
3D Gaussian Splattingを使ってみる その2(画像・動画データから3Dモデルの再構築、WSL2 Ubuntu 20.04)
はじめに
今回は画像や動画のデータから、3D Gaussian Splatting(3DGS)で3Dモデルの再構築を試してみました。
以前の記事で実行したときは用意されていたCOLMAPでしたが、今回は私のiPhone 8で撮影したデータを用います。iPhoneが古すぎてScaniverseは利用できないのですが、PCなら実行できそうです。
コマンドを実行するたびにエラーが起きて対処していたのですが、最終的にうまくいった手順を載せています。
▼環境構築は以下の記事で行いました。
3D Gaussian Splattingを使ってみる その1(環境構築、WSL2 Ubuntu 20.04)
はじめに 今回は3D Gaussian Splattingを利用するために、環境構築を行いました。 スマートフォンのアプリとして提供されているScaniverseで3Dスキャンをして3Dモデル…

▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


▼以前の記事はこちら
Unreal Engine 5を使ってみる その15(Scaniverseのデータ取り込み2回目、SuperSplat)
はじめに 今回はScaniverseで3DスキャンしたデータのUnreal Engine 5 (UE5)への取り込みについて、再び試してみました。 以前の取り込み方だとScaniverseでの見た目と…

3D Gaussian Splatting形式のデータをPythonで変換する
はじめに 今回は3D Gaussian Splatting(3DGS)形式のデータをPythonで変換できるようにしてみました。 ※便宜上3DGS形式と呼称していますが、3DGSは手法で、3DGSにより…

画像から再構成
まずはスマートフォンでランダムに撮影していた観葉植物の画像をもとに試してみました。
▼以下のようなデータが20枚含まれています。




▼必要なデータの形式は、以下のページに書かれています。inputフォルダに画像を入れるだけです。
https://github.com/graphdeco-inria/gaussian-splatting?tab=readme-ov-file#processing-your-own-scenes

今回はlocation名はplantという名前で行っています。ご自身の環境に合わせて変更してください。
Gaussian Splattingのリポジトリ内にあるconvert.pyで変換するのですが、実行したところエラーが起きていました。
▼colmapが無いというエラーです。

以下のコマンドでcolmapをインストールしました。
sudo apt install -y colmapインストール後に再度convert.pyを実行すると、今度はSiftGPUがサポートされていないというエラーが起きていました。
▼以下のように表示されました。
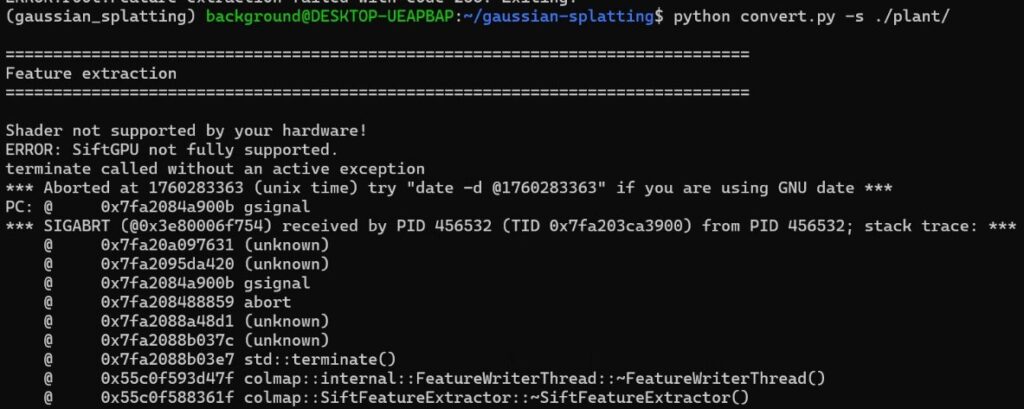
WSL2のUbuntu環境で実行しているので、その影響もあるかもしれません。
▼Docker環境ではこの問題に対する解決策があるようです。
https://github.com/colmap/colmap/issues/1289
今回はChatGPTに聞きながらcolmapコマンドで変換することにしました。
colmap feature_extractor \
--database_path ./plant/database.db \
--image_path ./plant/input \
--ImageReader.single_camera 1 \
--SiftExtraction.use_gpu 0▼実行はできるのですが、プロセスがKillされていました。

画像サイズが大きくて処理できない疑いがあったので、リサイズして処理を行いました。
sudo apt install imagemagick
mogrify -resize 1280x720 ./plant/input/*.jpg再度colmapのコマンドを実行したところ、処理が進んでいきました。
▼20枚の画像に対して処理が行われました。
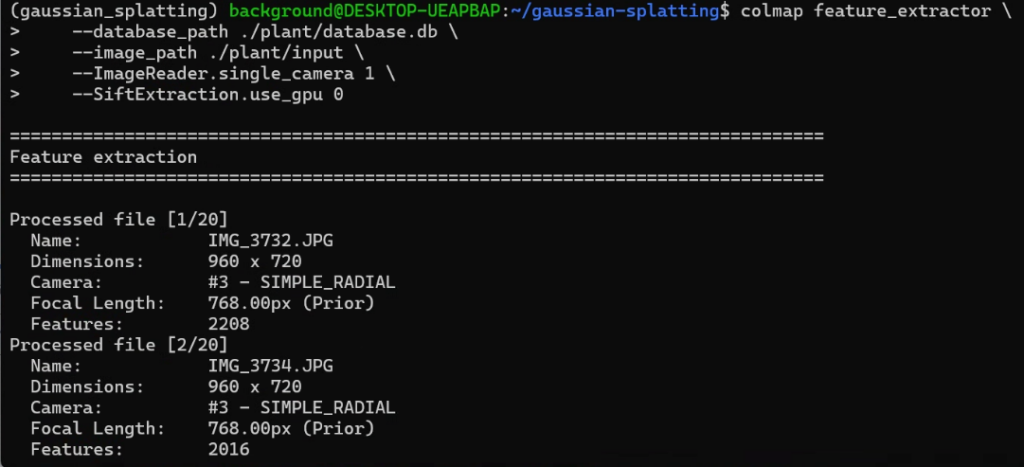
さらにMatchingの処理を行います。
colmap exhaustive_matcher \
--database_path ./plant/database.db \
--SiftMatching.use_gpu 0▼問題なく実行できました。
Mapperの処理も行います。
mkdir -p ./plant/sparse
colmap mapper \
--database_path ./plant/database.db \
--image_path ./plant/input \
--output_path ./plant/sparse▼こちらも問題なく実行できました。
ここまで処理できたので、Gaussian Splattingのmatchingなどの処理は飛ばして変換を行います。
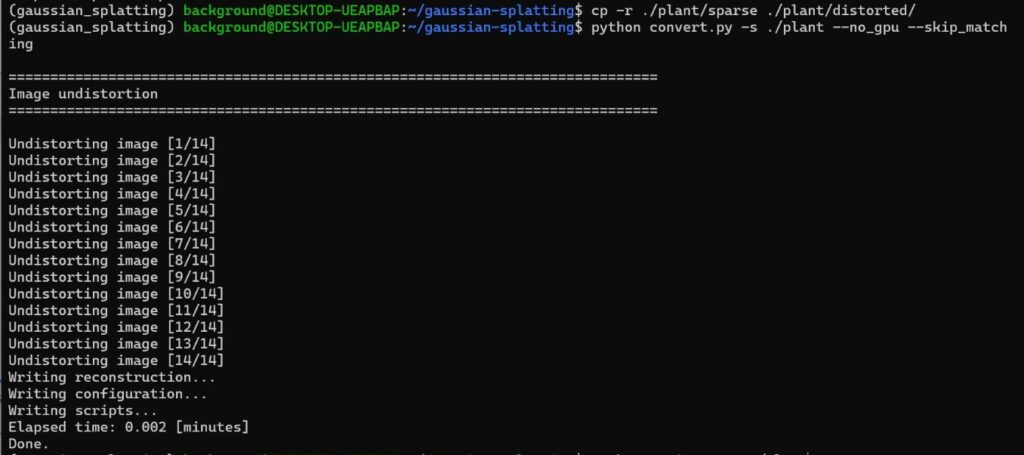
cp -r ./plant/sparse ./plant/distorted
python convert.py -s ./plant --no_gpu --skip_matching▼これで変換できました。
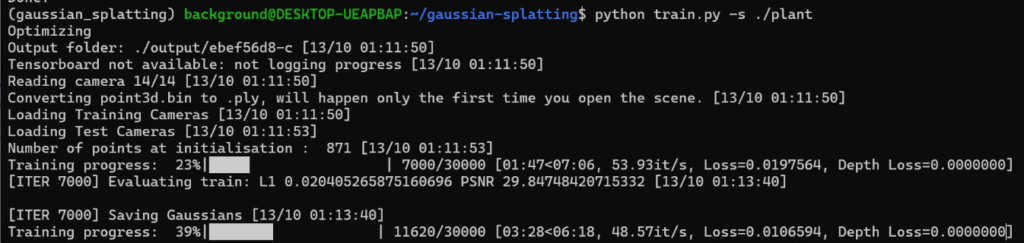
データは用意できたので、Trainを実行します。
▼処理が進んでいきました。
処理後のデータが保存されていました。
▼outputフォルダにあります。
SuperSplatで確認してみました。
▼以下のように表示されました。


立体的な3Dモデルにはならず、平面的なものになってしまいました。画像データがバラバラすぎて、マッチングできなかったのかもしれません。処理はできたものの、失敗という感じでした。
動画から再構成
iPhone 8で動画を撮影して、そこから画像データを抽出して、3DGSによる再構成を試してみました。
▼以下のような動画を撮影して利用しました。
予めinput/haniwaフォルダを作成して、そこにinputフォルダを作成し、動画ファイルを入れておきました。
ffmpegを利用して、約30秒の映像に対して1秒当たり5枚の画像を抽出しました。
sudo apt install ffmpeg
ffmpeg -ss 0 -i IMG_5199.MOV -t 60 -r 5 -q:v 1 -f image2 input/%06d.jpg▼157枚の画像が集まりました。
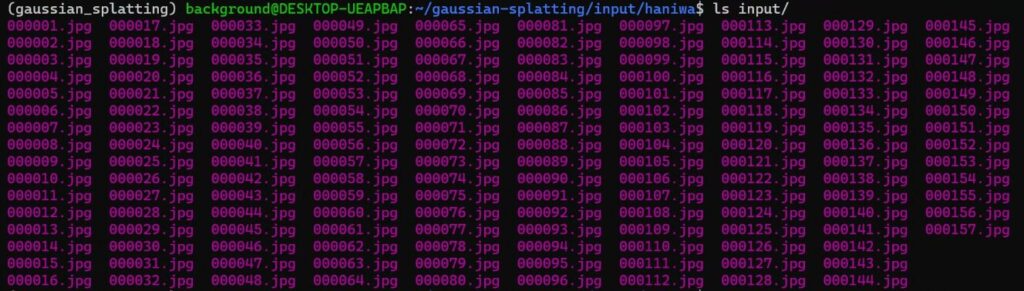
画像データが用意できれば、後の手順は先程と同様です。コマンドを実行していきました。
まずはcolmapによる処理を行っていきます。
colmap feature_extractor \
--database_path ./input/haniwa/database.db \
--image_path ./input/haniwa/input \
--ImageReader.single_camera 1 \
--SiftExtraction.use_gpu 0 \colmap exhaustive_matcher \
--database_path ./input/haniwa/database.db \
--SiftMatching.use_gpu 0▼問題なく処理されました。
mkdir -p ./input/haniwa/sparse
colmap mapper \
--database_path ./input/haniwa/database.db \
--image_path ./input/haniwa/input \
--output_path ./input/haniwa/sparse \
--Mapper.init_min_tri_angle 4 \
--Mapper.num_threads 8 \
--Mapper.multiple_models 0colmapによる処理は完了したので、convert.pyによる変換を行いました。
cp -r ./input/haniwa/sparse ./input/haniwa/distorted/
python convert.py -s ./input/haniwa --no_gpu --skip_matchingTrainを実行しました。
python train.py \
--source_path ./input/haniwa \
--images ./input \
--iterations 50000 \
--resolution 2 \
--feature_lr 0.01 \
--opacity_lr 0.01 \
--scaling_lr 0.01 \
--rotation_lr 0.01 \
--densification_interval 5000 \
--white_background \
--data_device cuda出力されたものをSuperSplatで確認してみました。
▼背景の部分が靄のようになっています。

不要な部分はSuperSplatで除去してみました。
▼iteration_7000の場合はこちら

▼iteration_50000の場合はこちら

Scaniverseでスキャンしたときのように、3Dモデルを再構築できています。前回の列車のデータのときもそうでしたが、iteration_7000とiteration_50000の見た目の違いは特に見られませんでした。
最後に
動画から画像を抽出したものを利用すれば、3DGSにより3Dモデルを再構築することができました。画像データにカメラの位置などの情報が無いので推定する必要があり、動画から連続的な画像を抽出したため推定しやすかったのではないかと考えています。
3DGSでTrainできるデータの用意もできたので、次はGS2Meshによるメッシュ化も試そうと思っています。

