
Node-REDのノードを作成してみる その2(whisperノード)
はじめに
今回はOpen AIのWhisperを利用した、Node-RED用のwhisperノードを作成しました。音声ファイルのパスを渡すと、文字起こしをすることができます。
以前PythonでWhisperを利用できたので、Node-REDでPythonの仮想環境を作成して実行できるpython-venvノードと同じ仕組みで作成しています。インストール時にPythonの仮想環境を作成し、その環境にWhisperをインストールするようになっています。
▼作成したwhisperノードは、すでに公開しています。
https://flows.nodered.org/node/@background404/node-red-contrib-whisper
▼以前の記事はこちら
Node-REDのノードを作成してみる その1(python-venv)
はじめに 今回はNode-REDでPythonの仮想環境を利用できるノードを作成してみました。 これまでNode-RED MCU用のノードを作成したことはありますが、Node-RED用は2つ目…

Whisperを使ってみる(音声認識、OpenAI、Python)
はじめに 今回はOpenAIのWhisperを使ってみました。 OpenAIのサービスはAPIキーを使って有料で利用するイメージがあったのですが、ソースコードはMIT Licenseで公開さ…

execノードで実行してみる
ノードを作成する前に、まずはexecノードでWhisperを利用できるかの確認です。
PythonでWhisperを利用したときのプログラムを元に、引数を受け取って実行できるようにしました。
▼フローはこちら
execノードのコマンドには、仮想環境のpython.exeのパスと、以前の記事で実行していたPythonのプログラムのパスを入力しています。
spawnモードとexecモードを試してみましたが、同様の結果でした。
▼msg.payloadを引数として受け取ることができるようにしています。


実行してみたのですが、文字化けして表示されていました。エンコーディングを変更したりしていたのですが、うまくいきませんでした。
▼デバッグノードでbufferとして表示されています。
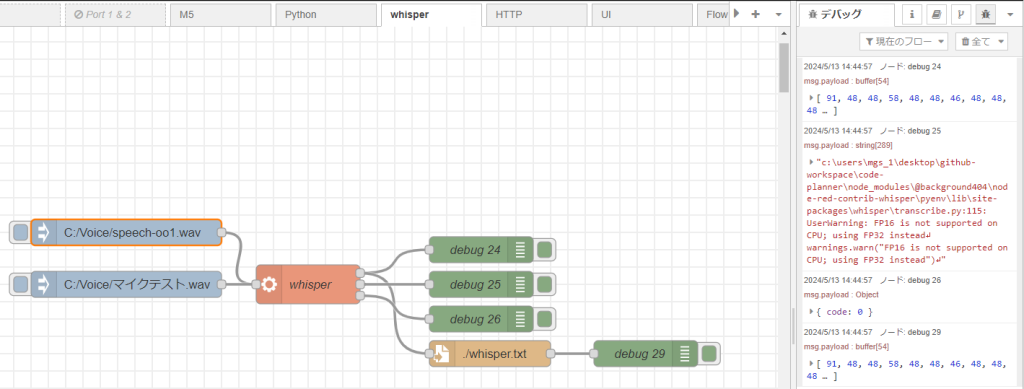
▼ファイルに保存したものも文字化けしていました。

結局、Python側で一旦ファイルに保存して、そのファイルをNode-REDで読み込むようにすると、文字化けせずに表示することができました。
ノードを作成する
ノード作成の方針
python-venvノードと同様に、PythonとJavaScriptのプログラムでやり取りをします。
▼pythonやpipのパスについては、JSONファイルで共有しています。
Whisperの処理はPythonで行い、その呼び出しと出力されたファイルの読み込みはJavaScriptで行っています。
Whisperを実行するにあたって、モデルの大きさや言語、音声ファイルのパスを引数として受け取ることができるようにしています。
▼transcription.pyにその処理が含まれています。
https://github.com/404background/node-red-contrib-whisper/blob/main/transcription.py
出力したテキストをファイルに保存して読み込む
execノードで事前に検証したように、文字化けすることがありました。そこで、Pythonでテキストを一旦ファイルに保存し、そのファイルをJavaScriptで読みこむようにしてみました。
▼Pythonのファイルへの保存については、こちらの記事が参考になりました。
https://note.nkmk.me/python-file-io-open-with/#modew
JavaScript側ではreadFileSyncを使いました。
▼こちらの記事が参考になりました。
https://qiita.com/shirokuman/items/509b159bf4b8dd1c41ef
▼whisper.jsにその処理が含まれています。
https://github.com/404background/node-red-contrib-whisper/blob/main/whisper.js
msg.voicepathで音声ファイルのパスを受け付ける
ノード内で設定した音声ファイルのパスに対して実行するのがデフォルトになっているのですが、msg.voicepathで受け取ったパスでも処理を行うことができるようにしています。
msg.voicepathが設定されていないのに処理を行おうとするとエラーが出たので、msg.voicepathがundefinedでないか、また空白でないかを判定しています。
▼undefinedの判定には、typeofを使っています。
https://www.javadrive.jp/javascript/var/index6.html
▼whisper.jsの処理を抜粋したものがこちら
node.on('input', function(msg) {
if(typeof msg.voicepath !== 'undefined' && msg.voicepath !== '') {
voicepath = msg.voicepath
}
command = pythonPath + ' ' + transcriptionPath + ' ' + voicepath + ' ' + config.language + ' ' + config.model + ' ' + this.id
execSync(command)
msg.payload = String(fs.readFileSync(tmpText))
node.send(msg)
})言語やモデルを選択できるようにする
プルダウンメニューで、言語やモデルを選択できるようにしてみました。編集ダイアログで設定する方法もあるようですが、今回はシンプルにHTMLファイルの要素に書いています。
▼編集ダイアログについてはこちら
https://nodered.jp/docs/creating-nodes/edit-dialog
▼言語の種類については、whisperのリポジトリのtokenizer.pyに書かれています。
https://github.com/openai/whisper/blob/main/whisper/tokenizer.py
言語の種類が羅列されているのですが、さすがにこれを一つずつ選択肢として手入力するのは大変です。今回はHTMLファイルに要素を簡単に追加できるようなフローをNode-REDで作成してみました。
▼フローはこちら

▼このフローは、ノードのexamplesフォルダに含まれています。
https://github.com/404background/node-red-contrib-whisper/blob/main/examples/language.json
▼injectノードにJSON形式で、tokenizer.pyの言語の種類を追加しています。
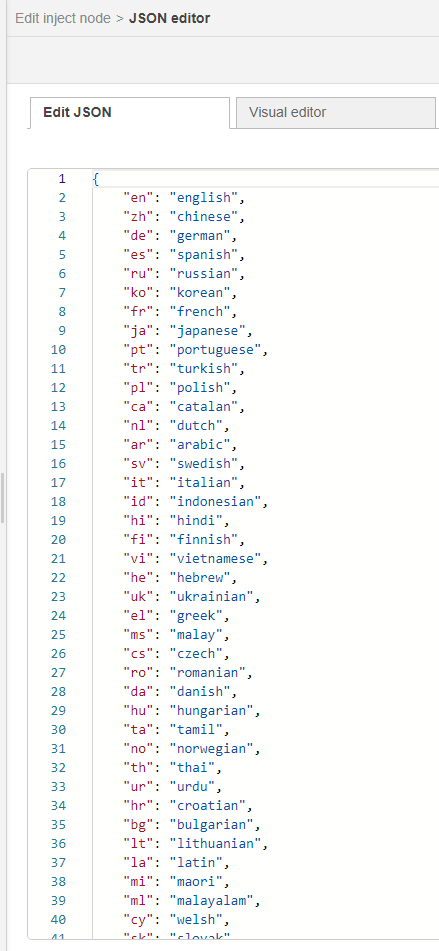
このデータを元に、templateノードで加工して出力しています。データが多すぎるとデバッグウィンドウに表示しきれなかったので、splitノードとjoinノードで分割して表示しています。
▼デバッグウィンドウには、HTML形式でそのまま貼り付けられるように表示しています。
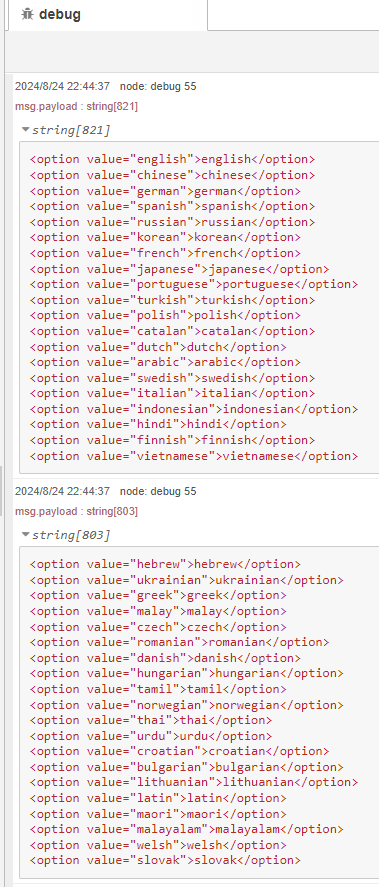
▼作成したwhisper.htmlはこちら
https://github.com/404background/node-red-contrib-whisper/blob/main/whisper.html
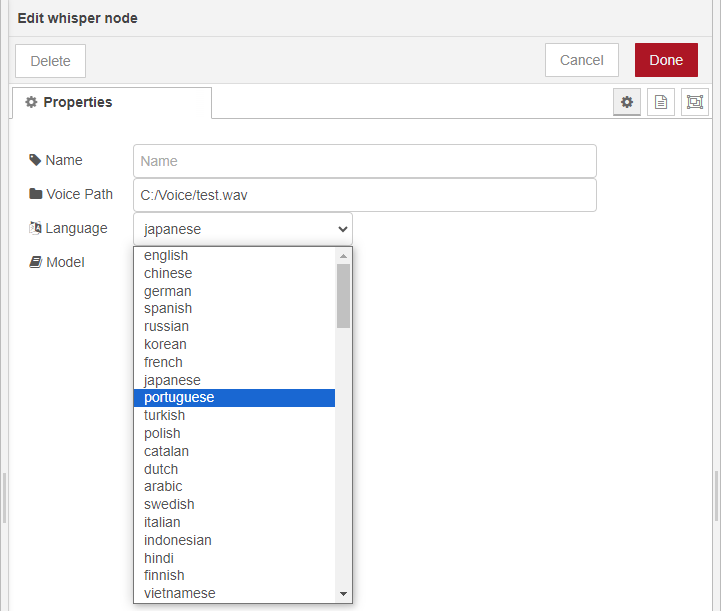
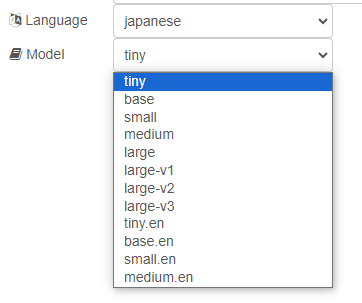
▼ノードの編集画面で、言語を選択できるようになっています。モデルも同様に選択できます。
アイコンの設定
ノードのアイコンは、Font Awesome 4.7のものであれば画像ファイルを追加しなくても使えます。
▼外観についてはこちら
https://nodered.jp/docs/creating-nodes/appearance
▼Font Awesome 4.7のアイコン一覧はこちら。ここにあるアイコン名は利用できます。
https://fontawesome.com/v4/icons
▼ノードの見た目はこちら。吹き出しのアイコンにしました。

実行してみる
作成したノードを実行してみました。
▼フローはこちら

▼このフローは、ノードのexamplesフォルダに含まれています。
https://github.com/404background/node-red-contrib-whisper/blob/main/examples/flow.json
▼以前の記事でも使っていた音声でテストしてみました。
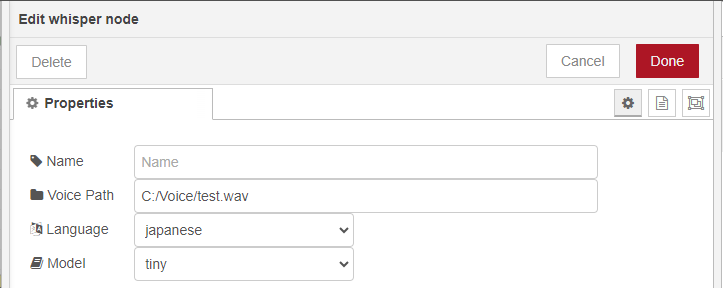
▼音声ファイルのパス、言語、モデルを設定しています。
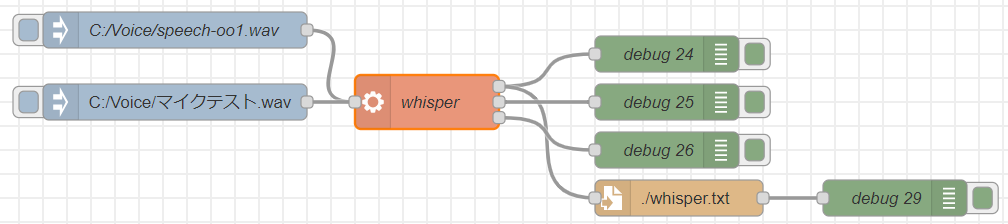
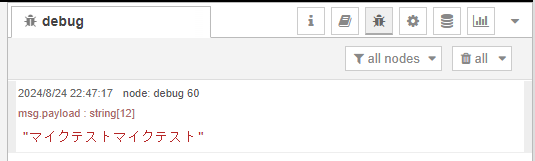
▼音声ファイルから文字起こしができました。Pythonで実行したときと同じ出力結果です。
最後に
Pythonで実行したときと同様に、作成したノードでも実行できました。
今回はNode.jsのchild_processのうちexexSyncを利用しましたが、出力結果が多い場合はspawnを利用したほうが良さそうです。現状では長時間の音声ファイルに対して処理を行うと、処理しきれないかもしれません。
▼spawnについては、python-venvノードを開発していたときに海外の方からPull Requestを頂きました。
https://github.com/404background/node-red-contrib-python-venv/pull/7
本当はノードの実行中にステータスを表示したかったのですが、うまく反映されませんでした。execSyncを使っているせいなのか、他のノードの処理もwhisperノードの処理が終わるまで結果が出力されないようになっていました。この辺りはまた詳しく検証しようと思っています。
▼ステータスについてはこちら
https://nodered.jp/docs/creating-nodes/status

