YOLOで物体検出 その4(GPUの設定、CUDA 12.6)
はじめに
今回はGPUを利用したYOLOの物体検出を試してみました。
Ultralyticsのドキュメントではオプションで切り替えることができるようでしたが、GPUだとエラーが出ていたのでCPUで実行していました。
GPUでも実行できるように設定して、処理が速いようであれば活用していこうと思っています。
▼GPUを利用したYOLOv5での物体検出については、NVIDIAの記事がありました。
NVIDIA の GPU に最適化された YOLOv5 の実装で物体検出アプリケーションを高速化する - NVIDIA 技術ブログ
物体検出というと、コンピューター ビジョンの伝統的なアプローチは、検出したいオブジェクトの種類に応じたサイズのスライディング ウィンドウを使用して、画像の左から…

▼以前の記事はこちら
YOLOで物体検出 その1(Ultralytics、YOLO11)
はじめに 今回は物体検出アルゴリズムであるYOLOを使ってみました。 物体検出ははじめてなので、まずは調べながら実行しやすいものでお試しです。そもそもロボットに…
YOLOで物体検出 その3(ROSとの連携、WSL2 Ubuntu 18.04)
はじめに 今回はWSL2のUbuntu18.04でYOLOとROSを連携させてみました。 実際にYOLOで物体を検出し、その検出した位置にロボットを動かすために使われていました。リア…

環境の確認
PCは最近購入したゲーミングノートPCを使っています。
▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


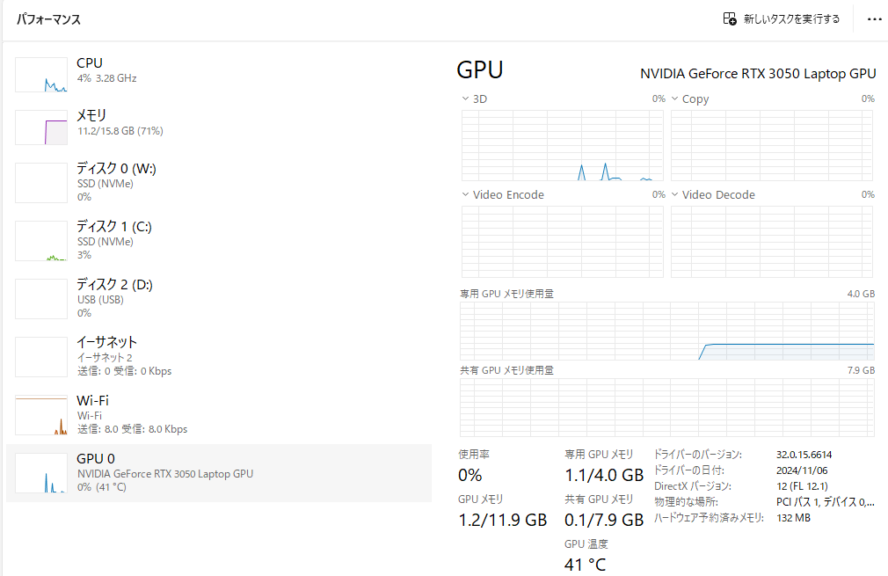
CPUはRyzen 7、GPUはRTX 3050 Laptop GPUです。
▼タスクマネージャーで確認できました。
確認用のコマンドがあったので実行してみました。
▼nvccは認識されていません。

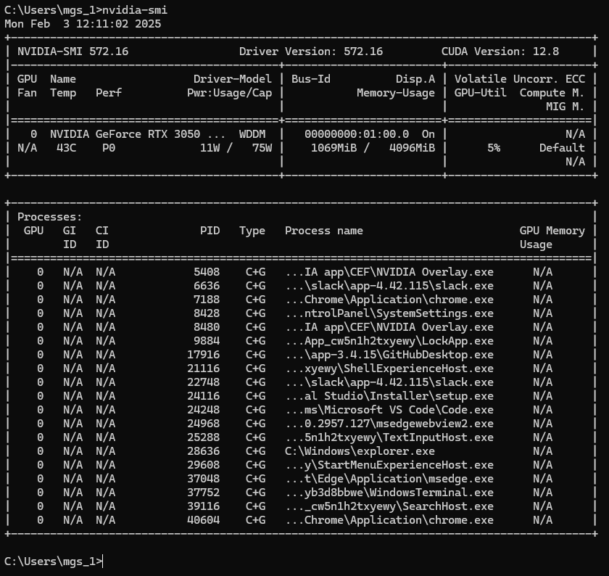
▼nvidia-smiは以下のように表示されました。
CUDAのインストール
調べていると、PyTorchに対応したCUDAのバージョンがあるようでした。
▼以下のページで確認できました。
https://pytorch.org/get-started/locally
▼CUDAのバージョンによって実行するコマンドが異なるようです。

最新だとCUDA 12.8を利用できるようですが、PyTorchのページにあったCUDA 12.6をインストールすることにしました。
▼以下のページで利用している環境を選択して、インストーラをダウンロードできました。
https://developer.nvidia.com/cuda-12-6-0-download-archive
▼Windows 11、x86_64で選択して、exe(local)をダウンロードしました。
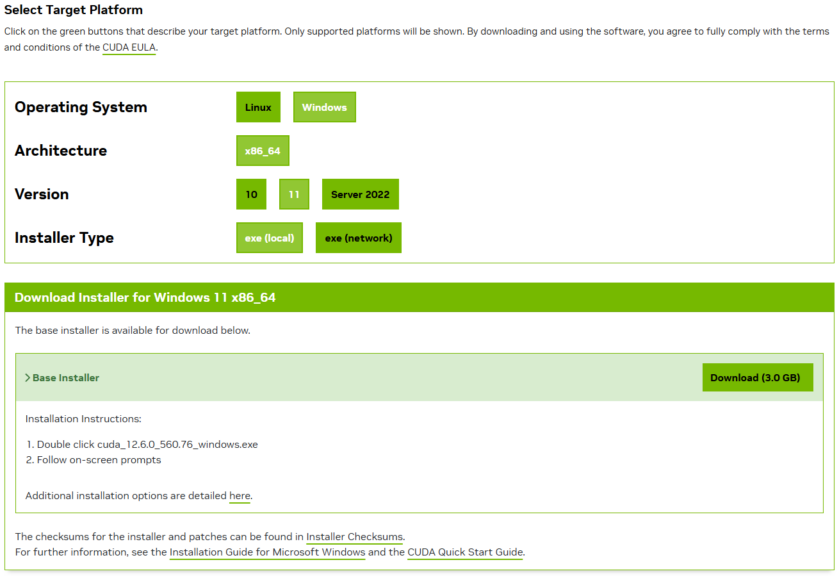
▼インストーラを実行後、インストールが始まりました。
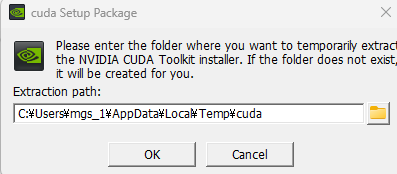
▼古いバージョンのドライバーをインストールしようとしていると表示されていましたが、続行しました。
その後は特に問題なくインストールできました。
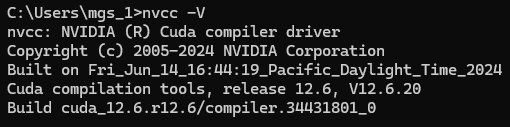
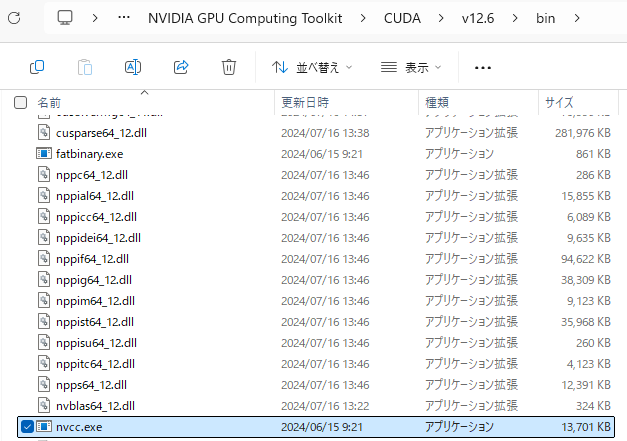
▼この後nvcc -Vを実行すると、バージョンが表示されました。
▼VS Codeのターミナルは、VS Codeを再起動しないと認識していないままでした。

▼Program Filesを辿っていくとnvcc.exeがあって、直接絶対パスを指定して-Vを実行しても表示されました。まだパスに追加されていないような状態であれば、こちらで指定する方が確実かもしれません。
YOLOの物体検出を試してみる
CUDAのインストールは完了したので、Pythonの環境を構築して物体検出を試してみました。
▼UltralyticsのYOLOのPredictに関するページはこちら
https://docs.ultralytics.com/ja/modes/predict
▼以前の記事でも試していた、Pythonの物体検出のプログラムをもとに試してみました。
YOLOで物体検出 その2(Python、Node-RED)
はじめに 今回はYOLOをPythonで実行してみました。 以前の記事でYOLOを試したときは簡単なコマンドしか試していませんでしたが、実際にロボットに搭載して処理を行う…
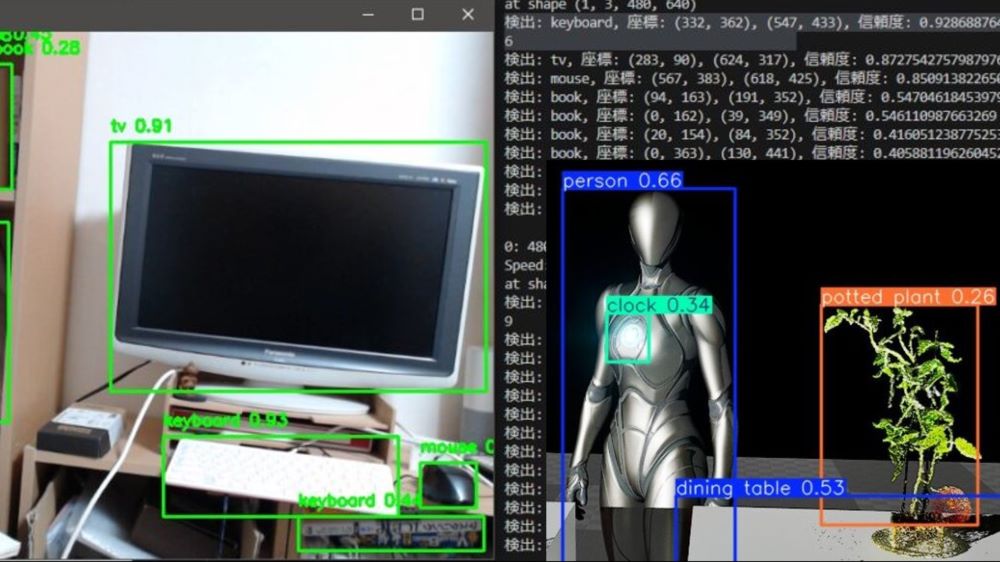
▼Unreal Engineの画面ですが、この画像で物体検出を行ってみました。

Unreal Engine 5を使ってみる その10(Scaniverse、点群データの取り込み)
はじめに 今回はiPhone 15 ProでScaniverseというアプリを使って3Dスキャンしたデータを、Unreal Engine 5(UE5)に取り込んでみました。 データを取り込むにあたって…

以下のコマンドでPython 3.10の仮想環境を作成し、ultralyticsをインストールしました。
py -3.10 -m venv yolo310
cd yolo310
.\Scripts\activate
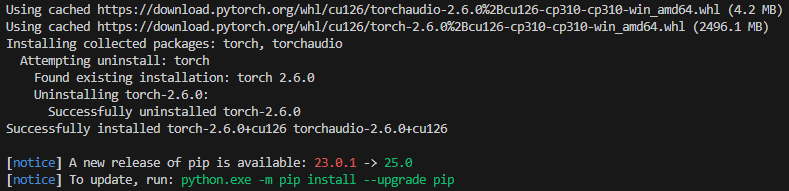
pip install ultralyticsPyTorchのページで確認したコマンドで、必要なパッケージをインストールしました。
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126▼インストールが完了しました。
プログラムを実行してみました。
▼画像ファイルから物体検出を行うプログラムはこちら。画像ファイルのパスは変更してください。
from ultralytics import YOLO
model = YOLO("yolov8n.pt")
results = model.predict(source="<画像ファイルの絶対パス>", save=True, device='cuda:0')▼NotImplementedError: Could not run 'torchvision::nms' with arguments from the 'CUDA' backendというエラーが出ていました。
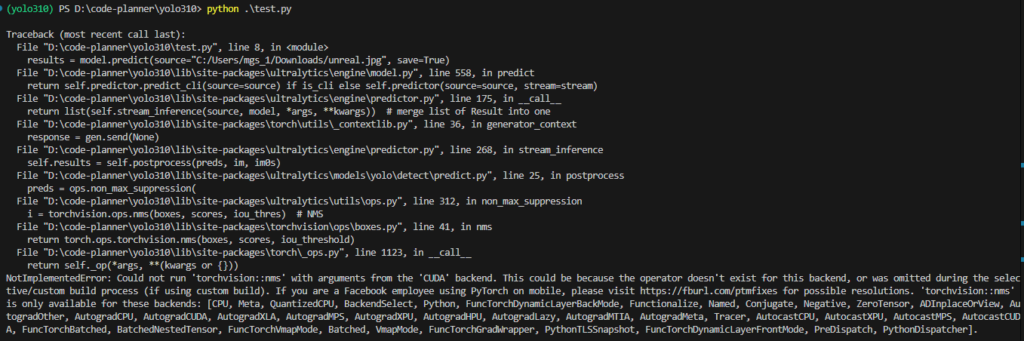
▼device='cpu'にすると実行できました。
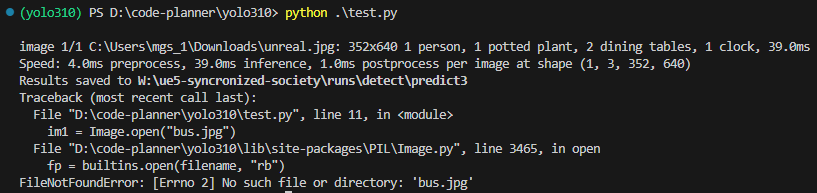
そもそもtorchが有効なのかを、Pythonの対話モードで確認しておきました。
python
import torch
torch.cuda.is_available()▼Trueと表示されています。

なお、対話モードはexit()で終了することができます。
先程のエラーについてChatGPTに聞いてみたのですが、一度torchvisionをアンインストールしてから再インストールすることを提案されたので試してみました。
以下のコマンドを実行しました。
pip uninstall torchvision
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu126▼uninstall時に実行するか聞かれました。
その後、先程のプログラムを実行してみました。
▼実行できました!

▼検出もできています。
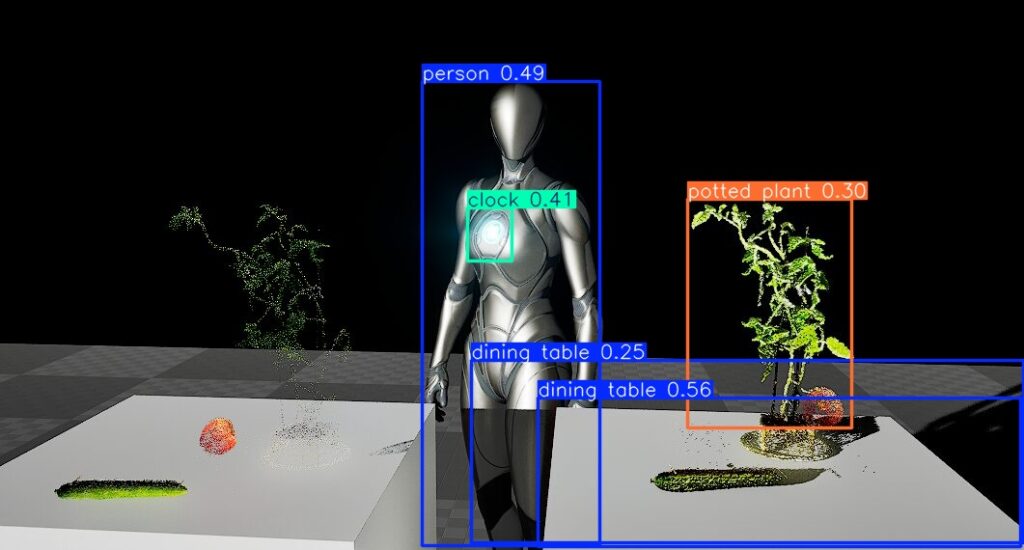
▼device='cpu'で実行したときの時間と比較すると、GPUの方が遅い?ようです。

画像一枚だけなので、枚数を増やしたり、リアルタイムでの検出だと変わってくるかもしれません。
YOLOの学習を試してみる
今までCPUでデータセットの学習を行っていたのですが、GPUでも試してみました。
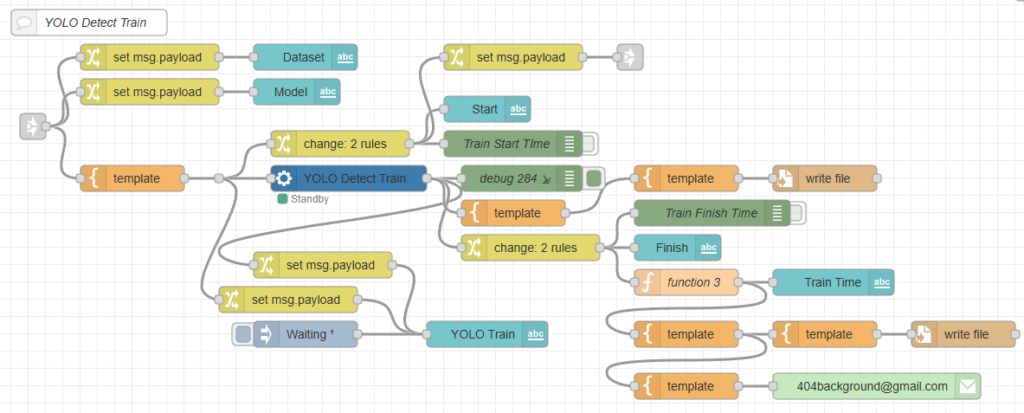
私はYOLOの学習をNode-REDで自動化していて、Pythonのコードではなくyolo.exeを使ったコマンドで学習を行っています。
▼以下のようなフローで学習を行っています。私が開発したpython-venvノードのうち、仮想環境の実行ファイルを実行するvenv-execノードを使っています。
▼学習に必要なデータセットのアノテーションについては、以下の記事でも試しました。
CVATでアノテーション(YOLO v8、Object Detection)
はじめに 今回はCVAT(Computer Vision Annotation Tool)でアノテーションを行ってみました。 画像に対してアノテーションを行い、YOLOで学習することで物体を検出でき…
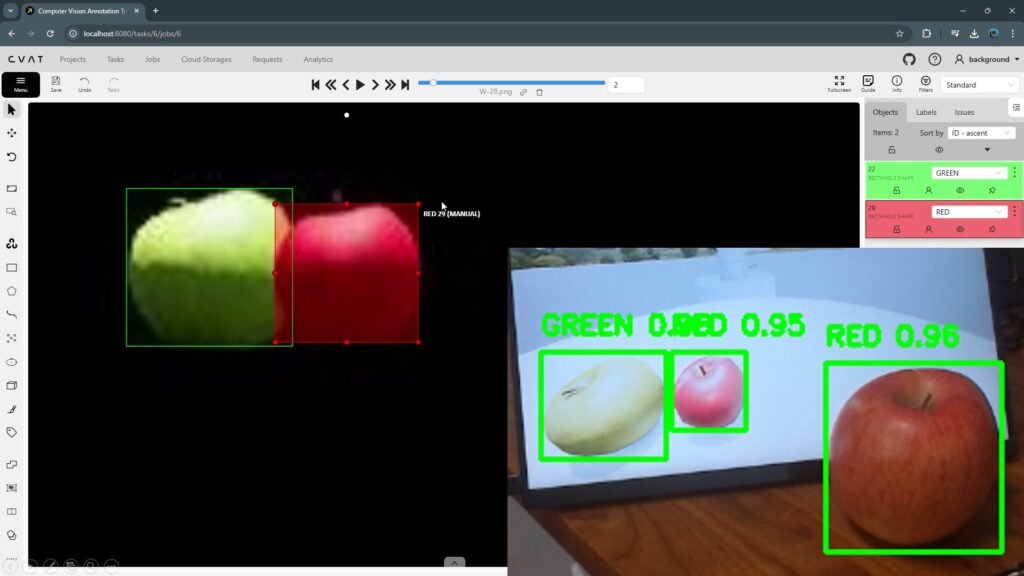
GPUを指定するためにdevice='cuda:0'にすると、エラーが出ていました。
▼device=0だと実行できるようでした。

device=0にして以下のようなコマンドで実行してみたのですが、エラーが出ました。
yolo.exe detect train data=<data.yamlのパス> model=<モデルのパス> name=<保存先のパス> device="0"▼OSErrorが起きています。
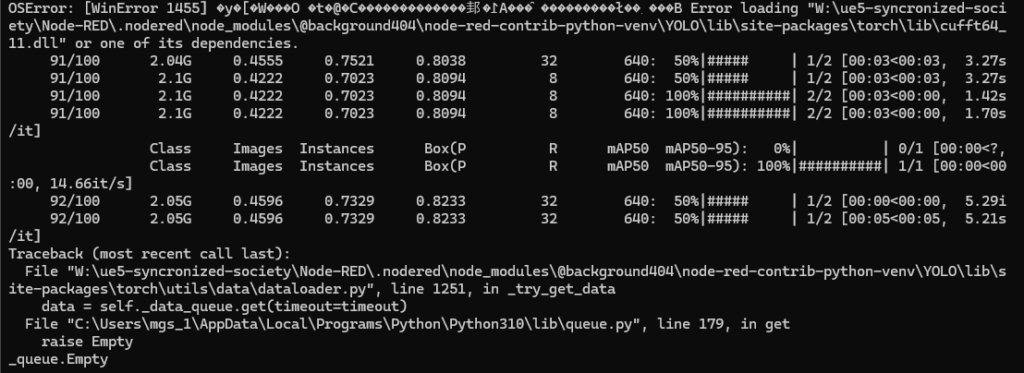
ChatGPTに聞いてみると、workers=0を入れると解決すると返ってきました。
以下のコマンドであれば問題なく学習できました。
yolo.exe detect train data=<data.yamlのパス> model=<モデルのパス> name=<保存先のパス> device="0" workers=0▼学習結果の入ったフォルダに、results.csvがあります。
▼学習の累積時間が出てくるので、その時間で比較しました。
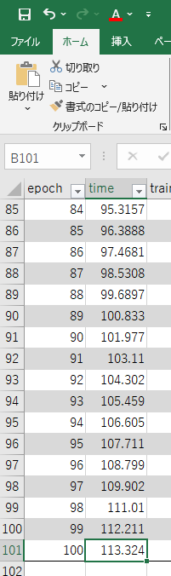
26枚の画像しか入っていない小さいデータセットですが、CPUの場合は523.822、GPUの場合113.324でした。CPUでは8分44秒ぐらい、GPUでは1分53秒ぐらいですね。
Node-REDのフローで、ボタンを押してから学習が終了するまでにかかった時間を計算して、メールで送信するようにしています。その数字とも大体一致していました。
▼以下のようにメールが届きます。
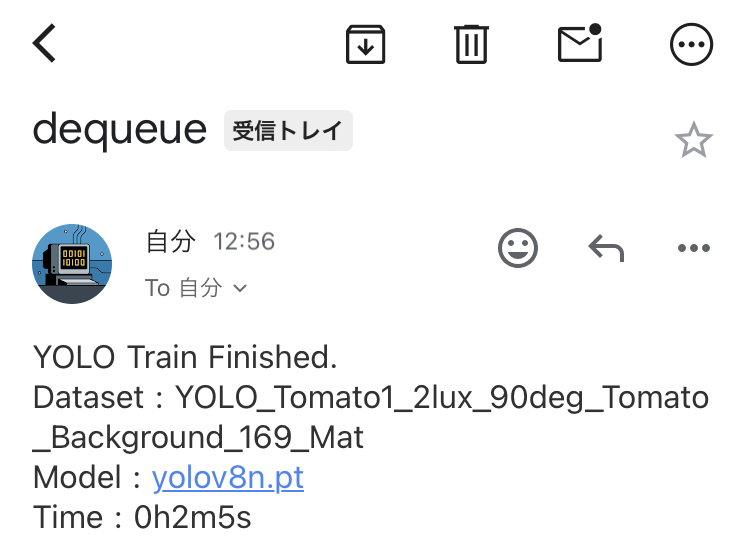
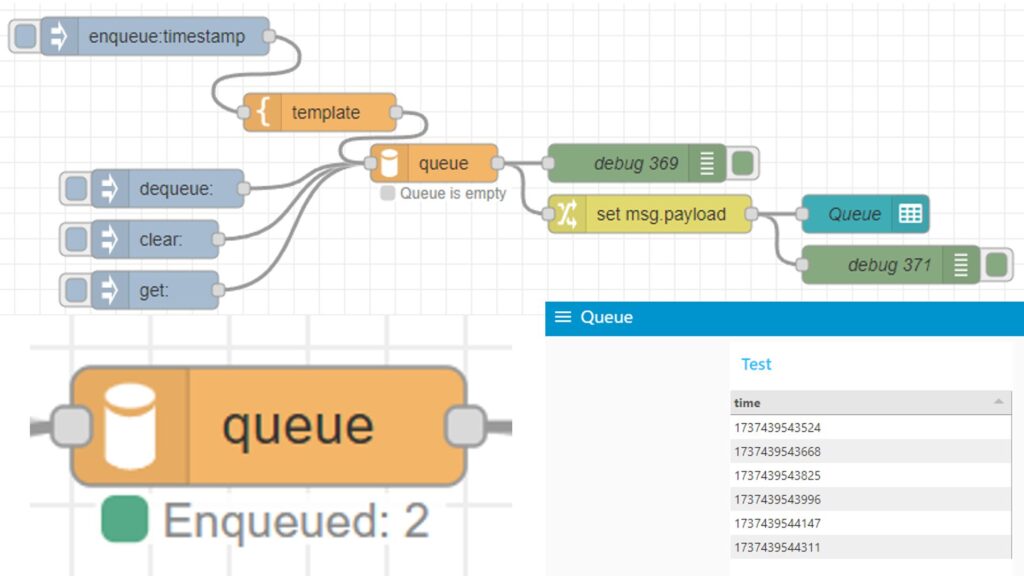
▼以前学習の順番待ちができるように、queueノードも開発しました。
Node-REDのノードを開発してみる その3(queueノード)
はじめに 今回はNode-REDでキューを扱うことができるqueueノードを開発してみました。 普段から研究で物体検出をするためにYOLOを利用しているのですが、データセット…
最後に
pipでtorchvisionを一度削除してから、再インストールするとうまくいくようでした。WSLのUbuntu環境だと特に問題なく実行できたという話も聞いたので、そちらの方が簡単にできるかもしれません。
検出時間は画像一枚だとCPUの方が速そうでしたが、学習ではGPUの方が4倍ぐらい速かったです。リアルタイムでの検出でもどういった違いが出るのか試したいなと思っています。
私はUnreal Engine と併用しているので、GPUの利用率が既に高いとYOLOが遅くなるかもしれません。