CVATでアノテーション(YOLO v8、Object Detection)
はじめに
今回はCVAT(Computer Vision Annotation Tool)でアノテーションを行ってみました。
画像に対してアノテーションを行い、YOLOで学習することで物体を検出できるようになります。ロボットの画像処理に利用しようと思っています。
なお、検出対象はUnreal Engine 5で撮影したMegascansのリンゴを対象にしています。対象は違いますが、研究でも物体検出に取り組んでいます。
▼Unreal Engine 5での撮影はこちらの記事のように行っています。
Unreal Engine 5を使ってみる その12(Screenshot )
はじめに 今回はUnreal Engine 5(UE5)のスクリーンショットを試してみました。 シミュレーション内で撮影することで、YOLOのデータセットを作成できそうだなと考えて…

▼以前の記事はこちら
Unreal Engine 5を使ってみる その10(Scaniverse、点群データの取り込み)
はじめに 今回はiPhone 15 ProでScaniverseというアプリを使って3Dスキャンしたデータを、Unreal Engine 5(UE5)に取り込んでみました。 データを取り込むにあたって…

YOLOで物体検出 その3(ROSとの連携、WSL2 Ubuntu 18.04)
はじめに 今回はWSL2のUbuntu18.04でYOLOとROSを連携させてみました。 実際にYOLOで物体を検出し、その検出した位置にロボットを動かすために使われていました。リア…

関連情報
アノテーションツールはいろいろあって、LabelImgやLabelStudioを論文でよく見かけます。
▼LabelImgはこちら。Public Archiveになり、現在はLabelStudioの一部になっているようです。
https://github.com/HumanSignal/labelImg
▼LabelStudioはこちら
今回はCVATを利用します。チームで作業を行うことができて、実際使っているとアノテーションに便利な機能がありました。
▼CVATはこちら
▼例えば長方形で物体を囲むときに、マウスの位置に十字の線が表示されます。こういった表示があるだけで全然違います。

▼今回は触れていませんが、セマンティックセグメンテーションを利用するためにアノテーションを行ったときは、OpenCVが補助してくれて便利でした。

環境を構築する
普段使っているノートPCで環境を構築しました。
▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


▼以下のページを参考に進めました。
https://docs.cvat.ai/docs/administration/basics/installation/#windows-10
まずは必要なソフトウェアをインストールします。
▼Docker Desktopはこちら
▼Gitはこちら
今回はWSL2でUbuntu 22.04をインストールして実行します。PowerShellを管理者権限で開き、以下のコマンドを実行してください。
wsl.exe --install Ubuntu-22.04▼WSL2でのUbuntu 22.04のインストールについては、以下にも書いています。再インストールしていたりするとややこしいです。
WSL2を使ってみる その1(Ubuntu 22.04、Node-RED、メモリ制限)
はじめに 今回はWindows環境でLinuxディストリビューションをインストールできる、WSL(Windows Subsystem for Linux)の環境を構築してみました。 最近オープンソー…
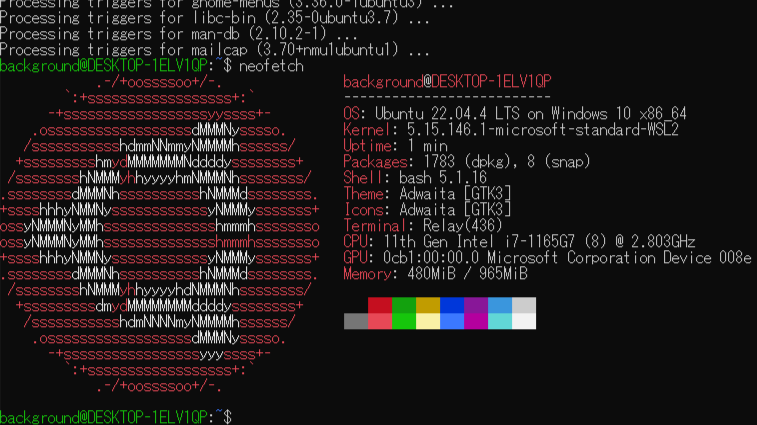
インストールが完了したら、Docker Desktopの設定を行います。
▼Settingsを選択します。

▼ResourcesにWSL integrationがあるので、Ubuntu-22.04を有効にします。
その後、Apply &restartを選択しました。
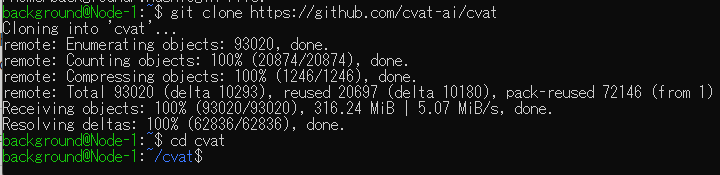
Ubuntu 22.04のターミナルを起動して、CVATのインストールを行います。以下のコマンドを順に実行しました。
git clone https://github.com/cvat-ai/cvat
cd cvat
docker compose up -d
sudo docker exec -it cvat_server bash -ic 'python3 ~/manage.py createsuperuser'▼リポジトリをクローンして、cvatに移動しました。
▼docker composeを実行しました。この処理は時間がかかりました。
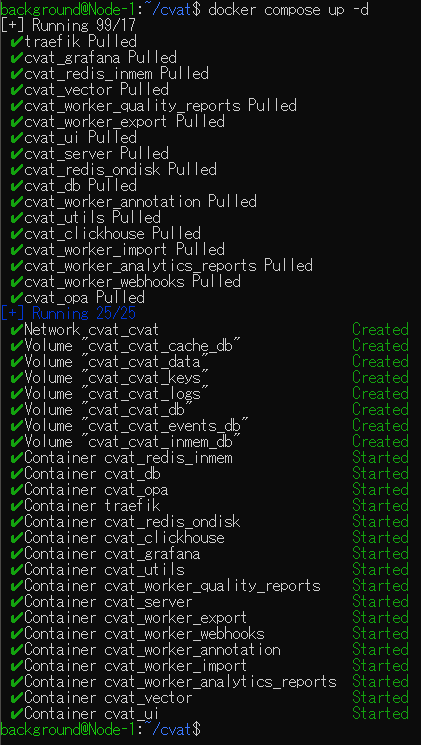
▼最後のコマンドを実行後、ユーザー名とパスワードが聞かれました。この後CVATにログインするときに必要です。

ブラウザでhttp://localhost:8080にアクセスします。
▼CVATの画面が表示されました。
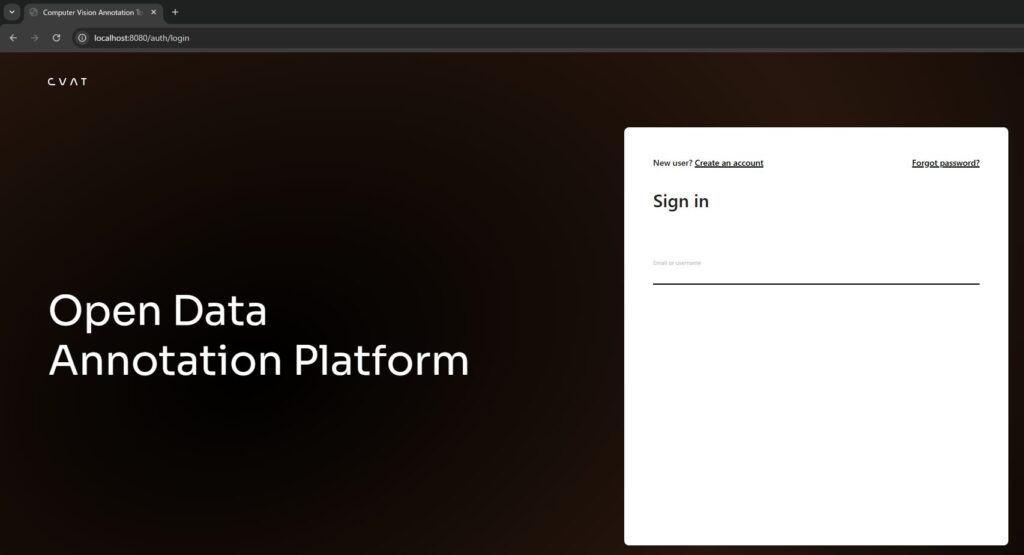
▼ログイン後、ProjectsやTasksを選択する画面に移行しました。
この後PCを再起動してからDocker Desktopを起動しても、アクセスできないことがありました。CVATをDocker Desktopで再起動する必要がありました。
▼Actionsの四角形のマークで一旦終了すると、再起動できます。
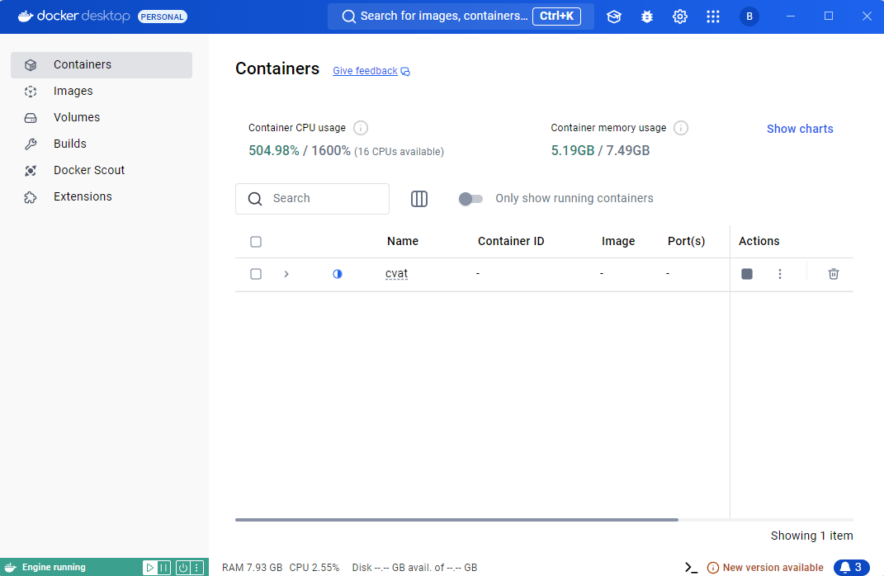
▼正常に起動していると、Running状態になっています。
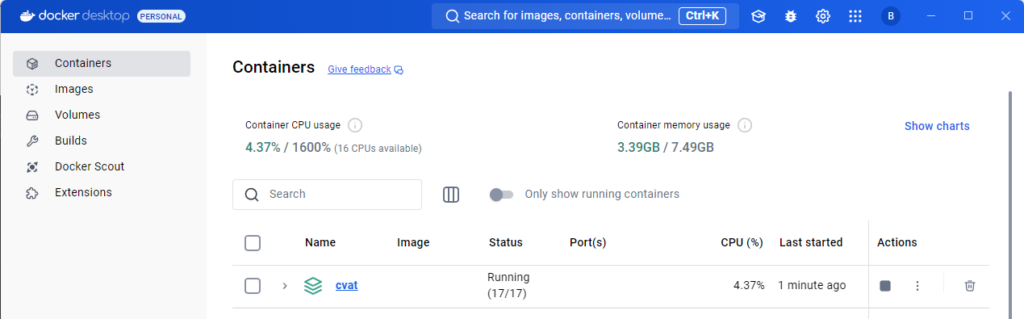
アノテーションを行う
プロジェクトとタスクの作成
アノテーションを行う前に、プロジェクトとタスクを作成する必要があります。
まずはプロジェクトを作成します。
▼Create a new projectを選択します。
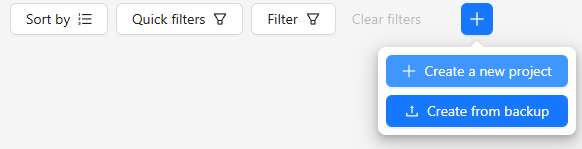
▼プロジェクト名を入力しました。
Constructorで検出したい物体の種類を設定します。
▼REDとGREENを追加しました。

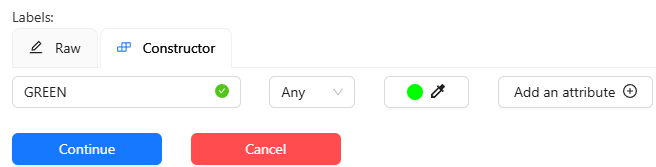
Submit & Openを選択して設定を終了しました。
▼プロジェクトの画面が開きました。
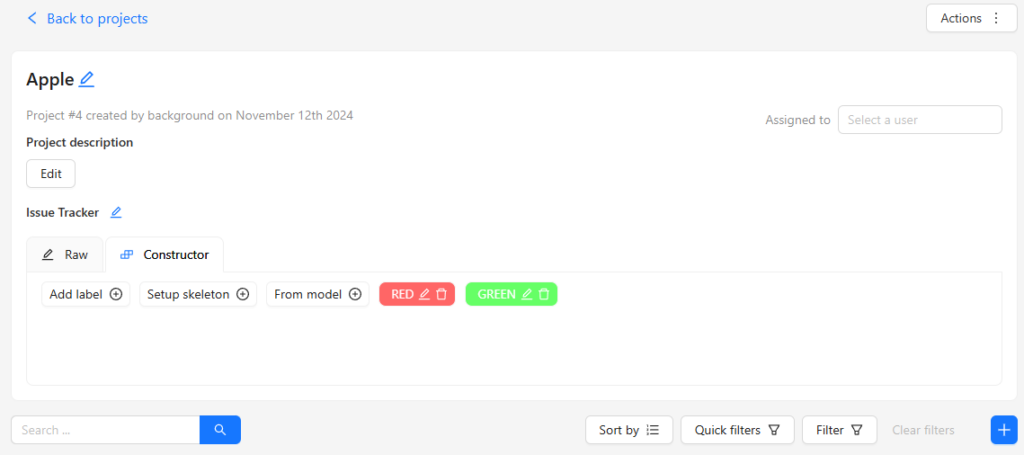
次にタスクを追加します。
▼プロジェクトのプラスのマークのボタンを選択します。
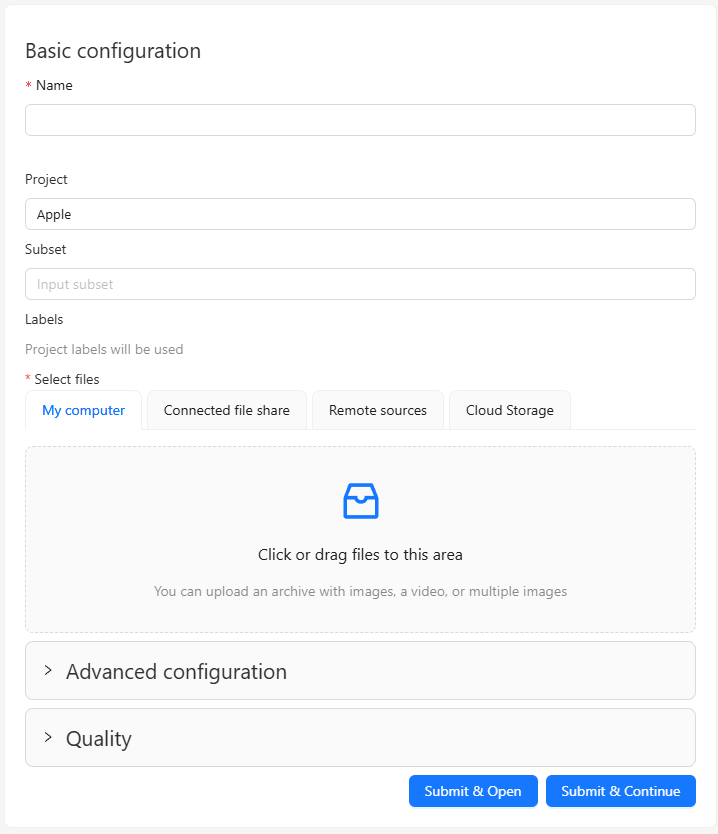
▼タスクの設定画面になりました。
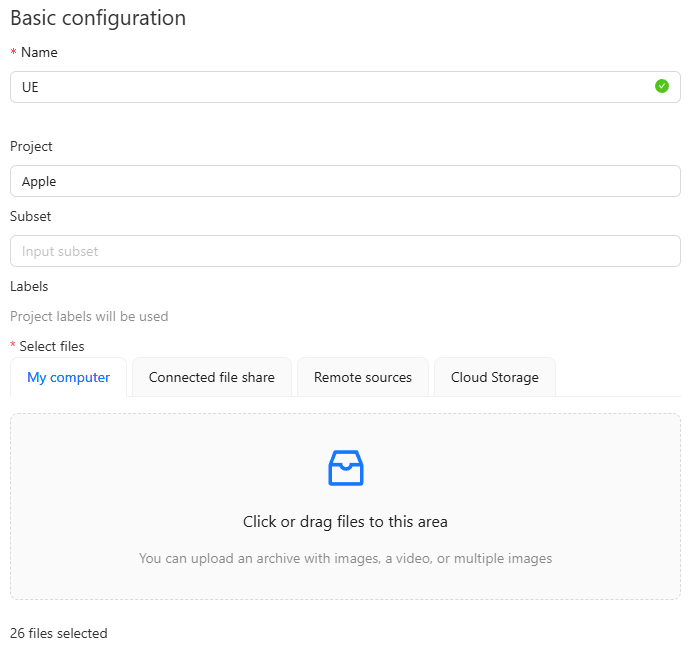
▼UEという名前にしました。画像はアップロードしても表示されませんが、枚数だけ表示されています。
▼作成後、Jobとして追加されます。
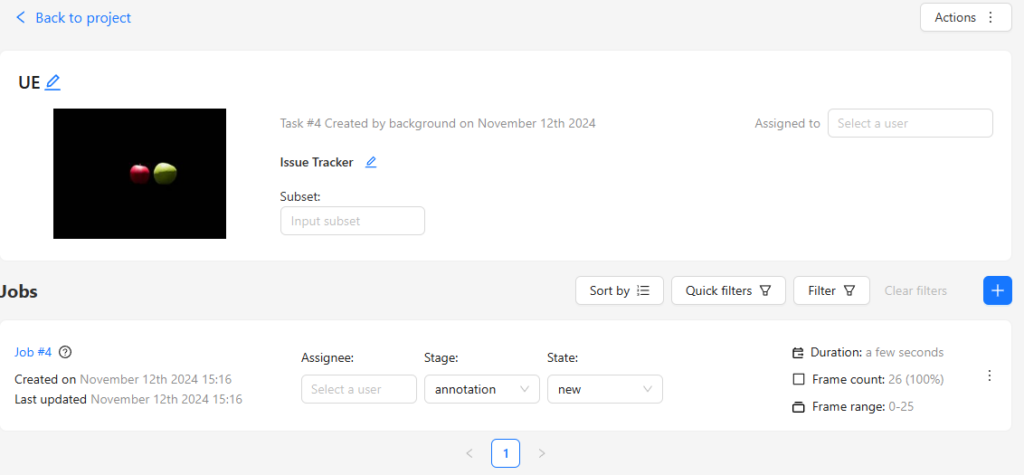
アノテーションを行う
Jobを選択すると、アノテーションを行う画面になります。
▼以下のように表示されました。
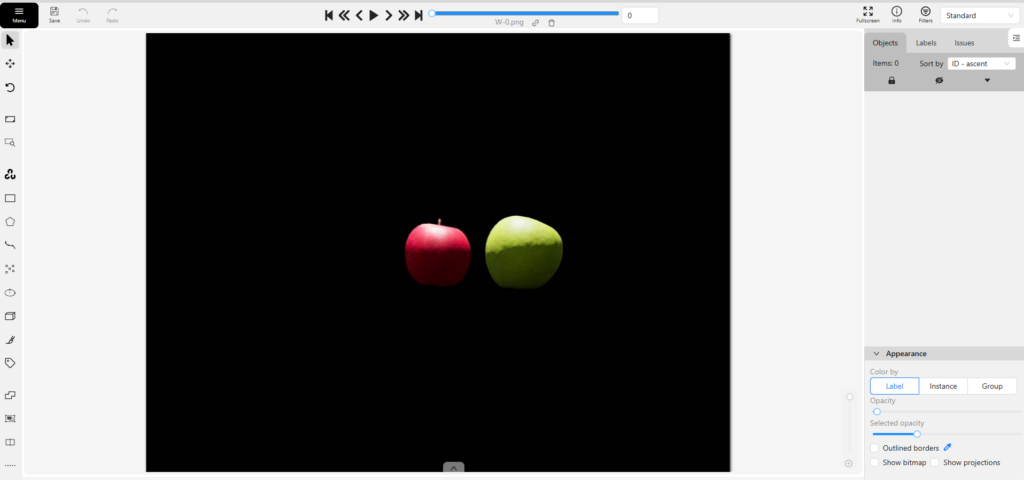
左側にアノテーションを行うためのツールが用意されています。今回は物体検出を行いたいので、長方形のバウンディングボックスを作成しました。
▼ラベルを選択して、Shapeを選択しました。
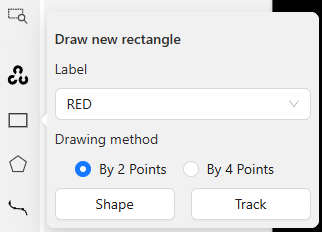
画像上にマウスを持ってくると、十字線が表示されます。
▼物体を囲む位置でクリックします。

▼REDとしてオブジェクトが追加されました。
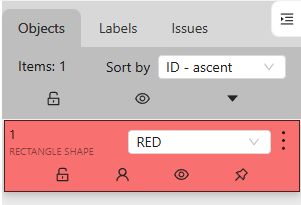
▼連続で行うときは、キーボードのNを入力すると再度描くことができます。
▼GREENも囲んでみました。

▼次の画像に移動するときはキーボードのFを入力するか矢印を選択します。
この辺りのキーボード操作に慣れると、アノテーションを素早く行うことができます。
▼実際にアノテーションを行っている様子はこんな感じです。
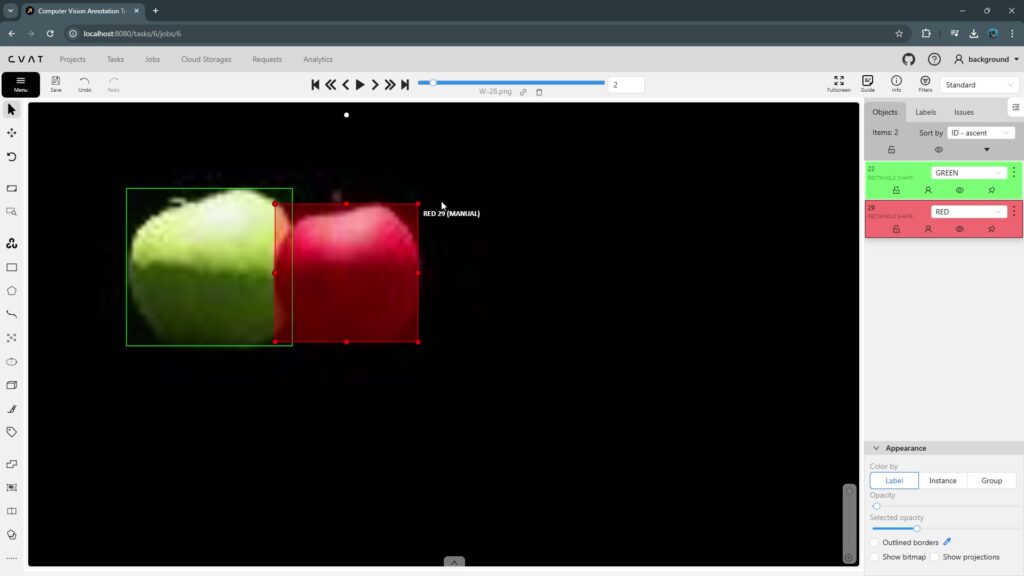
▼以下のように囲むことができました。
アノテーションが終わると、データセットとしてエクスポートします。
▼Tasksの画面に戻って、ActionsのExport task datasetを選択します。

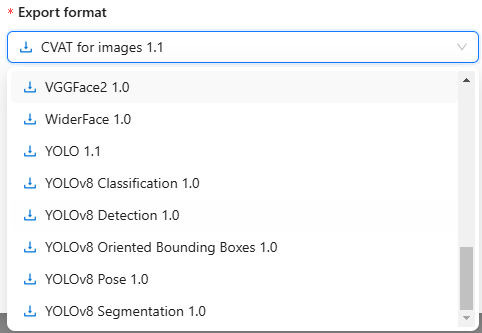
▼データセットの形式を選択できます。
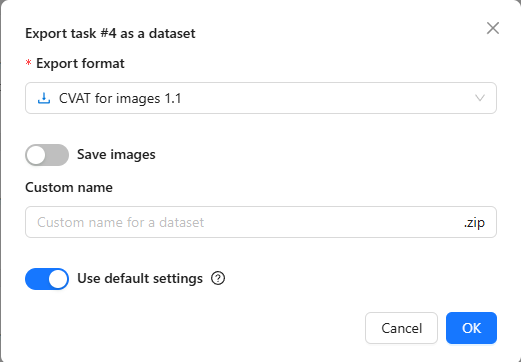
Save imagesはオンにしておきました。フォーマットはYOLOv8 Detection 1.0にしました。
▼YOLOv8のPoseやSegmentationもあります。
▼エクスポートの処理が終了後、Requestsの欄からデータセットをダウンロードできます。

▼データセットをダウンロードできました。
この後ultralyticsパッケージのYOLOで学習するのですが、以下のようなエラーが出ました。
▼trainとvalが必要というエラーです。
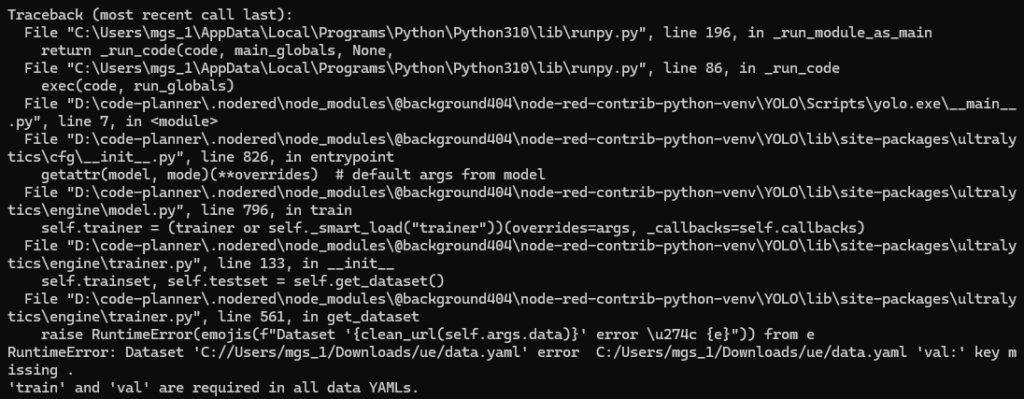
CVATで出力したデータ形式ではそもそもvalフォルダが無く、YOLOの学習には対応していないようでした。
今回は手動でtrainフォルダとvalフォルダにそれぞれ8対2の割合でデータを移動しました。もちろん、データセットのパスを渡してPythonで処理するといったことも可能です。
▼以下のように変更します。
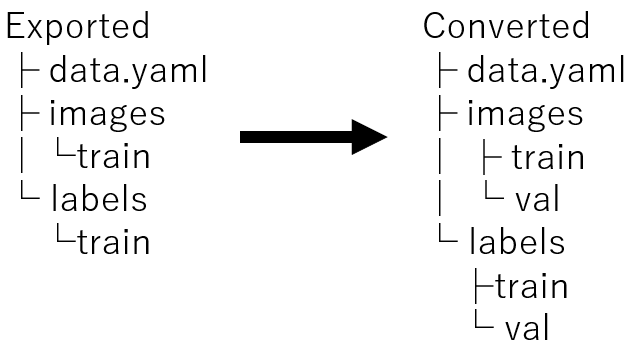
▼別のデータセットですが、以下のような構造になりました。
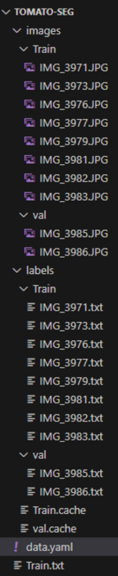
data.yamlは以下のような形式にしました。絶対パスはお使いの環境に合わせて変更してください。
names:
0: RED
1: GREEN
train: <images/trainフォルダの絶対パス>
val: <images/valフォルダの絶対パス>以下のような形式でも学習できました。
names:
0: RED
1: GREEN
path: <データセットの絶対パス>
train: images/train
val: images/valYOLOで学習する
YOLOのTrainモードで学習を行います。予めpipでultralyticsパッケージをインストールしておいてください。
▼UltralyticsのYOLOでのTrainに関するページはこちら
https://docs.ultralytics.com/modes/train
学習は以下のコマンドを実行するだけです。先程エクスポートしたデータセットの中にあるdata.yamlの絶対パスを指定してください。
yolo detect train data=<data.yamlの絶対パス> model=yolov8n.ptデータセットの画像の枚数が多かったり、パラメータの多いモデルを利用すると学習に時間がかかります。
私のPCのCPUであるRyzen 7の処理で、学習画像が100枚ぐらいだとYOLO v8nで1時間ぐらい、YOLO v8sだとその2倍ぐらいかかりました。
学習後、コマンドを実行したターミナルに出力結果が保存されているフォルダが表示されます。デフォルトでは実行ディレクトリのruns/detectフォルダに学習後のデータが入っています。
▼best.ptを後で利用します。

物体を検出してみる
PCの画面に対して、USBカメラで検出できるか試してみました。
▼方法はPythonでYOLOを実行したときの記事をご覧ください。
YOLOで物体検出 その2(Python、Node-RED)
はじめに 今回はYOLOをPythonで実行してみました。 以前の記事でYOLOを試したときは簡単なコマンドしか試していませんでしたが、実際にロボットに搭載して処理を行う…
▼UE5の画面。誤検出が多いです。

▼精度は低いですが、検出しています。
▼PCのアイコンを誤検出していました。
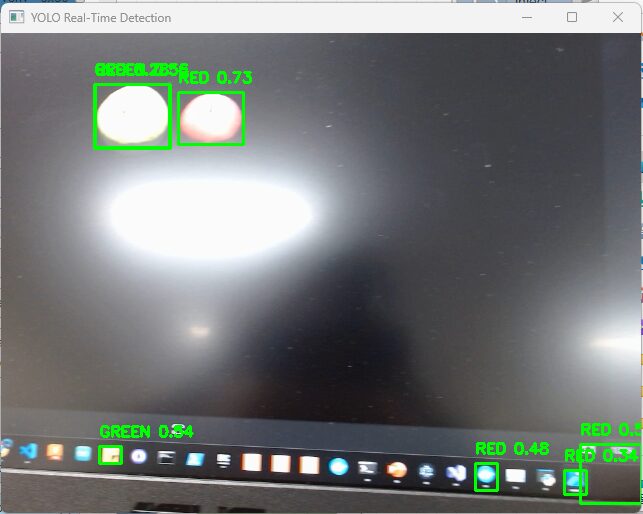
▼現実のリンゴも検出できました。しかし距離を変えると、検出できないことがありました。大きすぎるのかもしれません。


最後に
アノテーションさえできれば、YOLOの学習は簡単にできました。ロボットのカメラによる物体検出にも利用できそうです。
マイコンなどの簡単な処理を行うコンピュータで撮影を行い、通信してサーバー側で画像処理を行うという構成を試したいなと思っています。
▼ちなみに、Unreal Engine 5のPixel Streamingと組み合わせると、ゲームの画面に対してYOLOで物体検出を行うことができます。
Unreal Engine 5を使ってみる その11(Pixel Streaming )
はじめに 今回はUnreal Engine(UE)のPixel Streamingプラグインを利用して、ゲーム画面をストリーミングしてみました。 同じネットワークに接続している端末で、ブラ…

▼年末にQiitaに書いた記事でも少し触れています。
https://qiita.com/background/items/c0d5b0a744fdd2365fd1