Faster Whisperを使ってみる(GPUでの実行、Python、Node-RED)
はじめに
今回はFaster Whisperを利用して文字起こしをしてみました。
Open AIのWhisperによる文字起こしよりも高速ということで試したことがあったのですが、以前はCPUでの実行でした。最近YOLOもCUDAとPyTorchの設定を行ってGPUを利用できるようにしたのですが、Faster WhisperもGPUで利用できるようにしました。
▼こちらの記事でも利用したことがあります。処理が遅いと、ロボットがすぐに止まらないということがありました。
音声でロボットを操作してみる(Node-RED、Gemma2、Faster Whisper、XIAO ESP32C3)
はじめに 今回は音声でロボットの操作を試してみました。今まで試してきたことの、ちょっとしたまとめのような感じです。 音声でロボットを操作するにあたって、音声…
▼以前の記事はこちら
Whisperを使ってみる(音声認識、OpenAI、Python)
はじめに 今回はOpenAIのWhisperを使ってみました。 OpenAIのサービスはAPIキーを使って有料で利用するイメージがあったのですが、ソースコードはMIT Licenseで公開さ…

Pythonでテキストを翻訳する(Googletrans、Node-RED)
はじめに 今回はPythonでGoogletransを利用した翻訳を試してみました。 書いてはいないのですが、これまで翻訳するのにdeep-translatorも使ったことがあります。他に…
環境を構築する
Windows 11の環境で、Python 3.10を利用します。
▼PCはRyzen 7、RTX 3050 Laptop GPUが搭載されている、ゲーミングノートPCです。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


以下のコマンドでPythonの仮想環境を作成して、パッケージをインストールします。
py -3.10 -m venv pyenv310
cd pyenv310
.\Scripts\activate
pip install faster-whisper▼特に問題なくインストールされました。
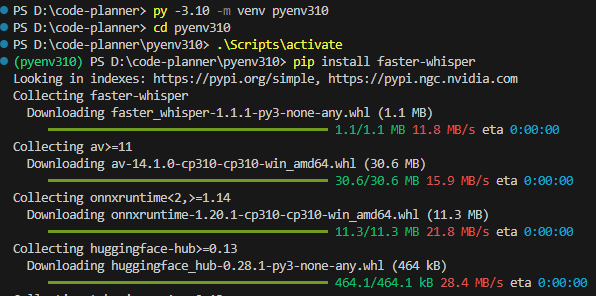
▼Pythonの仮想環境の作成については、以下の記事にまとめています。
Pythonの仮想環境を作成する(venv、Windows)
はじめに 今回はPythonの仮想環境の作成についてまとめてみました。 Pythonを利用したNode-REDのノードを開発するときに仮想環境を詳しく調べていました。作成した仮…

CPUで実行してみる
文字起こしの対象とする音声ファイルはgTTSで生成したものを利用しました。
▼以下の記事で試したことがあります。
PythonでgTTSを使ってみる(音声合成、Node-RED)
はじめに 今回はPythonでgTTS(Google Text-to-Speech)を使ってみました。 以前VoiceVoxも使ったことがあるのですが、英語も話すことができて、ローカル環境での音声の…
▼以下の9秒ぐらいの音声で文字起こしを試してみました。
▼以下のフローで生成することができます。
[{"id":"35dcc8614a07234a","type":"inject","z":"22eb2b8f4786695c","name":"","props":[{"p":"payload"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","payload":"Hello, this is a sample voice. May I help you? I can talk to you by voice. My interface will be further extended.","payloadType":"str","x":1830,"y":2760,"wires":[["5d52af097769c75c"]]},{"id":"64b94f8f700be65e","type":"venv-exec","z":"22eb2b8f4786695c","name":"gTTS","venvconfig":"36c2cf6f351fdc6e","mode":"execute","executable":"gtts-cli.exe","arguments":"","x":1970,"y":2820,"wires":[["1fd3d1f5c03a5732"]]},{"id":"1fd3d1f5c03a5732","type":"debug","z":"22eb2b8f4786695c","name":"debug 427","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":2130,"y":2820,"wires":[]},{"id":"5d52af097769c75c","type":"template","z":"22eb2b8f4786695c","name":"","field":"payload","fieldType":"msg","format":"handlebars","syntax":"mustache","template":"'{{payload}}' --output voice.mp3","output":"str","x":1980,"y":2760,"wires":[["3dd3393f1f930dac","dee234e23e403bf1"]]},{"id":"3dd3393f1f930dac","type":"debug","z":"22eb2b8f4786695c","name":"debug 428","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":2150,"y":2720,"wires":[]},{"id":"dee234e23e403bf1","type":"change","z":"22eb2b8f4786695c","name":"","rules":[{"t":"change","p":"payload","pt":"msg","from":"\"","fromt":"str","to":"","tot":"str"}],"action":"","property":"","from":"","to":"","reg":false,"x":2180,"y":2760,"wires":[["64b94f8f700be65e"]]},{"id":"36c2cf6f351fdc6e","type":"venv-config","venvname":"AI","version":"3.8"}]まずはドキュメントのサンプルプログラムを試してみます。
▼Faster WhisperのGitHubのリポジトリはこちら。モデルの比較についても書かれています。
https://github.com/SYSTRAN/faster-whisper
CPU用に調整したプログラムは以下です。音声ファイルはvoice.mp3という名前で、Pythonの仮想環境のディレクトリに入れています。
from faster_whisper import WhisperModel
model_size = "large-v3"
model = WhisperModel(model_size, device="cpu", compute_type="int8")
segments, info = model.transcribe("voice.mp3", beam_size=5)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))▼初回はモデルのダウンロードが必要なようです。

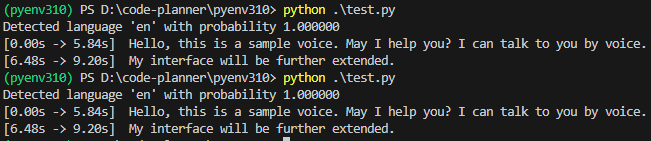
▼実行できました!言語は指定していないのですが、enとして検出されています。
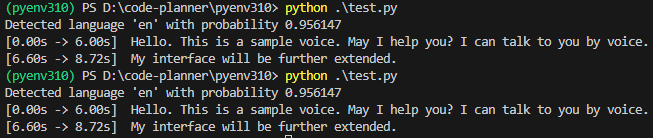
ただしモデルがlarge-v3なので処理が遅いです。30秒ぐらいかかっていました。言語の判定にも時間がかかっているのではないかと思い、transcribeの引数にlanguage="en"を渡してみました。
segments, info = model.transcribe("voice.mp3", beam_size=5, language="en")▼enとして100%検出しています。この状態で22秒ぐらいかかりました。

モデルをlarge-v3から変更して試してみました。
▼baseだと2秒ぐらいで検出できました。

▼tinyも2秒ぐらいでした。baseも速いので、今回使った音声ファイルぐらいなら違いはなさそうです。

▼smallだと4秒ぐらいでした。

▼mediumだと10秒ぐらいかかりました。
gTTSで生成した音声だからなのか、検出精度は特に変わりませんでした。
ただしWhisperModelのdeviceをcudaにすると、エラーが起きます。
▼以下のエラーが起きました。

GPUで実行してみる
GPUで実行した際のエラーを解決していきます。
▼YOLOをGPUで利用しようとしたときもエラーが起きて、設定したことがあります。
YOLOで物体検出 その4(GPUの設定、CUDA 12.6)
はじめに 今回はGPUを利用したYOLOの物体検出を試してみました。 Ultralyticsのドキュメントではオプションで切り替えることができるようでしたが、GPUだとエラーが出…
YOLOの場合はCUDA12.6とPythonの仮想環境でultralyticsをインストールして、torchvisionを一旦アンインストールしてから、再度torch関連のパッケージをインストールしました。
今回も以下のコマンドを実行して、同じ手順を試してみました。
pip uninstall torchvision
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126▼torchvisionは元から入っていなかったようです。その後のコマンドでパッケージがインストールされました。

この後以下のプログラムを実行すると、実行できました。
from faster_whisper import WhisperModel
model_size = "large-v3"
model = WhisperModel(model_size, device="cuda", compute_type="int8")
segments, info = model.transcribe("voice.mp3", beam_size=5, language="en")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))▼実行できました!large-v3で11秒ぐらいかかりました。

CPUで実行していたときよりも、モデルが大きい場合は速くなっているようでした。逆に、小さいモデルだとCPUの方が速かったです。
▼baseで4秒ぐらいかかりました。tinyも同様でした。

▼mediumだと10秒ぐらいで、CPUのときと同じぐらいでした。

モデルをlarge-v3にして、compute_typeをint8から変更して試してみました。
▼float16の場合は9.5秒ぐらいかかりました。

▼int8_float16の場合は11秒ぐらいでした。

float16の方が若干速かったのですが、何が違うのかということについて知識が無いので、また詳しく調べてみようと思います。
Node-REDで実行する
私が開発したNode-REDでPythonのコードを実行できるpython-venvノードを利用して、Faster Whisperを利用してみました。
▼python-venvノードの開発の変遷と仕組みについては、以下のQiitaの記事に書いています。
https://qiita.com/background/items/d2e05e8d85427761a609
これまでのプログラムを踏まえて、以下のフローを作成しました。
▼全体のフローはこちら
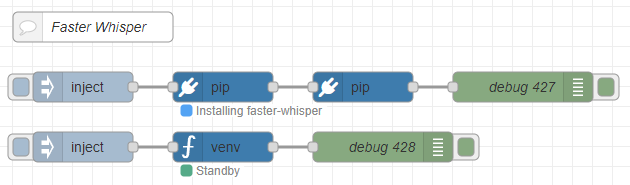
[{"id":"d34b1c24f210765d","type":"comment","z":"22eb2b8f4786695c","name":"Faster Whisper","info":"","x":1800,"y":2720,"wires":[]},{"id":"00832978f0f1b880","type":"pip","z":"22eb2b8f4786695c","venvconfig":"6fee16ddf4b551d4","name":"","arg":"faster-whisper","action":"install","tail":false,"x":1930,"y":2780,"wires":[["cfb8692e8f555b75"]]},{"id":"bae2d94ba8963138","type":"inject","z":"22eb2b8f4786695c","name":"","props":[],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":1790,"y":2780,"wires":[["00832978f0f1b880"]]},{"id":"b8890ca52996e4b4","type":"debug","z":"22eb2b8f4786695c","name":"debug 427","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":2230,"y":2780,"wires":[]},{"id":"cfb8692e8f555b75","type":"pip","z":"22eb2b8f4786695c","venvconfig":"6fee16ddf4b551d4","name":"","arg":"torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126","action":"install","tail":false,"x":2070,"y":2780,"wires":[["b8890ca52996e4b4"]]},{"id":"2fdbcc97e5a92ab2","type":"inject","z":"22eb2b8f4786695c","name":"","props":[{"p":"model","v":"large-v3","vt":"str"},{"p":"voice_path","v":"voice.mp3","vt":"str"}],"repeat":"","crontab":"","once":false,"onceDelay":0.1,"topic":"","x":1790,"y":2840,"wires":[["8b29ca988c0d3af3"]]},{"id":"045ca9bc4dc2d245","type":"debug","z":"22eb2b8f4786695c","name":"debug 428","active":true,"tosidebar":true,"console":false,"tostatus":false,"complete":"false","statusVal":"","statusType":"auto","x":2090,"y":2840,"wires":[]},{"id":"8b29ca988c0d3af3","type":"venv","z":"22eb2b8f4786695c","venvconfig":"6fee16ddf4b551d4","name":"","code":"from faster_whisper import WhisperModel\n\nmodel_size = msg['model']\nmodel = WhisperModel(model_size, device=\"cuda\", compute_type=\"float16\")\n\nsegments, info = model.transcribe(msg['voice_path'], beam_size=5, language=\"en\")\n\nfor segment in segments:\n print(\"[%.2fs -> %.2fs] %s\" % (segment.start, segment.end, segment.text))","continuous":false,"x":1930,"y":2840,"wires":[["045ca9bc4dc2d245"]]},{"id":"6fee16ddf4b551d4","type":"venv-config","venvname":"FasterWhisper","version":"3.10"}]pipノードでfaster-whisperをインストールし、torch関連のパッケージをインストールするようになっています。
venvノードでPythonのコードを実行できます。
▼以下のようにコードを記述しています。
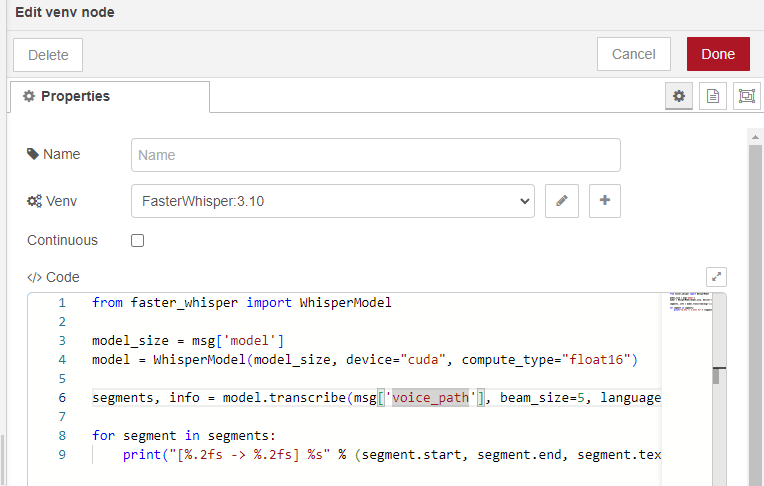
msg['model']という書き方はこのノードに特有のもので、Node-REDのメッセージを受け取ることができます。
▼injectノードで指定しています。
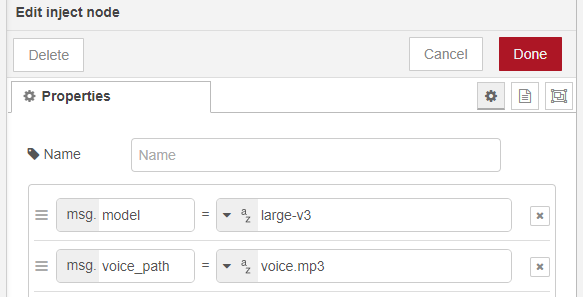
deviceはcudaにして実行してみました。
▼GPUでも実行できました!
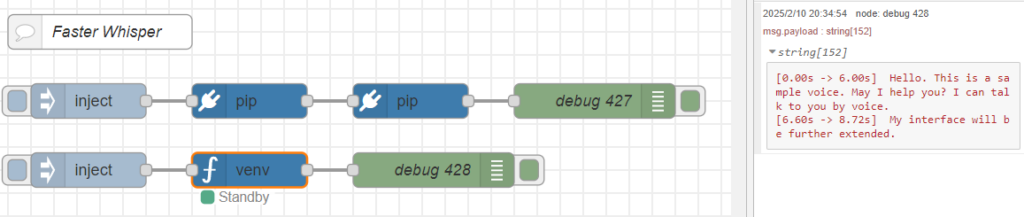
python-venvノードで実行できたので、他のノードと組み合わせることができそうです。
最後に
処理速度を比較してみましたが、モデルのサイズが大きいとGPUの方が速かったです。CPUでも十分速くて、baseモデルで2秒ぐらいはかかるようでした。
今回は9秒ぐらいの短い音声だったので、長い音声だとまた変わってくるかもしれません。また、gTTSで生成した音声だからなのか、文字起こしの結果は特に変わりませんでした。人間の音声だと精度が変わってくるかもしれません。
実際にロボットと対話できるようにしながら、精度についても確認していきたいなと思っています。