NVIDIA Isaac Labを試してみる その2(強化学習のサンプル実行、Cartpole、Franka)
はじめに
今回はIsaac Labの強化学習のサンプルを2つ試してみました。
強化学習自体はGymnasiumなどでも過去に試していましたが、Isaac Labの場合は3D空間で複数個配置して学習が行われるので面白いですね。私のノートPCでは処理が重くなってしまうのですが、初回だけでも可視化した状態で試しています。
▼PCは10万円ぐらいで購入したゲーミングノートPCを利用しています。Windows 11の環境です。
ちょっと買い物:新しいノートPCとSSDの増設(ASUS TUF Gaming A15)
はじめに 今回はこれまで使っていたPCが壊れたので買い替えましたという話です。 以前はよく分からないGPUが載っていたノートPCを使っていたのですが、最近はUnreal E…


▼Isaac Labの実行環境については、以下の記事で構築しました。
NVIDIA Isaac Labを試してみる その1(環境構築、Windows 11)
はじめに 今回はNVIDIAのIsaac Labの環境構築と起動について試してみました。 Isaac Labはデジタルツインの研究や企業の展示で見聞きしていたのですが、特にGPUの要求…
▼以前の記事はこちら
Genesisを使ってみる その1(環境構築、サンプルプログラムの実行)
はじめに 今回はGenesisという物理シミュレーションソフトウェアを試してみました。 3か月ほど前に公開されたばかりで、デモ動画が面白そうでした。グラフィックはUnr…
MuJoCoを使ってみる その2(Unitree MuJoCo)
はじめに 今回はUnitree MuJoCoのサンプルを試してみました。 最近Unitree関連のロボットを展示会等でもよく見かけます。実機を利用することは難しいですが、せめてシ…
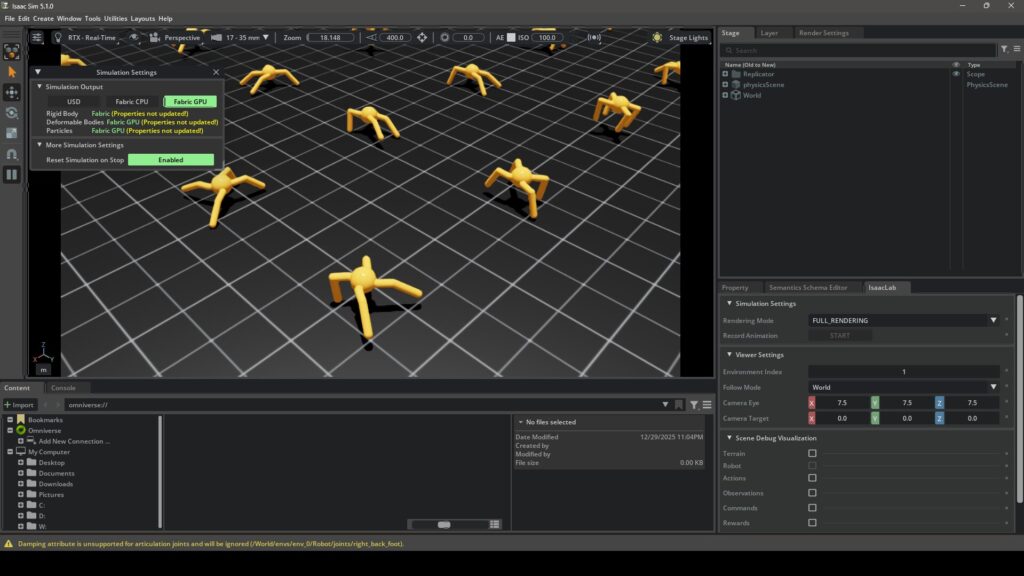
Cartpoleのサンプル実行
まずは処理が比較的軽量と思われる、倒立振り子のサンプルを試してみました。
▼以下のページにIsaac Labで利用できるモデルや環境の一覧があり、その中に倒立振り子のモデルもあります。
https://isaac-sim.github.io/IsaacLab/main/source/overview/environments.html
▼概要が以下のページに書かれていました。
▼学習の実行に関するページはこちら。
▼以前Gymnasiumでも倒立振り子のシミュレーションを行ったことがあるのですが、Isaac Labの場合は3Dモデルのようですね。
Gymnasiumを使ってみる その1(環境構築、サンプルコードの実行)
はじめに 今回はGymnasiumという、強化学習を行うためのソフトウェアを試してみました。 元々OpenAIのGymというソフトウェアがあるのは知っていたのですが、実行でき…
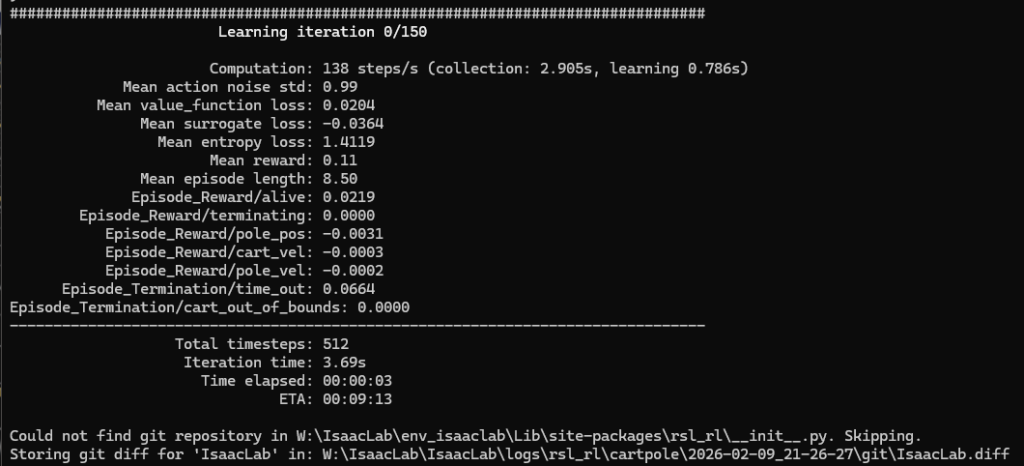
以下のコマンドでtrain.pyを実行しました。
python scripts/reinforcement_learning/rsl_rl/train.py --task Isaac-Cartpole-v0 --num_envs 32▼学習が始まりました。
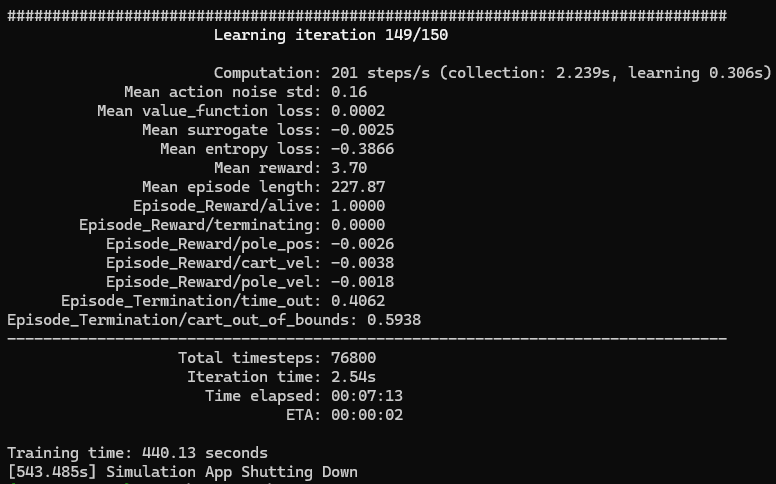
▼学習中の様子はこちら
シミュレーション上に倒立振り子が配置され、学習が始まりました。6分の動画の中で、最初と最後で倒立した振り子の数が変わっている様子が見られました。
▼学習が進んだ影響なのか、後半は直立したものが増えていました。

▼最終的な学習結果はこちら
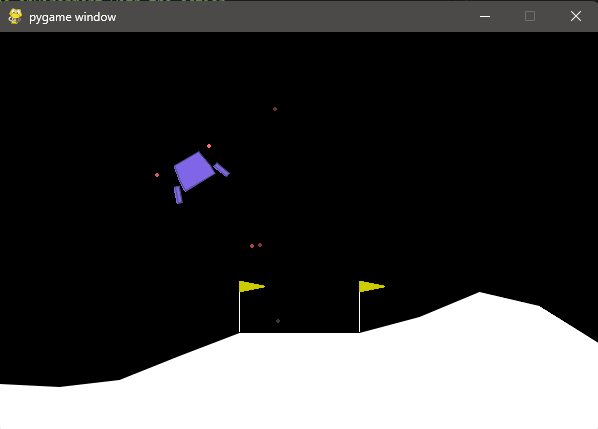
学習後のモデルをもとに、play.pyを実行してみました。
python scripts/reinforcement_learning/rsl_rl/play.py --task Isaac-Cartpole-v0 --num_envs 1▼問題なく起動しました。
▼動作はこんな感じ。
横に流れていくことがあるようですが、倒立した状態を維持できていました。
Frankaのサンプル実行
次に7軸のロボットアームの強化学習を実行してみました。先程の倒立振り子よりも計算負荷が大きいと思われます。
以下のコマンドでtrain.pyを実行しました。
python scripts/reinforcement_learning/rsl_rl/train.py --task Isaac-Reach-Franka-v0 --num_envs 32▼学習中の様子はこちら。目標座標に到達するまで、うねうね動いていますね。
▼影の感じがリアルなのもあって、工場内の実験施設みたいです。

46分ぐらいかけて、学習が終了しました。
▼最終的な学習結果はこちら
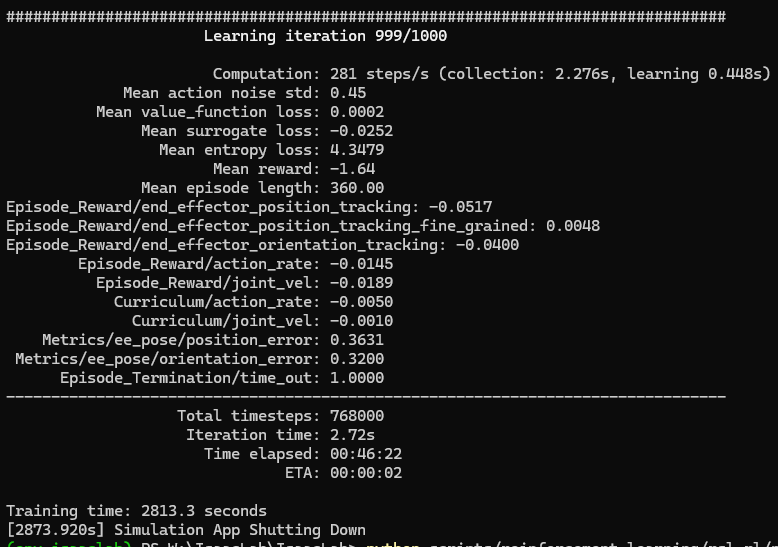
学習済みのモデルでplay.pyを実行してみました。
python scripts/reinforcement_learning/rsl_rl/play.py --task Isaac-Reach-Franka-v0 --num_envs 1▼動作はこんな感じ。
目標の位置に対してあまり接近していないように見えたので、ヘッドレス状態で数を32から128に増やして試してみました。
python scripts/reinforcement_learning/rsl_rl/train.py --task Isaac-Reach-Franka-v0 --num_envs 128 --headless▼最終的な学習結果はこちら
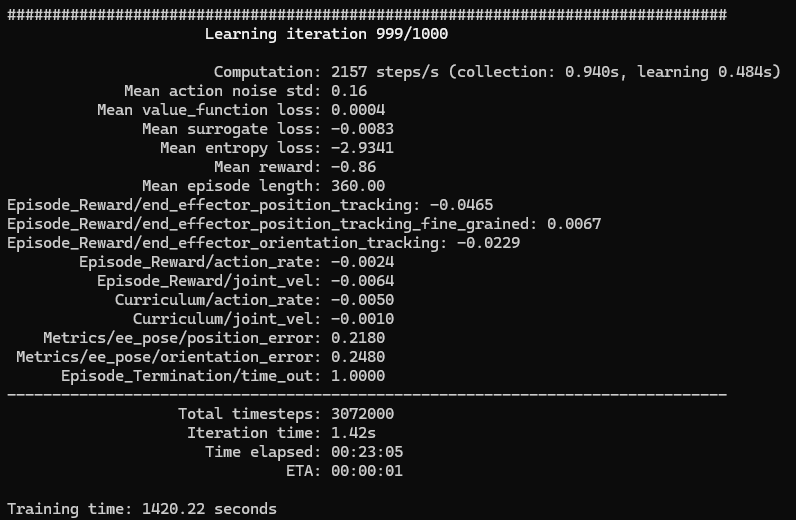
もう一度、play.pyを実行してみました。
▼動作はこんな感じ。
これもあまり目標座標に到達していないように見えたので、Iterationを10倍にして10000に変更してみました。
python scripts/reinforcement_learning/rsl_rl/train.py --task Isaac-Reach-Franka-v0 --num_envs 128 --headless --max_iterations 10000▼Iterationが10000になりました。最終的な学習結果はこちら。
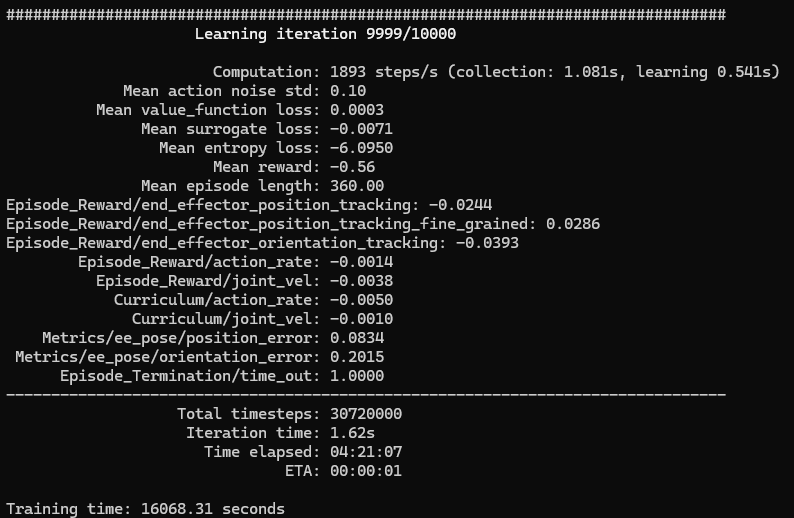
▼これまでよりは目標座標に対して到達できているようでした。
学習時の条件にもよるのか、ロボットの前方や目標座標に近いときは近づいていますが、左右方向や離れているときにはあまり近づかずに、手先の回転だけで終わっているように見られました。さらに学習回数を増やす必要があるのかもしれません。
最後に
倒立振り子と7軸のロボットアームの制御についてサンプルを試してみましたが、やはり条件によって必要な学習量が異なっているのだなと思いました。私が研究で扱っているロボットアームは7軸ではなく4軸や6軸なので、その場合も強化学習で解が得られるのか気になるところです。障害物を避けながらの制御などができたらいいなと思っています。
▼Isaac Labで利用できる環境の中に、部品の組み立てもありました。研究で取り組んでいる農業ロボットの動作もシミュレーションできないか、気になるところです。
https://isaac-sim.github.io/IsaacLab/main/source/overview/environments.html