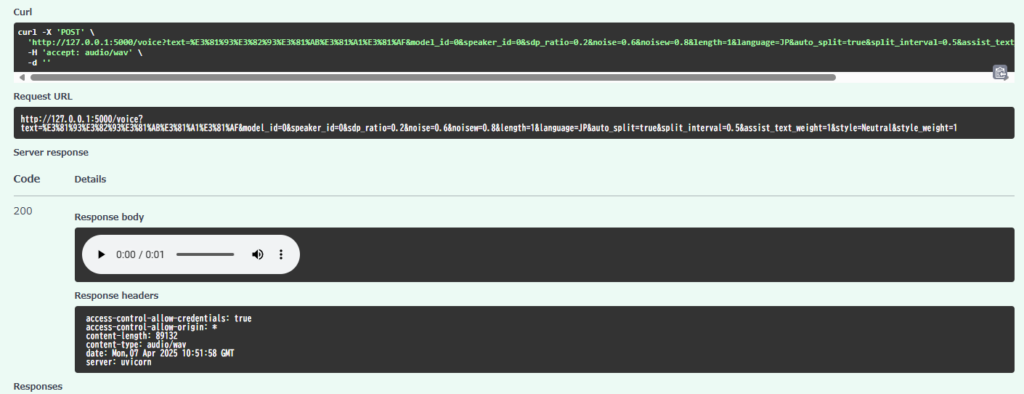
▼初回で若干音声合成が遅かったのは、モデルの読み込みがあったからではないかと思います。

同じような要領で、Node-REDからもHTTP通信でリクエストを送信します。
▼まずは以下のフローを試してみました。http requestノードはPOSTリクエストにしています。

▼templateノードでmsg.payloadの値をクエリ文字列として渡すようにしています。この値は、msg.urlに代入されます。
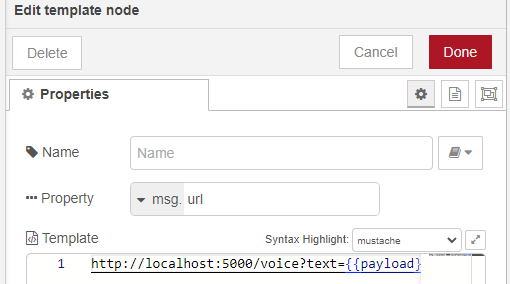
実行してみると、WAVEファイルの中身がデバッグウィンドウに表示されました。
▼以下のように表示されました。

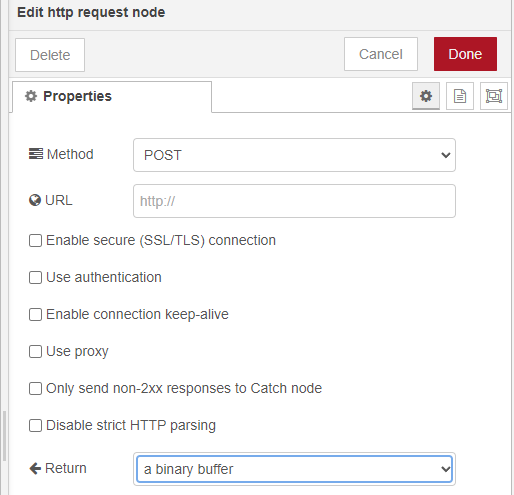
http requestノードの出力をバイナリバッファにして、ファイルに保存しました。
▼以下のフローを作成しました。

[{"id":"3ab94dfe45000684","type":"comment","z":"22eb2b8f4786695c","name":"Style-Bert-VITS2","info":"","x":340,"y":1200,"wires":[]},{"id":"7cf5fa8d1a176c75","type":"http request","z":"22eb2b8f4786695c","name":"","method":"POST","ret":"bin","paytoqs":"ignore","url":"","tls":"","persist":false,"proxy":"","insecureHTTPParser":false,"authType":"","senderr":false,"headers":[],"x":810,"y":1240,"wires":[["97ea907b8a593f01","2ccbc67b0c5b3118"]]},{"id":"aa4edf2aa1cfdc34","type":"inject","z":"22eb2b8f4786695c","name":"","props":[{"p":"payload"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","payload":"ノードレッドから送信しています。","payloadType":"str","x":400,"y":1240,"wires":[["76731735609d3223"]]},{"id":"97ea907b8a593f01","type":"debug","z":"22eb2b8f4786695c","name":"debug 533","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":990,"y":1240,"wires":[]},{"id":"76731735609d3223","type":"template","z":"22eb2b8f4786695c","name":"","field":"url","fieldType":"msg","format":"handlebars","syntax":"mustache","template":"http://localhost:5000/voice?text={{payload}}","output":"str","x":640,"y":1240,"wires":[["7cf5fa8d1a176c75"]]},{"id":"2ccbc67b0c5b3118","type":"file","z":"22eb2b8f4786695c","name":"","filename":"generate.wav","filenameType":"str","appendNewline":true,"createDir":false,"overwriteFile":"true","encoding":"none","x":640,"y":1300,"wires":[["944d633049bc3e05"]]},{"id":"944d633049bc3e05","type":"debug","z":"22eb2b8f4786695c","name":"debug 534","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":830,"y":1300,"wires":[]}]▼http requestノードは出力をバイナリバッファに変更しています。
▼write fileノードはファイル名と上書き保存する設定だけ変更しました。
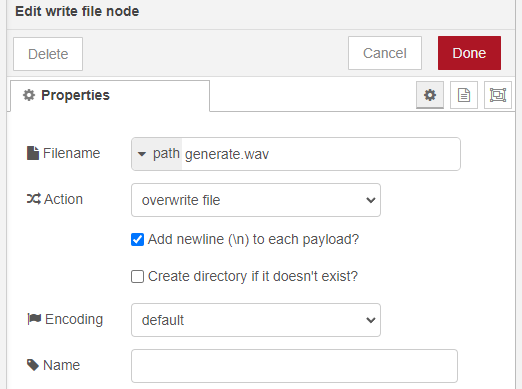
この状態で実行してみました。
▼以下の音声が生成されて、ファイルに保存されました。
さらに音声認識や音声を再生できるノード、ローカルLLMと組み合わせると、AIとの会話が簡単にできそうです。
最後に
軽量かつ簡単に使えそうなので、今後利用していこうと思っています。PCのスペックにもよるとは思いますが、Voicevox Coreよりも速いという印象です。
データセットづくりや学習についてもやってみたいところです。
これ以上速度を求める用途であれば、外部APIを利用することも検討すべきなのだろうなと思っています。できればお金をかけたくないので、ずっと避けているのですが...