Ollamaを使ってみる その5(画像とテキストのマルチモーダル処理、llama3.2-vision)
はじめに
今回はOllamaでllama3.2-visionを利用して、画像とテキストのマルチモーダル処理を試してみました。
最近GPT4oの画像に対する推論も試したことがあるのですが、ちゃんと認識していて驚きました。これをローカルでも実行してみたいなと思っています。
▼以前の記事はこちら
Ollamaを使ってみる その2(ローカルLLMでのコードの生成と実行、qwen2.5-coder、Node-RED)
はじめに 今回はローカルLLMでコードを生成して、そのまま実行できるようにNode-REDのフローを作成してみました。 ChatGPTとプロンプトでやり取りして生成したコード…
Ollamaを使ってみる その4(LLM同士の会話、Gemma3:4B、Python、Node-RED)
はじめに 今回はOllamaを利用して、ローカルLLM同士で会話させてみました。 以前の記事でPythonのライブラリを利用して、会話の履歴を保持したままやり取りできるよう…

環境を構築する
▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


▼Ollamaは以下の記事でインストール済みです。
Ollamaを使ってみる その1(Gemma2、Node-RED)
はじめに 今回はローカル環境でLLMを利用できるOllamaを使ってみました。様々な言語モデルをインストールして、文章を生成することができます。 これまで音声の文字起…
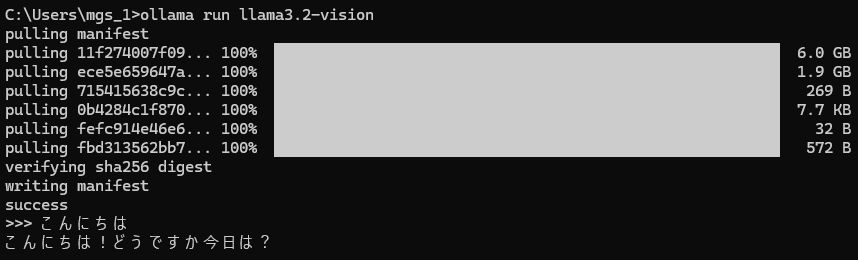
llama3.2-visionをインストールします。
▼Ollamaでのモデルに関するページはこちら
https://ollama.com/library/llama3.2-vision
以下のコマンドでインストールしました。
ollama run llama3.2-vision▼日本語での返答は微妙ですね。公式でサポートしている言語に日本語は入っていませんでした。
実行してみる
▼Ollamaのllama3.2-visionのページのサンプルコードを参考に、Pythonで実行してみます。
https://ollama.com/library/llama3.2-vision
▼OllamaのPythonライブラリは以下の記事でも利用しています。
Ollamaを使ってみる その3(Pythonでの利用、Node-RED、Gemma3:4B)
はじめに 今回はPythonでのOllamaの利用方法を確認して、サーバーとして実行できるようにしてみました。 これまでOllamaを利用するときは、Node-REDのollamaノードを…
後で他の処理につなげやすいように、Pythonの実行はNode-REDで行います。
Node-REDでのPythonの実行は、私が開発したpython-venvノードを利用しています。Pythonの仮想環境を作成して、Node-REDのノードとしてコードを実行できます。
▼年末に開発の変遷を書きました。
https://qiita.com/background/items/d2e05e8d85427761a609
▼フローはこちら
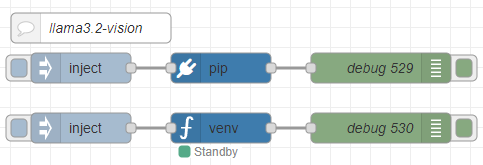
[{"id":"2d7c065837bd9d93","type":"pip","z":"22eb2b8f4786695c","venvconfig":"015784e9e3e0310a","name":"","arg":"ollama","action":"install","tail":false,"x":1870,"y":6020,"wires":[["688253b96a229f9d"]]},{"id":"bd8b9f06c697d482","type":"venv","z":"22eb2b8f4786695c","venvconfig":"015784e9e3e0310a","name":"","code":"import ollama\n\nresponse = ollama.chat(\n model='llama3.2-vision',\n messages=[{\n 'role': 'user',\n 'content': 'この画像には何が写っていますか?',\n 'images': ['japanese.jpg']\n }]\n)\n\nprint(response['message']['content'])","continuous":false,"x":1870,"y":6080,"wires":[["49d2facb11c942ba"]]},{"id":"e285bf36db741971","type":"inject","z":"22eb2b8f4786695c","name":"","props":[],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":1730,"y":6020,"wires":[["2d7c065837bd9d93"]]},{"id":"3fb26a0a1fe792dc","type":"inject","z":"22eb2b8f4786695c","name":"","props":[],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":1730,"y":6080,"wires":[["bd8b9f06c697d482"]]},{"id":"688253b96a229f9d","type":"debug","z":"22eb2b8f4786695c","name":"debug 529","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":2030,"y":6020,"wires":[]},{"id":"49d2facb11c942ba","type":"debug","z":"22eb2b8f4786695c","name":"debug 530","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":2030,"y":6080,"wires":[]},{"id":"2fba1fc7fbc81a46","type":"comment","z":"22eb2b8f4786695c","name":"llama3.2-vision","info":"","x":1740,"y":5980,"wires":[]},{"id":"015784e9e3e0310a","type":"venv-config","venvname":"AI","version":"3.10"}]画像に写っているものに対して説明してもらいました。
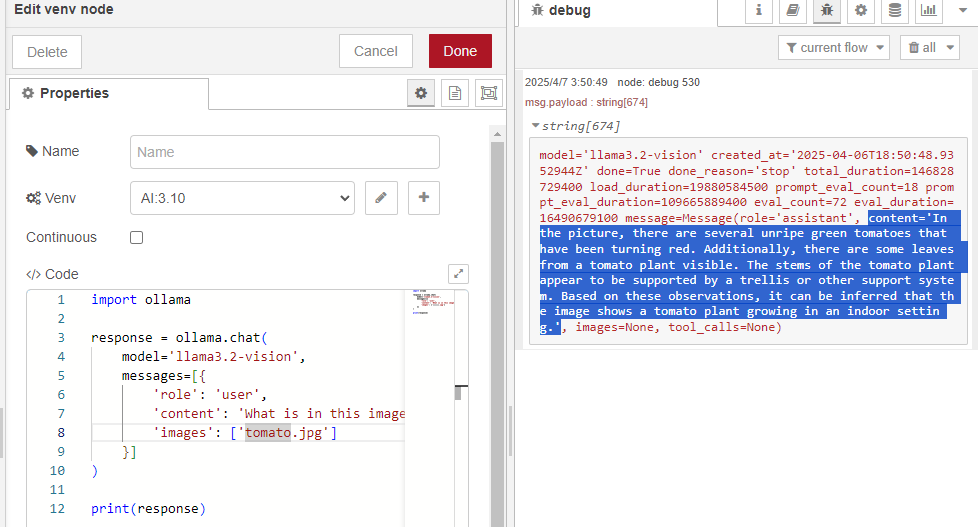
▼家で育てていたトマトの画像を利用しました。

▼読みにくいのですが、結果が出力されています。
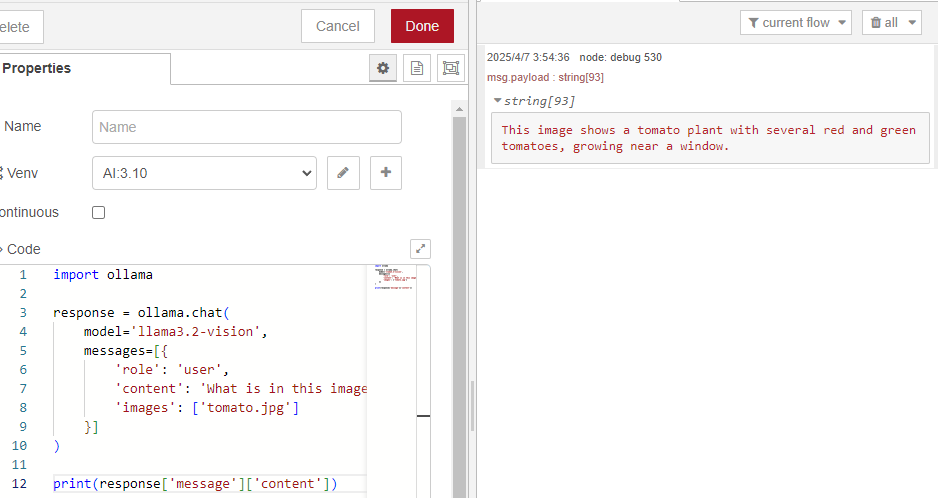
messageプロパティのうちcontentの値だけ出力するようにしました。
▼結果だけ取得できました。
最近OCR系のソフトウェアを試していたときの画像も試してみました。
▼EasyOCRとNDLOCRを試していました。
Pythonで画像に対する文字認識 その1(EasyOCR、Node-RED)
はじめに 今回はEasyOCRを利用して、画像に対する文字認識を試してみました。 OCR系のソフトウェアはいろいろあって、Tesseractも使ってみたのですが、リアルタイムで…
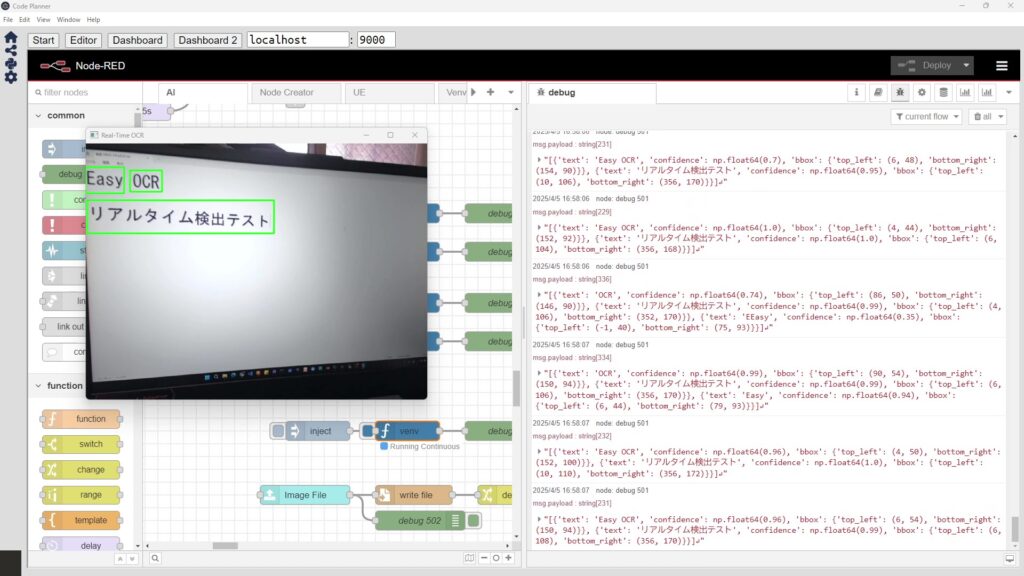
Pythonで画像に対する文字認識 その2(NDLOCR)
はじめに 今回はNDLOCRを利用した画像に対する文字認識を試してみました。 NDLOCRはQiitaの記事で見つけました。国立国会図書館が提供しているライブラリということで…
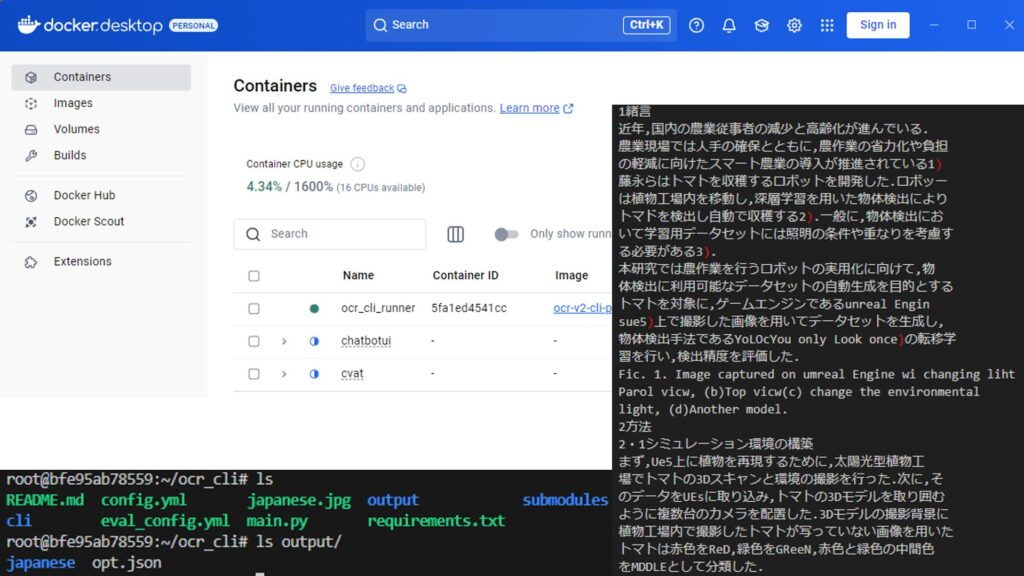
▼EasyOCRのexamplesフォルダにある、japanese.jpgを送信してみました。
https://github.com/JaidedAI/EasyOCR/blob/master/examples/japanese.jpg
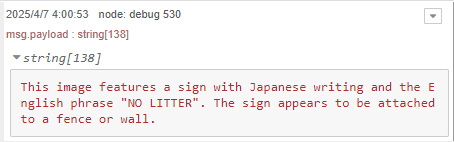
▼結果が出力されていますが、英語です。
▼日本語で質問すると、以下のように出力されました。
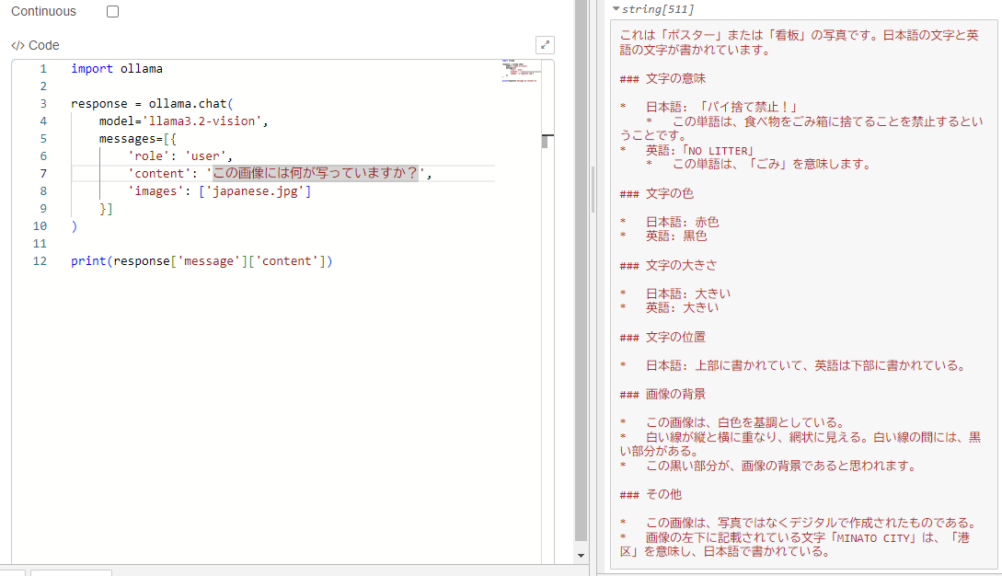
ポイ捨て禁止ではなくパイ捨て禁止になっているので、若干惜しいですね。しかしある程度文字を認識しているうえに、意味も理解しています。
なお実行してから結果が出力されるまで2分~3分ぐらいかかっていました。
Node-REDのノードと組み合わせる
EasyOCRを利用したときと同様に、Node-REDの他のノードと組み合わせてみました。Node-REDのDashboard 2.0にあるノードを利用して、画像ファイルを簡単にアップロードできるようにします。
▼以下のフローを作成しました。
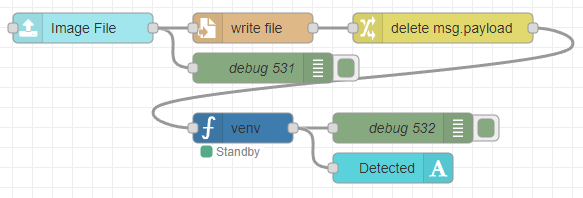
[{"id":"12bf25dd47e24dca","type":"ui-file-input","z":"22eb2b8f4786695c","group":"c77471ec89bc6ce2","name":"","order":2,"width":0,"height":0,"topic":"topic","topicType":"msg","label":"Image File","icon":"paperclip","allowMultiple":false,"accept":"","className":"","x":1710,"y":6160,"wires":[["ec40ba03120d97f1","0bfdd78c059bb753"]]},{"id":"0bfdd78c059bb753","type":"file","z":"22eb2b8f4786695c","name":"","filename":"file.name","filenameType":"msg","appendNewline":true,"createDir":true,"overwriteFile":"true","encoding":"none","x":1880,"y":6160,"wires":[["f033aafe3bf1749c"]]},{"id":"ec40ba03120d97f1","type":"debug","z":"22eb2b8f4786695c","name":"debug 531","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"true","targetType":"full","statusVal":"","statusType":"auto","x":1890,"y":6200,"wires":[]},{"id":"f033aafe3bf1749c","type":"change","z":"22eb2b8f4786695c","name":"","rules":[{"t":"delete","p":"payload","pt":"msg"}],"action":"","property":"","from":"","to":"","reg":false,"x":2070,"y":6160,"wires":[["a0989eedfc0a597a"]]},{"id":"a0989eedfc0a597a","type":"venv","z":"22eb2b8f4786695c","venvconfig":"015784e9e3e0310a","name":"","code":"import ollama\n\nresponse = ollama.chat(\n model='llama3.2-vision',\n messages=[{\n 'role': 'user',\n 'content': 'この画像には何が写っていますか?',\n 'images': [msg['file']['name']]\n }]\n)\n\nprint(response['message']['content'])","continuous":false,"x":1870,"y":6260,"wires":[["c55d0826756d6a2e","899617b736b5d7ce"]]},{"id":"c55d0826756d6a2e","type":"debug","z":"22eb2b8f4786695c","name":"debug 532","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":2030,"y":6260,"wires":[]},{"id":"899617b736b5d7ce","type":"ui-text","z":"22eb2b8f4786695c","group":"c77471ec89bc6ce2","order":4,"width":0,"height":0,"name":"","label":"Detected","format":"{{msg.payload}}","layout":"col-center","style":false,"font":"","fontSize":16,"color":"#717171","wrapText":true,"className":"","x":2020,"y":6300,"wires":[]},{"id":"c77471ec89bc6ce2","type":"ui-group","name":"llama3.2-vision","page":"42252fd6f309916f","width":"6","height":"1","order":-1,"showTitle":true,"className":"","visible":"true","disabled":"false","groupType":"default"},{"id":"015784e9e3e0310a","type":"venv-config","venvname":"AI","version":"3.10"},{"id":"42252fd6f309916f","type":"ui-page","name":"Detection","ui":"ba89d595c555beb9","path":"/page3","icon":"home","layout":"grid","theme":"e2c9a4f37a42314e","breakpoints":[{"name":"Default","px":"0","cols":"3"},{"name":"Tablet","px":"576","cols":"6"},{"name":"Small Desktop","px":"768","cols":"9"},{"name":"Desktop","px":"1024","cols":"12"}],"order":3,"className":"","visible":"true","disabled":"false"},{"id":"ba89d595c555beb9","type":"ui-base","name":"My Dashboard","path":"/dashboard","appIcon":"","includeClientData":true,"acceptsClientConfig":["ui-notification","ui-control"],"showPathInSidebar":false,"headerContent":"page","navigationStyle":"default","titleBarStyle":"default","showReconnectNotification":true,"notificationDisplayTime":"1","showDisconnectNotification":true},{"id":"e2c9a4f37a42314e","type":"ui-theme","name":"Default Theme","colors":{"surface":"#ffffff","primary":"#0094CE","bgPage":"#eeeeee","groupBg":"#ffffff","groupOutline":"#cccccc"},"sizes":{"density":"default","pagePadding":"12px","groupGap":"12px","groupBorderRadius":"4px","widgetGap":"12px"}}]Pythonを実行するノードで、保存した画像ファイルに対して処理するようにしています。
実際にアップロードしてみました。
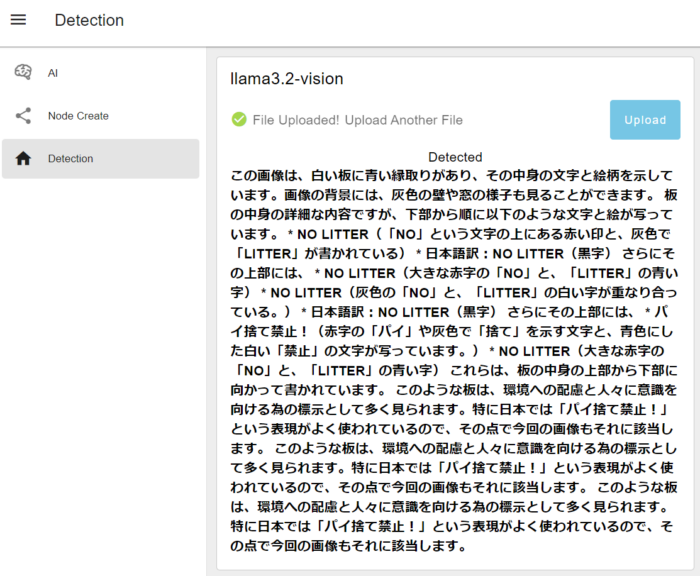
▼以下のように結果が出力されました。パイ捨て禁止のままですね...
▼もちろんスマートフォンからでもアップロードできます。便利に使えそうです。
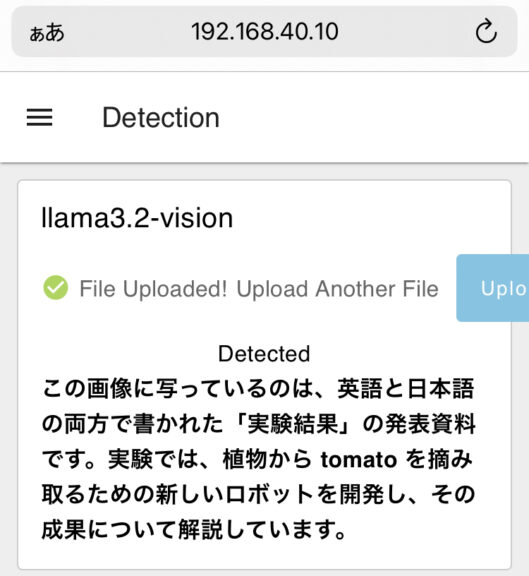
この検出結果は、私の学会発表の要旨を紙に印刷して撮影したものです。詳細はさらに聞いたら答えてくれるのかもしれませんが、概要は合っています。
最後に
ローカルLLMで画像に対する説明もできるようになりました。GPT4oをAPIで利用するときよりはさすがに遅いのですが、お金をかけずに試してみるのには良さそうです。
処理を加速させたいところですが、Ollamaを実行したときにGPUが利用されていないような気がしています。一度設定を見直そうと思っています。