
Ollamaを使ってみる その7(Tailscaleを利用したインターネット経由の通信)
はじめに
今回はAPIやVPN接続を利用して、Ollamaを使ってみました。
私が普段使っているノートPCでは大きなLLMだと処理が重いのですが、インターネットを経由して、デスクトップPCのOllamaで処理を行うように分散して運用しようと思っています。ついでに、OllamaのAPIについてもcurlコマンドで実行してみました。
▼LM StudioのAPIも最近確認していました。
LM Studioを使ってみる その1(インストール、ローカルLLMとの会話)
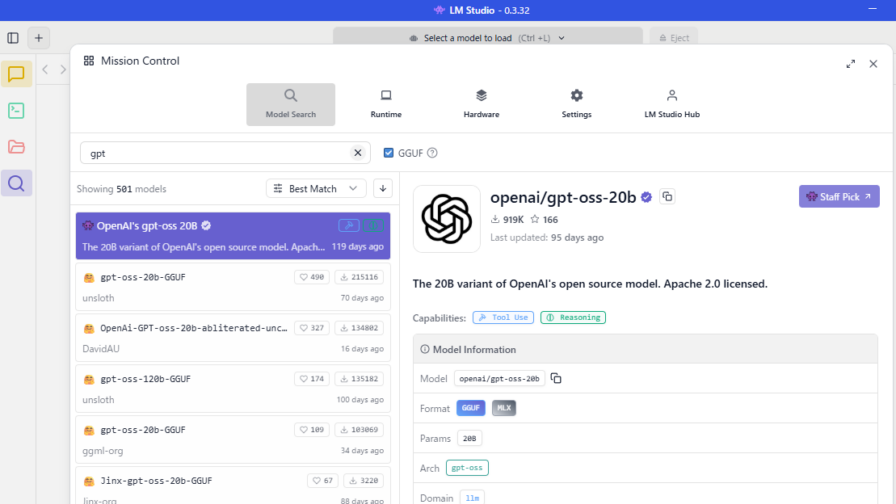
はじめに 今回はローカルLLMを利用できる、LM Studioを使ってみました。 NVIDIAドライバーの更新のときに新着情報を眺めていたら見つけました。 ▼以下の記事でもOllam…
▼以前の記事はこちら
Ollamaを使ってみる その5(画像とテキストのマルチモーダル処理、llama3.2-vision)
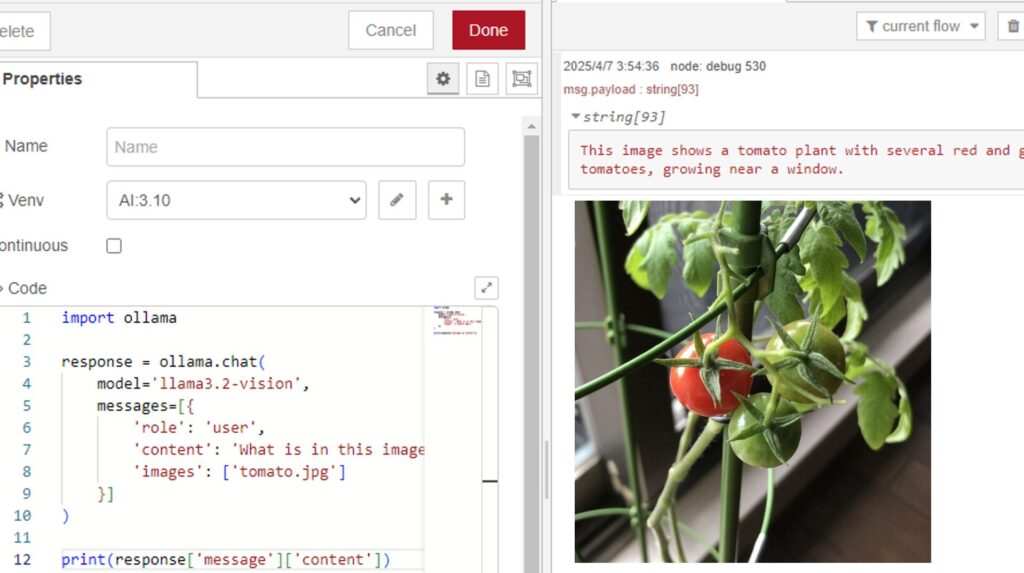
はじめに 今回はOllamaでllama3.2-visionを利用して、画像とテキストのマルチモーダル処理を試してみました。 最近GPT4oの画像に対する推論も試したことがあるのです…
Ollamaを使ってみる その6(ネットでの検索結果との併用、Node-RED)
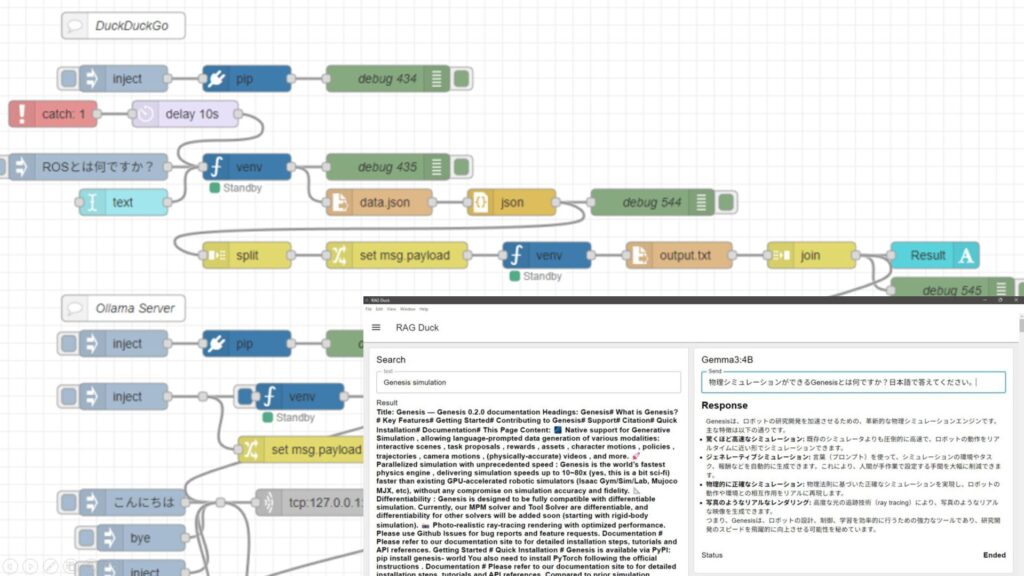
はじめに 今回は以前試していたPythonによる検索と、ローカルLLMを組み合わせてみました。 LLMが学習していないデータを、ネット上の最新の情報で補うというやり方に…
APIについての確認
今回はOllamaのAPIをcurlコマンドで利用して動作を確認します。
▼Ollamaについては以前の記事でインストールしています。
Ollamaを使ってみる その1(Gemma2、Node-RED)
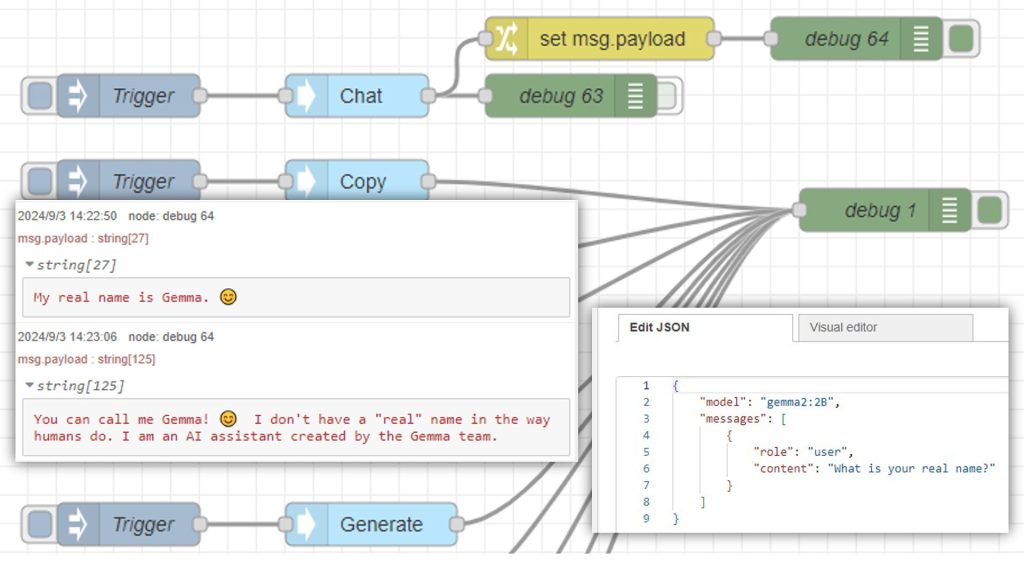
はじめに 今回はローカル環境でLLMを利用できるOllamaを使ってみました。様々な言語モデルをインストールして、文章を生成することができます。 これまで音声の文字起…
まずは私のノートPCで確認を行います。
▼メモリはローカルLLMを実行するために、64GBに交換しています。
ちょっと買い物:ノートPCのメモリ交換(ASUS TUF Gaming A15、gpt-oss-20b)
はじめに 今回はいつも使っているノートPCのメモリを交換して、16GBから64GBに増やしてみました。 リリースされたばかりのgpt-oss-20bをローカルで実行したときにメモ…


▼以下のAPIのドキュメントに沿ってコマンドを実行していきます。
https://docs.ollama.com/api/introduction
Windowsのコマンドプロンプトでcurlコマンドを実行していきます。まずはモデルの取得について試してみました。
curl http://localhost:11434/api/tags▼ダウンロードされているモデルが表示されました。
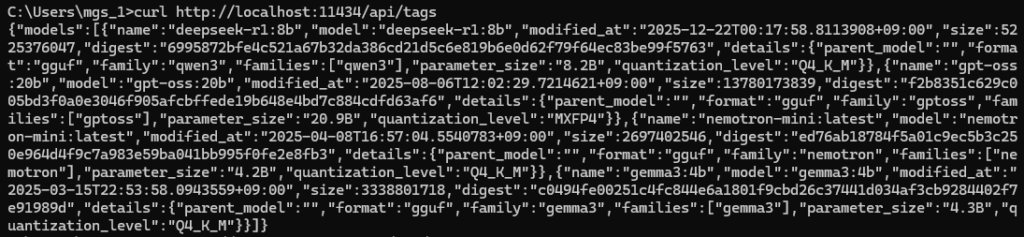
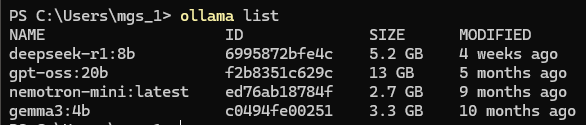
▼ollama listコマンドでも確認できます。
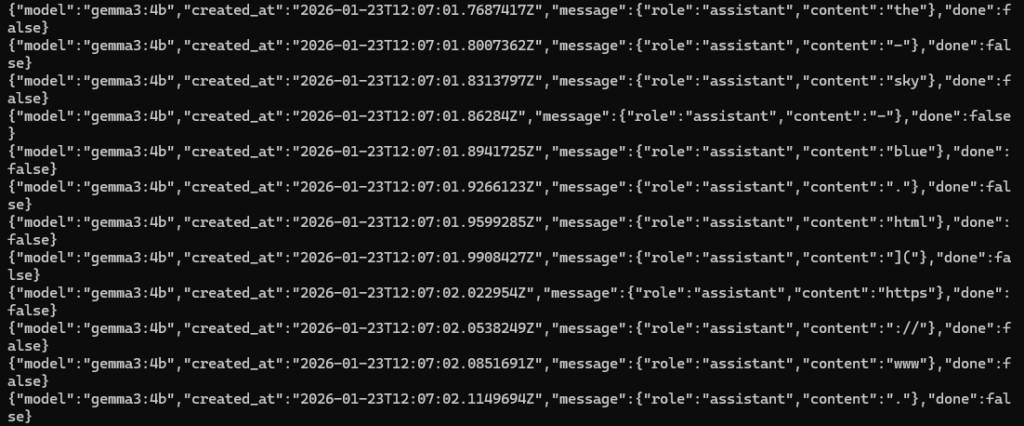
チャットの返答を得るためのAPIも試してみたのですが、ドキュメントのままでは実行できませんでした。Windowsの場合は囲み文字の変更やダブルクォーテーションのエスケープを行う必要があるようです。
curl http://localhost:11434/api/chat -d "{\"model\": \"gemma3:4b\",\"messages\": [{\"role\": \"user\",\"content\": \"why is the sky blue?\"}]}"▼LM Studioのときにも似たようなことがあったのですが、単語ごとに出力されていました。
"stream": falseを追加しました。
curl http://localhost:11434/api/chat -d "{\"model\": \"gemma3:4b\",\"messages\": [{\"role\": \"user\",\"content\": \"why is the sky blue?\"}],\"stream\": false}"▼処理が終わってから出力されました。

レスポンスが長かったので、Hello!とだけ聞いてみました。
curl http://localhost:11434/api/chat -d "{\"model\": \"gemma3:4b\",\"messages\": [{\"role\": \"user\",\"content\": \"Hello! \"}],\"stream\": false}"▼3秒ぐらいで回答が返ってきました。

インターネット経由での通信
TailscaleによるVPN接続を利用している、Windows 11のPC2台で通信を行います。Ollamaの処理はデスクトップPC側で行います。
▼Tailscaleについては、以下の記事で導入しました。
Jetson Xavierを使ってみる その2(通信周りの設定、Node-RED、TailScale)
はじめに 今回は以前OSのセットアップを行ったJetson Xavierの通信周りの設定を行いました。 自宅サーバーとして使いたかったので、外部のネットワークからでもアクセ…

OllamaのGUI画面でネットワークに関する設定項目があったので、設定しておきました。
▼タスクバーのラマを右クリックすると、Open Ollamaという選択肢があります。
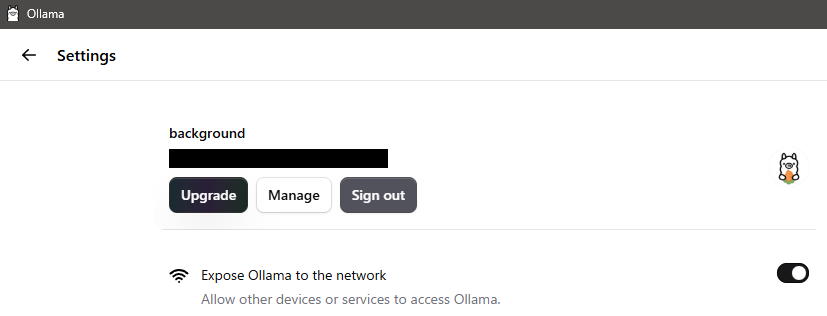
▼SettingsのExpose Ollama to the networkを有効にしておきました。
TailscaleのIPアドレスで、デスクトップPCのOllamaにリクエストを送信します。
まずはモデルについて確認してみました。IPアドレスの部分は置き換えてください。
curl http://<IPアドレス>:11434/api/tags▼先程とは異なるモデルが表示されています。

gemma3:4bはダウンロードしていなかったので、gemma3:27bで試してみました。
curl http://<IPアドレス>:11434/api/chat -d "{\"model\": \"gemma3:27b\",\"messages\": [{\"role\": \"user\",\"content\": \"Hello! \"}],\"stream\": false}"▼回答が返ってきました。

なお、出力には13秒ぐらいかかっていました。
APIでgemma3:4bのダウンロードを実行してみました。
curl http://<IPアドレス>:11434/api/pull -d "{\"model\": \"gemma3:4b\"}"もう一度、gemma3:4bを利用してリクエストを送信してみました。
curl http://<IPアドレス>:11434/api/chat -d "{\"model\": \"gemma3:4b\",\"messages\": [{\"role\": \"user\",\"content\": \"Hello! \"}],\"stream\": false}"▼1秒ぐらいですぐに回答が返ってきました。

通信しているものの、ノートPCよりも返答が速かったです。
最後に
Tailscale経由でOllamaを利用でき、返答も速かったので、Raspberry Piから通信してLLMとやり取りできるようにしたいなと思っています。音声認識なども組み合わせて、ロボットに搭載したいところです。
CTF関連でLinux環境でcurlコマンドを使っていましたが、Windowsのコマンドプロンプトだとエスケープする必要があったりして、入力しづらかったです。Ollamaは各種言語のライブラリがあるので、それを利用するのがやはり使いやすそうだと思いました。
▼APIの中にはモデルの作成もあったので、気になっています。
https://docs.ollama.com/api/create

