
LM Studioを使ってみる その1(インストール、ローカルLLMとの会話)
はじめに
今回はローカルLLMを利用できる、LM Studioを使ってみました。
NVIDIAドライバーの更新のときに新着情報を眺めていたら見つけました。
▼以下の記事でもOllamaとともに触れられています。
NVIDIA RTX PC で大規模言語モデルを始める方法 - NVIDIA | Japan Blog
チャットだけでなくAPIのエンドポイントとしても利用できるということで、まずはインストールして簡単に試してみました。
▼普段はOllamaを使っています。

▼以前の記事はこちら
GitHub Copilotを利用する その1(VS Codeとの連携)
はじめに 今回はGitHub CopilotをVisual Studio Code(VS Code)に導入してみました。 VS Codeで利用すると便利だと教えてもらったので使ってみたのですが、プロジェ…
ちょっと調べもの:GitHub CopilotのAgentモードでのエラー
はじめに 最近VS CodeのGitHub Copilotを利用して開発していたのですが、何かとエラーが起きて進まないことがありました。今回はそのエラーについて調べてみたという話…

インストールする
Windows用のLM Studioをインストールしました。
▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


▼メモリはローカルLLMを実行するために、64GBに交換しています。
ちょっと買い物:ノートPCのメモリ交換(ASUS TUF Gaming A15、gpt-oss-20b)
はじめに 今回はいつも使っているノートPCのメモリを交換して、16GBから64GBに増やしてみました。 リリースされたばかりのgpt-oss-20bをローカルで実行したときにメモ…


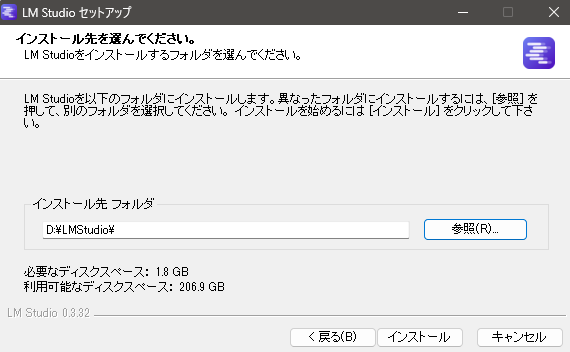
▼以下のページからLM Studioのインストーラをダウンロードして実行しました。
LM Studio - Local AI on your computer
▼1.8GBは必要なようです。結構大きいですね。
▼インストール後、起動しました。
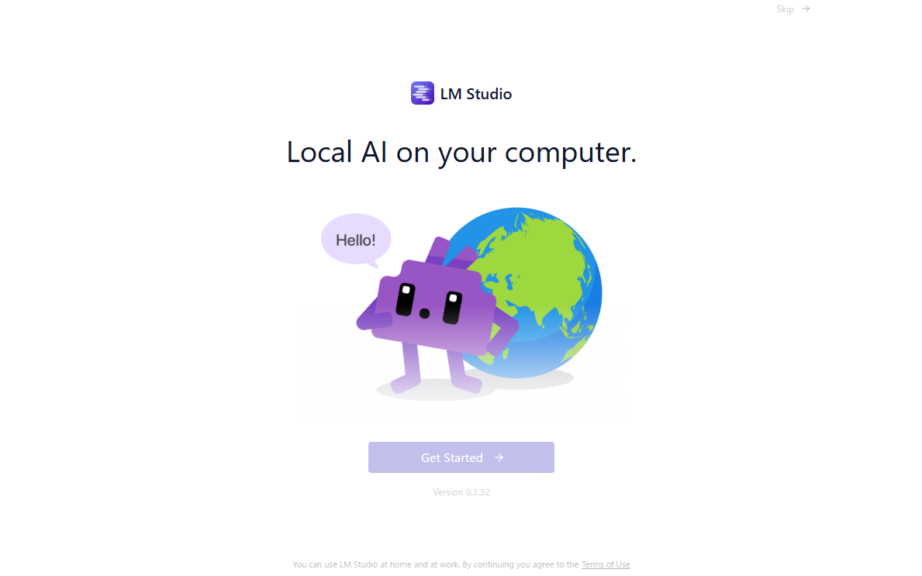
Get Startedのボタンが半透明だったのですが、しばらくすると選択できるようになりました。
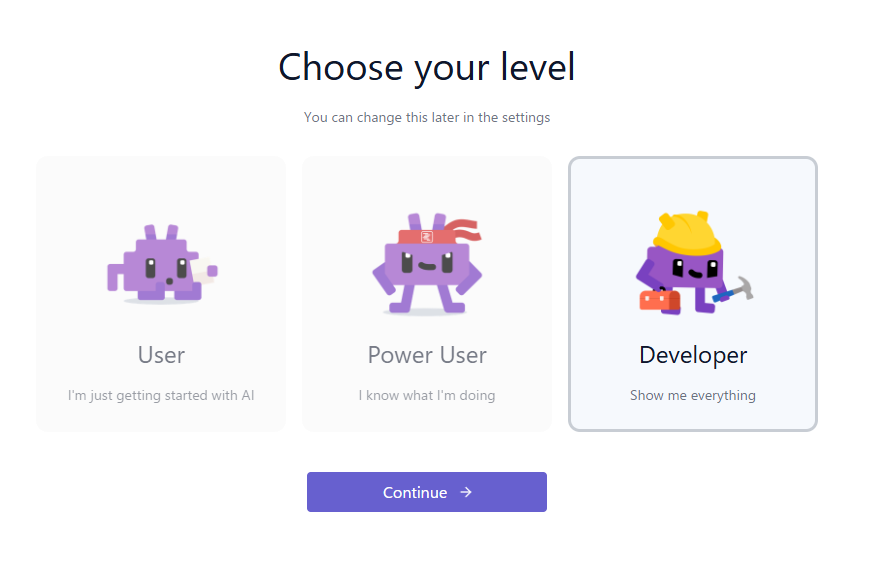
▼レベルはDeveloperにしました。
LLMのモデルをダウンロードしました。
▼最初の選択肢がgpt-oss-20bでした。以前も使ったことがあります。
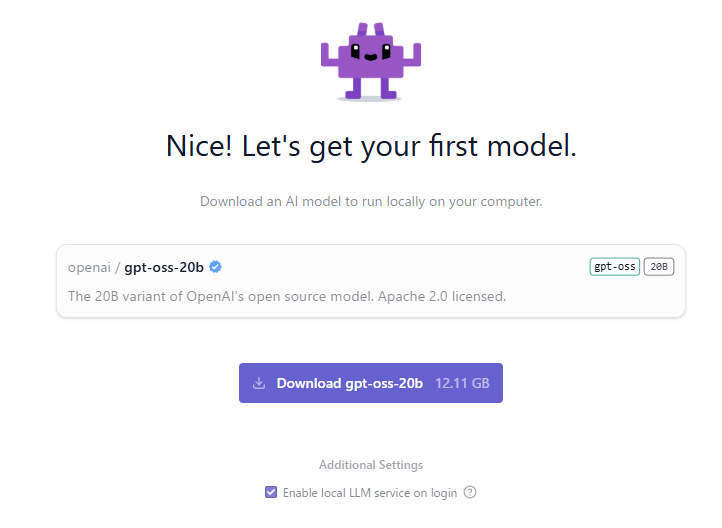
ここでも12.11GBのダウンロードが必要なので、ストレージの容量は重要ですね。
ダウンロードを待っている間に、アプリを見ることができました。
▼モデルのダウンロード先は、デフォルトではユーザーフォルダの.lmstudio/modelsになるようです。
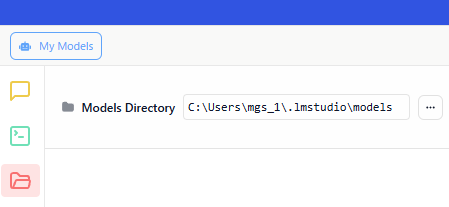
▼ダウンロードを待っている間は選択できなかったのですが、デフォルトの保存先を変更することもできるようです。
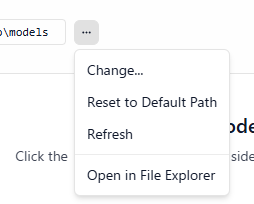
Cドライブは空けておきたかったので、後で他のフォルダに変更しました。
会話してみる
チャット欄でLLMと会話してみました。
▼モデルは検索欄から選べるようでした。
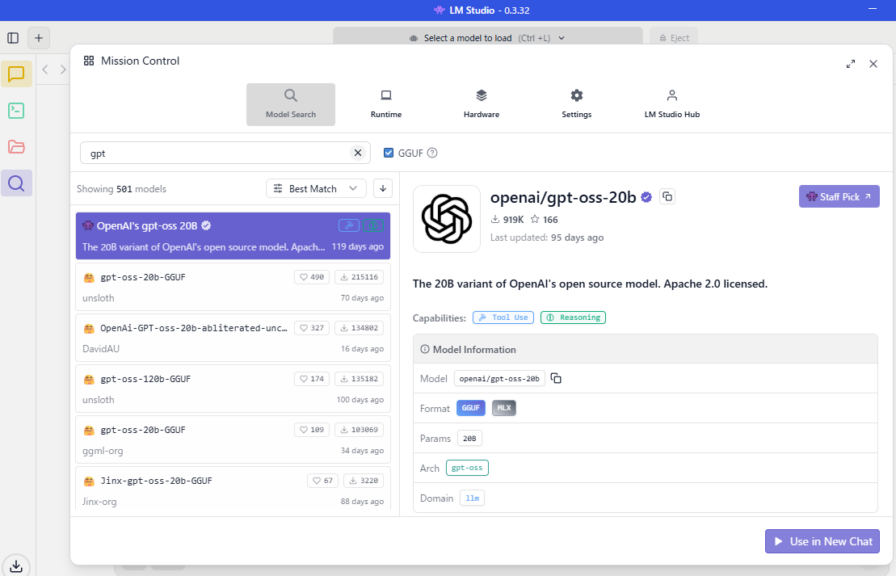
▼いつも通りチャットできています。

▼設定マークから、コンテキストの長さなどのパラメータを設定できるようでした。
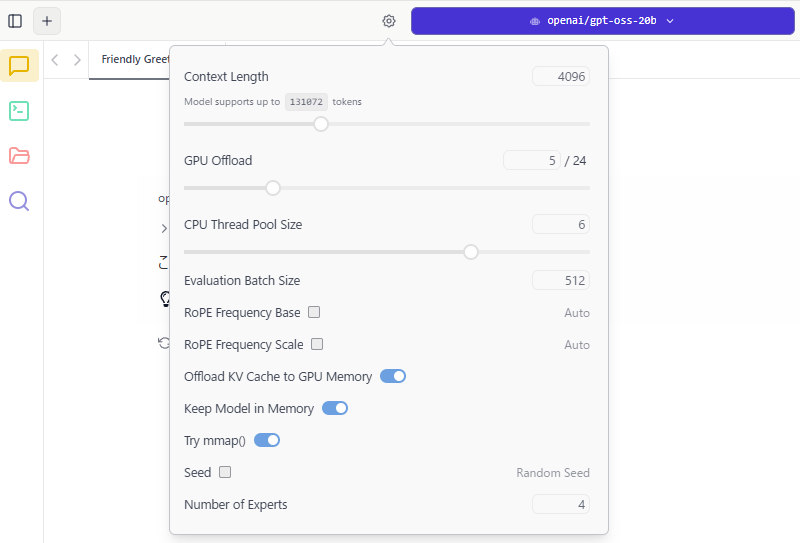
GPUやCPUについても調整できるようです。
エンドポイントを利用してみる
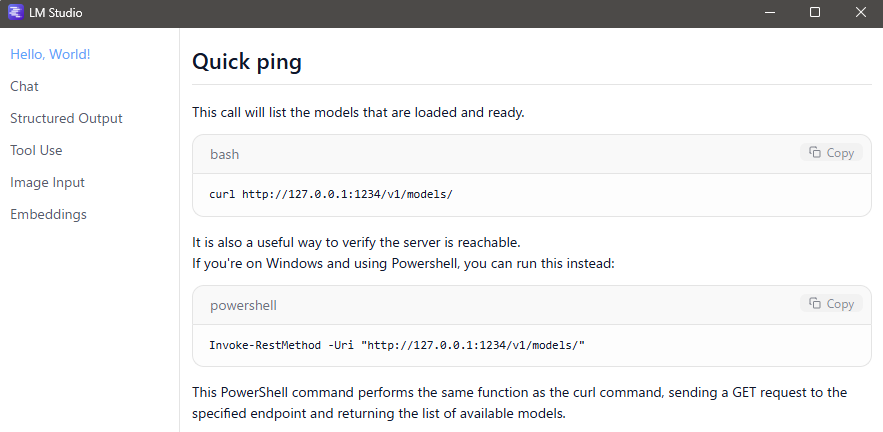
LM Studioのアプリ内でドキュメントを確認できます。
▼Quick Docsから確認できました。
▼コマンドが表示されました。
コマンドを実行して、エンドポイントとの通信を試してみました。項目によってはGit Bashでの実行が紹介されていたので、Git Bashで実行してみました。
▼Git Bashについてはこちら
https://git-scm.com/download/win
LM Studioでgpt-oss-20bをロードしたうえで、以下のコマンドを実行してみました。
curl http://127.0.0.1:1234/v1/models/▼読み込まれているモデルが表示されていました。
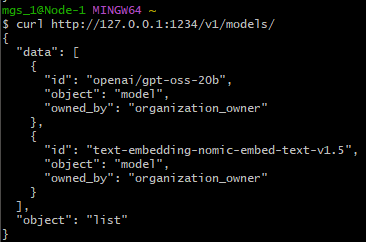
以下のコマンドでチャットも試してみました。
curl http://127.0.0.1:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-20b",
"messages": [
{ "role": "system", "content": "Always answer in rhymes." },
{ "role": "user", "content": "Introduce yourself." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": true
}'▼ちょっとずつ返答が返ってきています。streamがtrueだからですね。
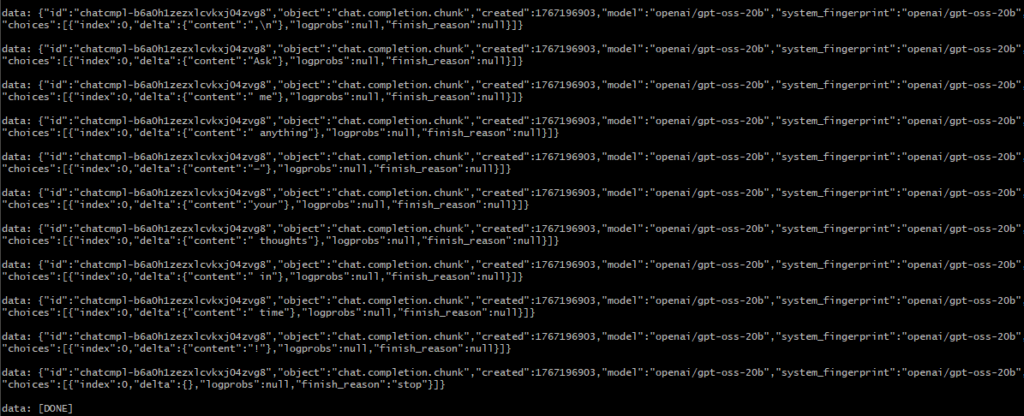
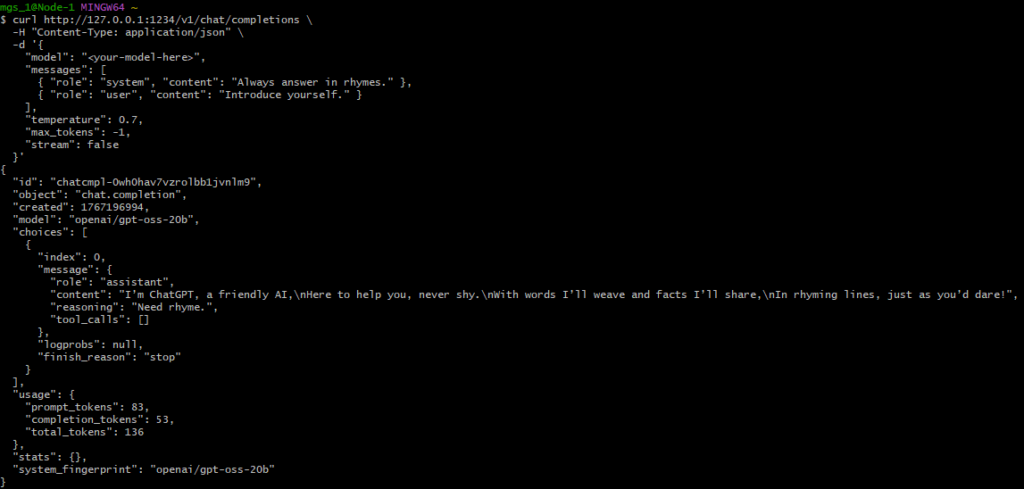
streamをfalseにして実行してみました。
curl http://127.0.0.1:1234/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": gpt-oss-20b",
"messages": [
{ "role": "system", "content": "Always answer in rhymes." },
{ "role": "user", "content": "Introduce yourself." }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": false
}'▼I’m ChatGPT, a friendly AI,\nHere to help you, never shy.\nWith words I’ll weave and facts I’ll share,\nIn rhyming lines, just as you’d dare!と返ってきました。
他にもツールの利用や画像の入力について紹介されていました。
最後に
エンドポイントなどの扱いが分かりやすくなっているOllamaという感じでした。Node-REDと組み合わせて使うときは、こちらの方が使いやすいのかもしれません。
LLMのモデルをダウンロードしていると、それなりにストレージを圧迫するのは注意が必要です。私のノートPCは合計で2.5TBあるので、まだ400GBぐらい空いています。
今回は簡単な確認だけでしたが、またNode-REDなどと組み合わせて使いたいなと思っています。

