Pythonで論文を収集する その1(arXiv、Node-RED)
はじめに
今回はarXiv APIを使って、Pythonで論文を収集してみました。
普段は論文を検索するときにGoogle Scholarを使っていたのですが、プログラムで自動化したかったのでChatGPTに相談してみたところ、arXivのパッケージがあることを知りました。
Pythonでサンプルプログラムを確認後、Node-REDで実行できるようにしています。
▼以前の記事はこちら
Ollamaを使ってみる その1(Gemma2、Node-RED)
はじめに 今回はローカル環境でLLMを利用できるOllamaを使ってみました。様々な言語モデルをインストールして、文章を生成することができます。 これまで音声の文字起…
PythonでgTTSを使ってみる(音声合成、Node-RED)
はじめに 今回はPythonでgTTS(Google Text-to-Speech)を使ってみました。 以前VoiceVoxも使ったことがあるのですが、英語も話すことができて、ローカル環境での音声の…
関連情報
▼arXivのページはこちら。論文を検索するときによく見ています。HTML形式でも表示できるときは、Google翻訳がブラウザ上で使えて便利です。
▼PyPIでのarXivのページはこちら
https://pypi.org/project/arxiv
▼パッケージの利用方法については、こちらのページに詳しくまとめられていました。
https://note.nkmk.me/python-arxiv-api-download-rss
arXivパッケージを利用する
環境を構築する
実行環境はWindows 11のノートPC、Pythonのバージョンは3.12.6です。
まずはPythonの仮想環境を作成して、パッケージをインストールします。以下のコマンドを実行しました。
python -m venv pyenv
cd pyenv
.\Scripts\activate
pip install arxiv▼Pythonの仮想環境について、詳しくは以下の記事をご覧ください。
Pythonの仮想環境を作成する(venv、Windows)
はじめに 今回はPythonの仮想環境の作成についてまとめてみました。 Pythonを利用したNode-REDのノードを開発するときに仮想環境を詳しく調べていました。作成した仮…

サンプルプログラムを試してみる
PyPIのページにあったサンプルプログラムを試してみました。
# https://pypi.org/project/arxiv/
import arxiv
# Construct the default API client.
client = arxiv.Client()
# Search for the 10 most recent articles matching the keyword "quantum."
search = arxiv.Search(
query = "quantum",
max_results = 10,
sort_by = arxiv.SortCriterion.SubmittedDate
)
results = client.results(search)
# `results` is a generator; you can iterate over its elements one by one...
for r in client.results(search):
print(r.title)
# ...or exhaust it into a list. Careful: this is slow for large results sets.
all_results = list(results)
print([r.title for r in all_results])
# For advanced query syntax documentation, see the arXiv API User Manual:
# https://arxiv.org/help/api/user-manual#query_details
search = arxiv.Search(query = "au:del_maestro AND ti:checkerboard")
first_result = next(client.results(search))
print(first_result)
# Search for the paper with ID "1605.08386v1"
search_by_id = arxiv.Search(id_list=["1605.08386v1"])
# Reuse client to fetch the paper, then print its title.
first_result = next(client.results(search))
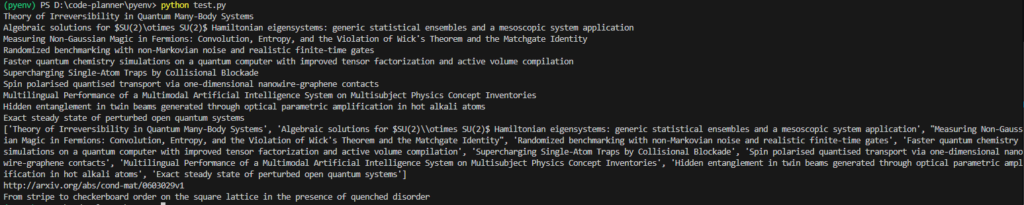
print(first_result.title)▼以下のように出力されました。
▼少しだけまとめると以下のようになっています。
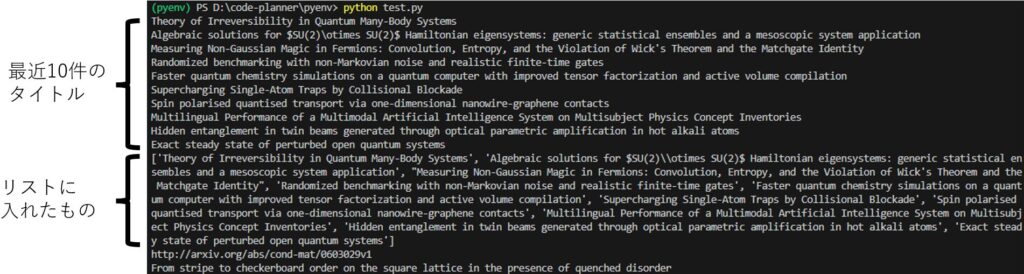
最後から2つ目はANDを使った検索、最後はIDでの検索になっています。
▼詳細は以下のユーザーマニュアルに書かれていました。
https://info.arxiv.org/help/api/user-manual.html#query_details
pdfファイルをダウンロードする以下のサンプルプログラムも試してみました。
# https://pypi.org/project/arxiv/
import arxiv
paper = next(arxiv.Client().results(arxiv.Search(id_list=["1605.08386v1"])))
# Download the PDF to the PWD with a default filename.
paper.download_pdf()
# Download the PDF to the PWD with a custom filename.
paper.download_pdf(filename="downloaded-paper.pdf")
# Download the PDF to a specified directory with a custom filename.
paper.download_pdf(dirpath="./mydir", filename="downloaded-paper.pdf")なお、最後の行でディレクトリを指定していますが、mydirフォルダが無いとFileNotFoundErrorが出ていました。
▼実行後、pdfファイルがダウンロードされていました。元の名前、指定した名前、指定したフォルダで3つダウンロードされています。
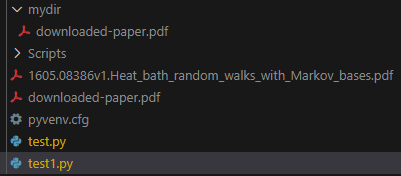
カスタムクライアントで結果を取得するサンプルプログラムも試したのですが、数が多すぎたので番号も表示するようにしてみました。
# https://pypi.org/project/arxiv/
import arxiv
i = 0
big_slow_client = arxiv.Client(
page_size = 1000,
delay_seconds = 10.0,
num_retries = 5
)
# Prints 1000 titles before needing to make another request.
for result in big_slow_client.results(arxiv.Search(query="quantum")):
print(result.title)
i+=1
print(i)▼時間を空けて1000件ずつ表示されました。

1回目の表示だけ100件や200件のこともありました。その後は1000件ずつ表示されました。
Node-REDで利用する
injectノードで実行する
私が開発したpython-venvノードを使って、Node-REDでPythonを実行しました。
▼年末に開発の変遷を書きました。
https://qiita.com/background/items/d2e05e8d85427761a609
Pythonを実行するためのフローを作成しました。pipノードでarxivをインストールできます。
▼フローはこちら。ダウンロード先のフォルダはinjectノードで設定しているので、変更してください。
[{"id":"56d78acd29b819e8","type":"venv","z":"711edbe9464cba2a","venvconfig":"2fd1a793b1bee0bb","name":"Download","code":"import arxiv\nimport os\nimport time\nfrom datetime import datetime\n\n\ndef download_papers(paper_dir, query, wait_time=60, year_limit=2023):\n \"\"\"\n 論文を検索し、PDFをダウンロードします。\n\n Parameters:\n - paper_dir (str): 保存先フォルダ\n - query (str): 検索クエリ(複数のキーワードを空白区切りで指定)\n - wait_time (int): ダウンロード間隔(秒)\n - year_limit (int): ダウンロード対象とする論文の最小年(それ以前の論文はダウンロードしない)\n \"\"\"\n # 保存先ディレクトリを作成\n os.makedirs(paper_dir, exist_ok=True)\n print(f\"Saving papers to: {paper_dir}\")\n\n # arXivクライアントの設定\n client = arxiv.Client(page_size=10)\n\n print(f\"Searching for papers with query: '{query}'...\")\n\n # クエリを空白区切りでAND検索として扱う\n formatted_query = \" AND \".join(query.split())\n\n # クエリを実行して結果を取得\n search = arxiv.Search(\n query=formatted_query,\n sort_by=arxiv.SortCriterion.SubmittedDate\n )\n\n for result in client.results(search):\n try:\n # タイトルと提出日\n print(f\"\\nTitle: {result.title}\")\n # print(f\"Submitted: {result.updated}\")\n # print(f\"Abstract: {result.summary}\")\n\n # 提出日が指定された年よりも前かどうかを確認\n submitted_year = result.updated.year # ここで直接年を取得\n if submitted_year < year_limit:\n print(f\"Skipping {result.title} as it was submitted in {submitted_year}, which is before {year_limit}.\")\n break # 指定年より前の論文が見つかった時点で終了\n\n # ファイル名を適切にフォーマット\n sanitized_title = \"\".join(c if c.isalnum() or c in \" _-\" else \"_\" for c in result.title)\n pdf_filename = f\"{sanitized_title}.pdf\"\n pdf_paper_path = os.path.join(paper_dir, pdf_filename)\n\n # PDFが既に存在する場合はダウンロードしない\n if os.path.exists(pdf_paper_path):\n print(f\"{pdf_filename} already exists. Skipping download.\")\n continue\n\n # PDFダウンロード\n # print(f\"Downloading to: {pdf_paper_path}\")\n result.download_pdf(dirpath=paper_dir, filename=pdf_filename)\n\n time.sleep(wait_time)\n\n except Exception as e:\n print(f\"Failed to process {result.title}: {e}\")\n\n print(\"\\nDone!\")\n\n# Node-REDからの入力\nif __name__ == \"__main__\":\n # 保存先フォルダ\n paper_dir = os.path.join(msg['directory'].replace(\"\\\\\", \"/\"), 'paper')\n\n # 検索ワード\n query = msg['query']\n\n # ダウンロード間隔を設定(デフォルト60秒)\n wait_time = 10 # 固定値\n\n # ダウンロード対象とする最小年(例:2023年以降の論文)\n year_limit = 2020\n\n # 論文のダウンロード\n download_papers(paper_dir, query, wait_time, year_limit)","continuous":true,"x":1280,"y":840,"wires":[["e87751155b621fb6"]]},{"id":"8bd7561f59804d05","type":"inject","z":"711edbe9464cba2a","name":"W","props":[{"p":"directory","v":"W:\\論文","vt":"str"},{"p":"query","v":"ROS Unreal Engine","vt":"str"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":1130,"y":840,"wires":[["56d78acd29b819e8"]]},{"id":"e87751155b621fb6","type":"debug","z":"711edbe9464cba2a","name":"debug 355","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":1450,"y":840,"wires":[]},{"id":"64af3d1520034da0","type":"inject","z":"711edbe9464cba2a","name":"","props":[],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":1130,"y":780,"wires":[["82e599ee0edab80a"]]},{"id":"82e599ee0edab80a","type":"pip","z":"711edbe9464cba2a","venvconfig":"2fd1a793b1bee0bb","name":"","arg":"arxiv","action":"install","tail":false,"x":1270,"y":780,"wires":[["236bfae326175264"]]},{"id":"236bfae326175264","type":"debug","z":"711edbe9464cba2a","name":"debug 358","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":1430,"y":780,"wires":[]},{"id":"2fd1a793b1bee0bb","type":"venv-config","venvname":"paper","version":"3.10"}]実行するPythonのコードはChatGPTに書いてもらいました。
import arxiv
import os
import time
from datetime import datetime
def download_papers(paper_dir, query, wait_time=60, year_limit=2023):
"""
論文を検索し、PDFをダウンロードします。
Parameters:
- paper_dir (str): 保存先フォルダ
- query (str): 検索クエリ(複数のキーワードを空白区切りで指定)
- wait_time (int): ダウンロード間隔(秒)
- year_limit (int): ダウンロード対象とする論文の最小年(それ以前の論文はダウンロードしない)
"""
# 保存先ディレクトリを作成
os.makedirs(paper_dir, exist_ok=True)
print(f"Saving papers to: {paper_dir}")
# arXivクライアントの設定
client = arxiv.Client(page_size=10)
print(f"Searching for papers with query: '{query}'...")
# クエリを空白区切りでAND検索として扱う
formatted_query = " AND ".join(query.split())
# クエリを実行して結果を取得
search = arxiv.Search(
query=formatted_query,
sort_by=arxiv.SortCriterion.SubmittedDate
)
for result in client.results(search):
try:
# タイトルと提出日
print(f"\nTitle: {result.title}")
# print(f"Submitted: {result.updated}")
# print(f"Abstract: {result.summary}")
# 提出日が指定された年よりも前かどうかを確認
submitted_year = result.updated.year # ここで直接年を取得
if submitted_year < year_limit:
print(f"Skipping {result.title} as it was submitted in {submitted_year}, which is before {year_limit}.")
break # 指定年より前の論文が見つかった時点で終了
# ファイル名を適切にフォーマット
sanitized_title = "".join(c if c.isalnum() or c in " _-" else "_" for c in result.title)
pdf_filename = f"{sanitized_title}.pdf"
pdf_paper_path = os.path.join(paper_dir, pdf_filename)
# PDFが既に存在する場合はダウンロードしない
if os.path.exists(pdf_paper_path):
print(f"{pdf_filename} already exists. Skipping download.")
continue
# PDFダウンロード
# print(f"Downloading to: {pdf_paper_path}")
result.download_pdf(dirpath=paper_dir, filename=pdf_filename)
time.sleep(wait_time)
except Exception as e:
print(f"Failed to process {result.title}: {e}")
print("\nDone!")
# Node-REDからの入力
if __name__ == "__main__":
# 保存先フォルダ
paper_dir = os.path.join(msg['directory'].replace("\\", "/"), 'paper')
# 検索ワード
query = msg['query']
# ダウンロード間隔を設定(デフォルト10秒)
wait_time = 10 # 固定値
# ダウンロード対象とする最小年(例:2023年以降の論文)
year_limit = 2020
# 論文のダウンロード
download_papers(paper_dir, query, wait_time, year_limit)Pythonのコードでは定義されていないmsg['directory']とmsg['query']がありますが、これはNode-REDのmsgオブジェクトにアクセスしているからです。Node-REDでPythonを実行するうえで便利な機能として、Contributorの方が実装してくれました。
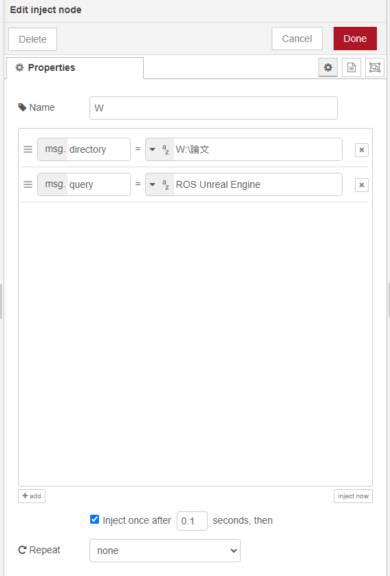
▼injectノードで以下のように指定しています。
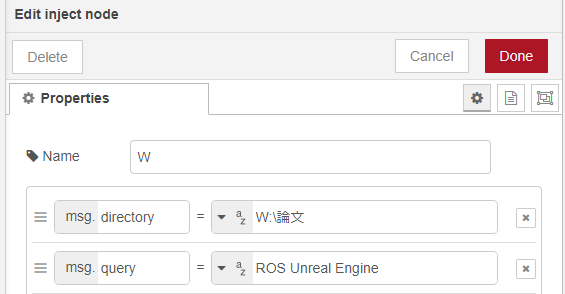
msg.directoryで指定したフォルダの、paperフォルダにpdfファイルがダウンロードされます。
実際に実行してみました。
▼論文のpdfがダウンロードされました!
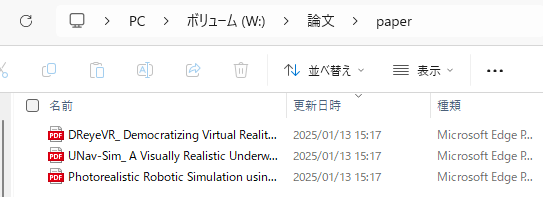
▼ダウンロード済みの場合はスキップしています。
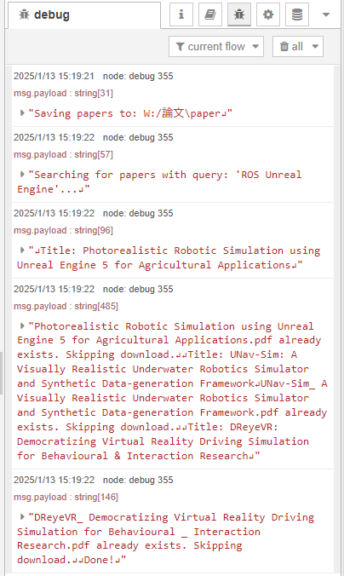
dashboardノードと組み合わせる
年末年始にpython-venvノードをアップデートして、msgオブジェクトだけでなくflowオブジェクトやglobalオブジェクトにもアクセスできるようになりました。
この機能を使って、dashboardノードのtext inputノードでクエリとディレクトリを入力し、pdfファイルをダウンロードするようにしました。
▼全体のフローはこちら。ダッシュボードで入力した検索キーワードは、flowオブジェクトに代入しています。

[{"id":"60da293526020a2c","type":"venv","z":"711edbe9464cba2a","venvconfig":"2fd1a793b1bee0bb","name":"Download","code":"import arxiv\nimport os\nimport time\nfrom datetime import datetime\n\n\ndef download_papers(paper_dir, query, wait_time=60, year_limit=2023):\n \"\"\"\n 論文を検索し、PDFをダウンロードします。\n\n Parameters:\n - paper_dir (str): 保存先フォルダ\n - query (str): 検索クエリ(複数のキーワードを空白区切りで指定)\n - wait_time (int): ダウンロード間隔(秒)\n - year_limit (int): ダウンロード対象とする論文の最小年(それ以前の論文はダウンロードしない)\n \"\"\"\n # 保存先ディレクトリを作成\n os.makedirs(paper_dir, exist_ok=True)\n print(f\"Saving papers to: {paper_dir}\")\n\n # arXivクライアントの設定\n client = arxiv.Client(page_size=10)\n\n print(f\"Searching for papers with query: '{query}'...\")\n\n # クエリを空白区切りでAND検索として扱う\n formatted_query = \" AND \".join(query.split())\n\n # クエリを実行して結果を取得\n search = arxiv.Search(\n query=formatted_query,\n sort_by=arxiv.SortCriterion.SubmittedDate\n )\n\n for result in client.results(search):\n try:\n # タイトルと提出日\n print(f\"\\nTitle: {result.title}\")\n # print(f\"Submitted: {result.updated}\")\n # print(f\"Abstract: {result.summary}\")\n\n # 提出日が指定された年よりも前かどうかを確認\n submitted_year = result.updated.year # ここで直接年を取得\n if submitted_year < year_limit:\n print(f\"Skipping {result.title} as it was submitted in {submitted_year}, which is before {year_limit}.\")\n break # 指定年より前の論文が見つかった時点で終了\n\n # ファイル名を適切にフォーマット\n sanitized_title = \"\".join(c if c.isalnum() or c in \" _-\" else \"_\" for c in result.title)\n pdf_filename = f\"{sanitized_title}.pdf\"\n pdf_paper_path = os.path.join(paper_dir, pdf_filename)\n\n # PDFが既に存在する場合はダウンロードしない\n if os.path.exists(pdf_paper_path):\n print(f\"{pdf_filename} already exists. Skipping download.\")\n continue\n\n # PDFダウンロード\n # print(f\"Downloading to: {pdf_paper_path}\")\n result.download_pdf(dirpath=paper_dir, filename=pdf_filename)\n\n time.sleep(wait_time)\n\n except Exception as e:\n print(f\"Failed to process {result.title}: {e}\")\n\n print(\"\\nDone!\")\n\n# Node-REDからの入力\nif __name__ == \"__main__\":\n # 保存先フォルダ\n paper_dir = os.path.join(node['flow']['directory'].replace(\"\\\\\", \"/\"), 'paper')\n\n # 検索ワード\n query = node['flow']['query']\n\n # ダウンロード間隔を設定(デフォルト60秒)\n wait_time = 10 # 固定値\n\n # ダウンロード対象とする最小年(例:2023年以降の論文)\n year_limit = 2020\n\n # 論文のダウンロード\n download_papers(paper_dir, query, wait_time, year_limit)","continuous":true,"x":1400,"y":580,"wires":[["991894f0041bde39"]]},{"id":"991894f0041bde39","type":"debug","z":"711edbe9464cba2a","name":"debug 355","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":1570,"y":580,"wires":[]},{"id":"17a39cba18b56f4a","type":"ui_text_input","z":"711edbe9464cba2a","name":"","label":"Query","tooltip":"","group":"3c0113e44b7c7681","order":2,"width":0,"height":0,"passthru":true,"mode":"text","delay":"0","topic":"topic","sendOnBlur":true,"className":"","topicType":"msg","x":1210,"y":500,"wires":[["5e8f6e1392be952c"]]},{"id":"5e8f6e1392be952c","type":"change","z":"711edbe9464cba2a","name":"","rules":[{"t":"set","p":"query","pt":"flow","to":"payload","tot":"msg"}],"action":"","property":"","from":"","to":"","reg":false,"x":1380,"y":500,"wires":[[]]},{"id":"09dbdd1d30623cf4","type":"ui_text_input","z":"711edbe9464cba2a","name":"","label":"Directory","tooltip":"","group":"3c0113e44b7c7681","order":1,"width":0,"height":0,"passthru":true,"mode":"text","delay":"0","topic":"topic","sendOnBlur":true,"className":"","topicType":"msg","x":1220,"y":540,"wires":[["f89c8b94065c0f92"]]},{"id":"f89c8b94065c0f92","type":"change","z":"711edbe9464cba2a","name":"","rules":[{"t":"set","p":"directory","pt":"flow","to":"payload","tot":"msg"}],"action":"","property":"","from":"","to":"","reg":false,"x":1410,"y":540,"wires":[[]]},{"id":"09bea2464adcad69","type":"ui_button","z":"711edbe9464cba2a","name":"","group":"3c0113e44b7c7681","order":3,"width":0,"height":0,"passthru":false,"label":"Search","tooltip":"","color":"","bgcolor":"","className":"","icon":"","payload":"","payloadType":"str","topic":"topic","topicType":"msg","x":1220,"y":580,"wires":[["60da293526020a2c"]]},{"id":"a2ca29c9855d8533","type":"change","z":"711edbe9464cba2a","name":"","rules":[{"t":"set","p":"payload","pt":"msg","to":"query","tot":"msg"}],"action":"","property":"","from":"","to":"","reg":false,"x":1040,"y":500,"wires":[["17a39cba18b56f4a"]]},{"id":"510bb51c560178d8","type":"change","z":"711edbe9464cba2a","name":"","rules":[{"t":"set","p":"payload","pt":"msg","to":"directory","tot":"msg"}],"action":"","property":"","from":"","to":"","reg":false,"x":1040,"y":540,"wires":[["09dbdd1d30623cf4"]]},{"id":"f2915bc04c18cd63","type":"inject","z":"711edbe9464cba2a","name":"W","props":[{"p":"directory","v":"W:\\論文","vt":"str"},{"p":"query","v":"ROS Unreal Engine","vt":"str"}],"repeat":"","crontab":"","once":true,"onceDelay":0.1,"topic":"","x":870,"y":500,"wires":[["a2ca29c9855d8533","510bb51c560178d8"]]},{"id":"2fd1a793b1bee0bb","type":"venv-config","venvname":"paper","version":"3.10"},{"id":"3c0113e44b7c7681","type":"ui_group","name":"arXiv","tab":"4fbb1075cf58a732","order":1,"disp":true,"width":"6","collapse":false,"className":""},{"id":"4fbb1075cf58a732","type":"ui_tab","name":"Paper","icon":"dashboard","disabled":false,"hidden":false}]Pythonのコードは以下です。node['flow']['query']、node['flow']['directory']でflowオブジェクトにアクセスしています。先程msgオブジェクトで受け取っていた部分を変更しただけです。
import arxiv
import os
import time
from datetime import datetime
def download_papers(paper_dir, query, wait_time=60, year_limit=2023):
"""
論文を検索し、PDFをダウンロードします。
Parameters:
- paper_dir (str): 保存先フォルダ
- query (str): 検索クエリ(複数のキーワードを空白区切りで指定)
- wait_time (int): ダウンロード間隔(秒)
- year_limit (int): ダウンロード対象とする論文の最小年(それ以前の論文はダウンロードしない)
"""
# 保存先ディレクトリを作成
os.makedirs(paper_dir, exist_ok=True)
print(f"Saving papers to: {paper_dir}")
# arXivクライアントの設定
client = arxiv.Client(page_size=10)
print(f"Searching for papers with query: '{query}'...")
# クエリを空白区切りでAND検索として扱う
formatted_query = " AND ".join(query.split())
# クエリを実行して結果を取得
search = arxiv.Search(
query=formatted_query,
sort_by=arxiv.SortCriterion.SubmittedDate
)
for result in client.results(search):
try:
# タイトルと提出日
print(f"\nTitle: {result.title}")
# print(f"Submitted: {result.updated}")
# print(f"Abstract: {result.summary}")
# 提出日が指定された年よりも前かどうかを確認
submitted_year = result.updated.year # ここで直接年を取得
if submitted_year < year_limit:
print(f"Skipping {result.title} as it was submitted in {submitted_year}, which is before {year_limit}.")
break # 指定年より前の論文が見つかった時点で終了
# ファイル名を適切にフォーマット
sanitized_title = "".join(c if c.isalnum() or c in " _-" else "_" for c in result.title)
pdf_filename = f"{sanitized_title}.pdf"
pdf_paper_path = os.path.join(paper_dir, pdf_filename)
# PDFが既に存在する場合はダウンロードしない
if os.path.exists(pdf_paper_path):
print(f"{pdf_filename} already exists. Skipping download.")
continue
# PDFダウンロード
# print(f"Downloading to: {pdf_paper_path}")
result.download_pdf(dirpath=paper_dir, filename=pdf_filename)
time.sleep(wait_time)
except Exception as e:
print(f"Failed to process {result.title}: {e}")
print("\nDone!")
# Node-REDからの入力
if __name__ == "__main__":
# 保存先フォルダ
paper_dir = os.path.join(node['flow']['directory'].replace("\\", "/"), 'paper')
# 検索ワード
query = node['flow']['query']
# ダウンロード間隔を設定(デフォルト10秒)
wait_time = 10 # 固定値
# ダウンロード対象とする最小年(例:2023年以降の論文)
year_limit = 2020
# 論文のダウンロード
download_papers(paper_dir, query, wait_time, year_limit)▼先頭のinjectノードを、Node-REDの起動時に実行するようにしています。その値がtext inputノードの初期値として渡されます。
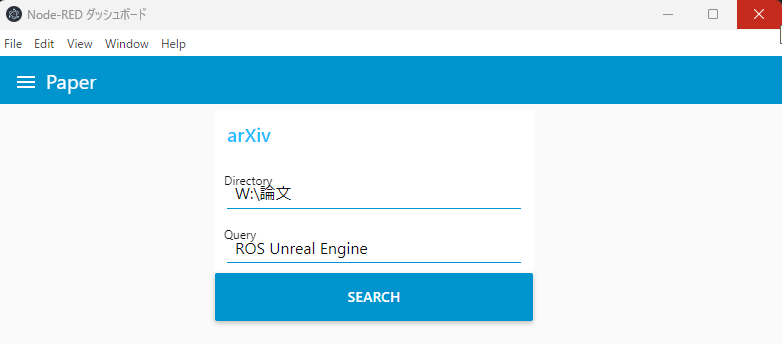
実際に実行してみました。
▼ダッシュボードの画面はこちら。DirectoryとQueryを指定後、SEARCHをクリックするとダウンロードされました。
もっと詳しく条件を指定する場合でも、dashboardノードと組み合わせて簡単に画面を作成することができそうです。
▼ちなみに、私はElectronにNode-REDを組み込んで使っています。ブラウザではなくElectronのウィンドウとして表示されています。
Node-REDをアプリケーションに組み込む その1(Electron、Express)
はじめに 今回はElectronで作成しているアプリケーションに、Node-REDを組み込んでみました。 Node-REDのユーザーガイドに、Expressアプリケーションへの組み込みのサ…
最後に
そもそもは卒論を書くために論文を読みたくて大量に収集していました。ここには書いていないですが、この後さらにpdfファイルからテキストを抽出して、翻訳して、ローカルLLMで要約するという処理につなげています。要素技術を少しずつまとめていこうと思っています。
今回はQueryをROSとUnreal Engineにしていますが、あまり論文が無いんですよね。研究ではその二つを組み合わせているので、先行研究をもっと探したいなと思っています。