Node-REDとVOICEVOX COREで音声合成(Python)
はじめに
今回はNode-REDとVOICEVOX COREで日本語の音声合成を試してみました。
Node-REDで実行できるようになると、HTTP通信やMQTT通信、音声再生など、他のノードとも一緒に使うことができそうです。
Node-REDのノードがまだ無いようだったので、後で作ろうかなと思っています。
▼VOICEVOX COREのリポジトリはこちら
https://github.com/VOICEVOX/voicevox_core
▼以前の記事はこちら
PythonでVOICEVOX COREを使ってみる(音声合成)
はじめに 以前の記事でGoogle Cloud Platformの音声合成・音声認識を試したのですが、利用回数が多いとお金がかかります。やっぱり無料で実行したいということで、今回…

環境の構築
ps1ファイルの実行
以前の記事では、VOICEVOX COREのバージョン0.14.5を使っていました。そろそろ新しいバージョンになりそうだなと思っていたら、ちょうど0.15.0がリリースされたようですね。今回は引き続き0.14.5を使います。
Windowsの環境で実行するのですが、環境構築用にps1ファイルを作成してみました。Power Shellで実行すると、必要なものがインストールされると思います。
▼ファイル構成はこちら。voiceフォルダに生成した音声ファイルを入れます。
▼こちらのプログラムをwinフォルダに入れます。
New-Item voicevox -ItemType Directory
Set-Location voicevox
Invoke-WebRequest https://github.com/VOICEVOX/voicevox_core/releases/latest/download/download-windows-x64.exe -OutFile ./download.exe
.\download.exe
pip install https://github.com/VOICEVOX/voicevox_core/releases/download/0.14.5/voicevox_core-0.14.5+cpu-cp38-abi3-win_amd64.whl
Copy-Item .\voicevox_core\onnxruntime.dll ..\
Remove-Item .\download.exe
Set-Location ..
▼コマンドはこちら。winフォルダがあるディレクトリで実行してください。
.\win\voicevox.ps1
▼実行後のファイル構成はこちら。
Pythonで実行
以前の記事の時点で、引数に文字列を渡すと音声ファイルを出力するように、Pythonでプログラムしました。
▼今回のファイル構成でのプログラムはこちら。
from pathlib import Path
from voicevox_core import VoicevoxCore, METAS
import sys, os
core = VoicevoxCore(open_jtalk_dict_dir=Path("./voicevox/voicevox_core/open_jtalk_dic_utf_8-1.11"))
speaker_id = 2
text = sys.argv[1]
if not core.is_model_loaded(speaker_id):
core.load_model(speaker_id)
wave_bytes = core.tts(text, speaker_id)
with open("./voice/" + text + ".wav", "wb") as f:
f.write(wave_bytes)
▼以下のコマンドを実行すると、音声ファイルが出力されます。
python .\voicevox.py こんにちは
▼ファイルが出力されました!プログラムでのspeaker_idは2なので、「四国めたん」さんのノーマル音声になります。
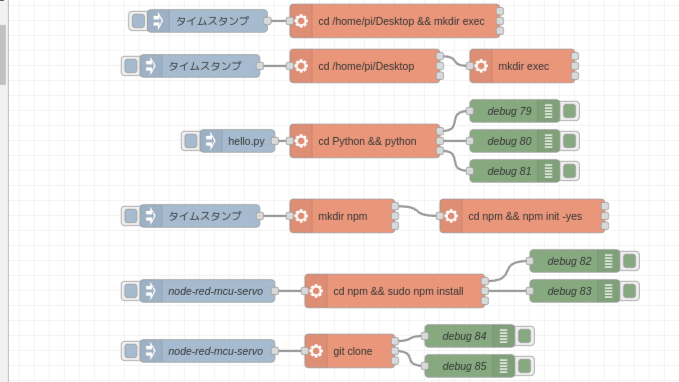
execノードで実行してみる
先程のプログラムを、execノードで実行します。
▼execノードについては、以前の記事でも使いました。コマンドを実行できるので、Pythonのプログラムも実行できます。
Node-REDを使ってみる その1(execノード、Pythonプログラム実行)
はじめに 今回はNode-REDのexecノードを使ってみました。コマンドを実行できるノードです。 私はNode-RED MCUを先に使い始めたので、Node-RED自体はあまり使っていま…
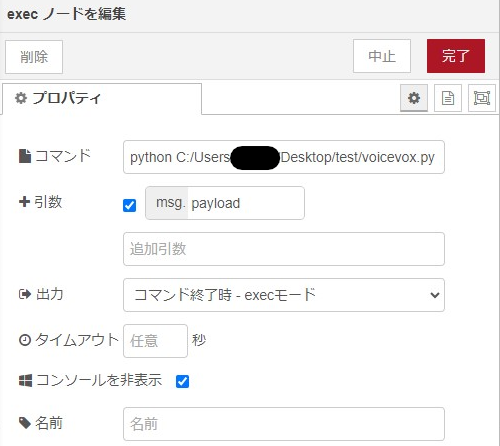
相対パスで指定していましたが、Node-REDの環境によってはどこに生成されるのか分からなくなります。絶対パスに変更しておくことをお勧めします。
▼私はDesktopにtestフォルダを作成して、そこに全部入れました。適宜変更してください。
from pathlib import Path
from voicevox_core import VoicevoxCore, METAS
import sys, os
core = VoicevoxCore(open_jtalk_dict_dir=Path("C:/Users/<ユーザー名>/Desktop/test/voicevox/voicevox_core/open_jtalk_dic_utf_8-1.11"))
speaker_id = 2
text = sys.argv[1]
if not core.is_model_loaded(speaker_id):
core.load_model(speaker_id)
wave_bytes = core.tts(text, speaker_id)
with open("C:/Users/<ユーザー名>/Desktop/test/voice/" + text + ".wav", "wb") as f:
f.write(wave_bytes)
▼フローはこちら。

▼msg.payloadを引数に渡して実行します。
▼実際に出力された音声ファイルはこちら
▼msg.payloadで文字列を渡すだけなので、他の通信ノードとも使うことができそうですね。

play audioノードで再生してみる
出力されたwavファイルを、ノードで再生してみます。
▼こちらのノードをインストールしました。
https://flows.nodered.org/node/node-red-contrib-play-audio
▼ヘルプはこちら
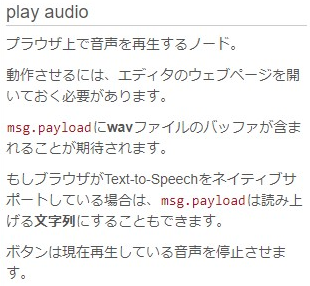
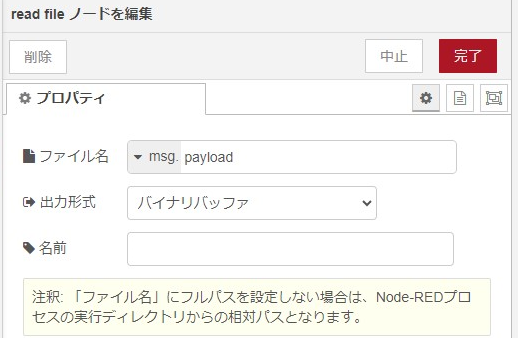
msg.payloadにwavファイルのバッファを渡して再生するようです。read fileノードでファイルを開き、バイナリバッファでplay audioノードに渡します。
ちなみに、このノード自体も文字列を渡すと音声を読み上げます。
▼Microsoft系のTTSボイスですね。
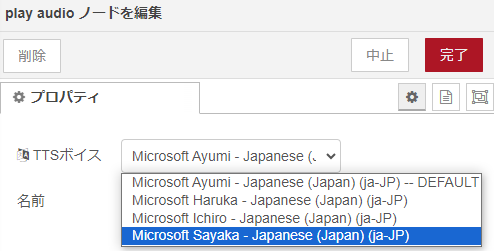
templateノードでファイルのパスをread fileノードに渡し、バイナリバッファをplay audioに渡します。
▼フローはこちら

▼templateノードの中身はこちら。{{payload}}には文字列が入り、msg.payloadが音声ファイルの絶対パスになります。
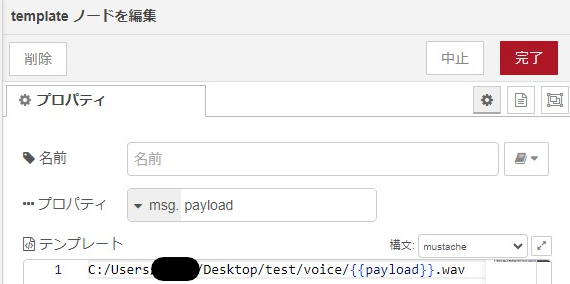
▼read fileノードの中身はこちら。出力形式はバイナリバッファです。
▼再生されました!

最後に
Node-REDでVOICEVOX COREを使ったプログラムを呼び出して、日本語の音声合成ができました。ここまで来ると、新しいノードにまとめたいところですね。Pythonのライブラリをインストールしないといけないので、その辺りをどうしようかなと思っているところです。
プログラムによって変わるのかもしれませんが、実行してから音声ファイルが出力されるまで、5秒ぐらいかかりました。文字数にもよると思います。
その点、play audioのTTSボイスはすぐに出力されました。でも少し前のカーナビみたいな音声で、VOICEVOXの方が自然という印象です。
用途によって使い分けてもいいのかもしれませんね。音声ファイルを出力しておけば、再生するのはすぐにできました。
▼リアルタイム性については、こちらの記事でも触れられていました。やはり別の端末で実行して、結果を返してもらうのが良さそうですね。
RaspberryPiの音声合成にリアルタイム性を求めるには?VOICEVOX Engineの活用 - uepon日々の備忘録
以前はVOICEVOX CORE(コアライブラリ)をRaspberryPiへインストールして音声合成を試してみたのですが、合成されるまでにかなりに時間がかかってしまうため、リアルタイ…