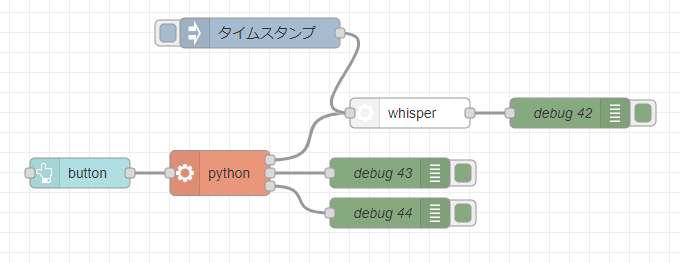
Using OpensAI's Whisper (Speech Recognition, Python)
Introduction
In this article, I used OpenAI's Whisper.
I thought that OpenAI's service was a paid service with an API key, but the source code is available under the MIT License. It is a powerful speech recognition model that supports multiple languages.
I would like to use Whisper to move a robot by giving voice commands. Therefore, I focus on extracting text from short speech.
▼Previous articles are here.
Creating Nodes for Node-RED Part 1 (python-venv)
Introduction I created a node for Node-RED that can use the Python virtual environment. I have created a node for Node-RED MCU before, but this is the seco…

Trying Out ROS2 Part 1 (Environment Setup on Windows)
Info This article is translated from Japanese to English. Introduction In this post, I will be setting up the ROS2 environment. I have tried this several times…

Build the Environment
This time, I build it in a Windows environment.
▼I followed the README in the GitHub repository.
https://github.com/openai/whisper
▼You can install the package with the following command
pip install -U openai-whisper
▼I was wondering about the -U option. It seems to mean Upgrade.
https://kurozumi.github.io/pip/reference/pip_install.html#options
Also, it needed ffmpeg, and there were several install instructions provided. I installed it from the download page for Windows.
▼Here is the download page for ffmpeg.
https://ffmpeg.org/download.html
▼Here is a description of how to add the path.
WindowsにFFmpegをインストールして利用できるようにパスを通す | taziku / 生成AI開発・クリエイティブスタジオ | 東京・名古屋
生成AIでも利用されるFFmpeg。FFmpegとは何か?から、FFmpegダウンロードとインストール手順を順を追って紹介し、動作確認方法までお伝えします。

▼In my case, ffmpeg -version command was already ready to check the version.
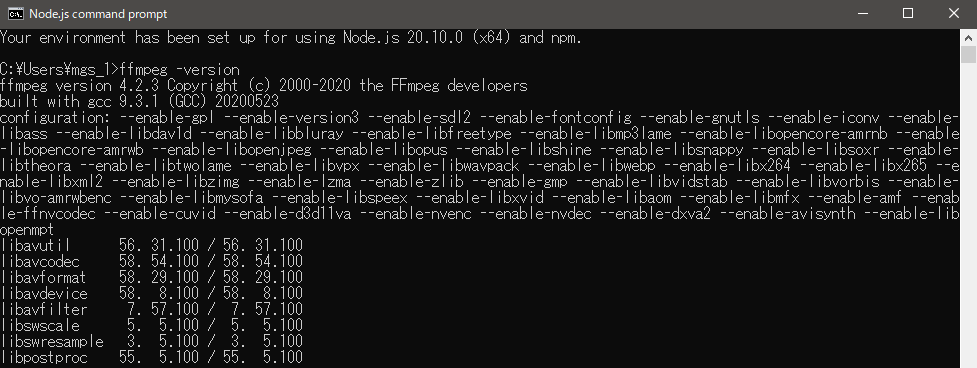
Anyway, I had installed chocolatey when I built ROS2 environment, so I used choco command to install it.
▼Here are the commands for installing chocolatey.
Set-ExecutionPolicy Bypass -Scope Process -Force; [System.Net.ServicePointManager]::SecurityProtocol = [System.Net.ServicePointManager]::SecurityProtocol -bor 3072; iex ((New-Object System.Net.WebClient).DownloadString('https://community.chocolatey.org/install.ps1'))
▼Here is the command to install ffmpeg.
choco install ffmpeg
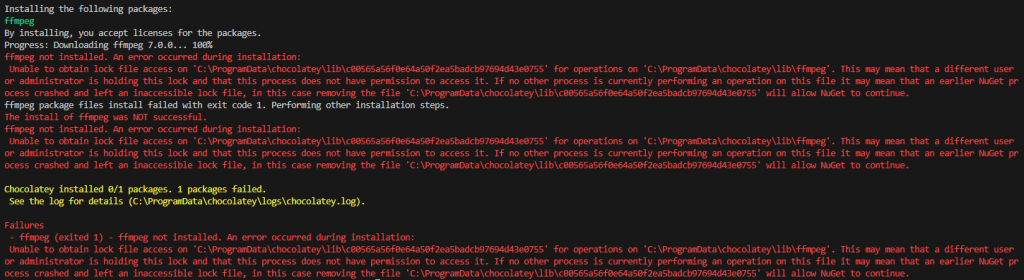
▼When I ran the command, I got an error. Since it was already installed, I could run the program later.
I executed whisper command. It takes a while for the first time because the model has to be loaded.
▼I ran the following command. It is converted to text properly.
whisper <The name of the audio file> --language Japanese

Execute with Python
I found a Python program in the README and ran it.
There were other programs that might be helpful.
▼This program here looked easy to understand with comments.
https://gist.github.com/ThioJoe/e84c4e649857bf0a290b49a2caa670f7
▼This one looks like a program for automatic transcription.
https://github.com/tomchang25/whisper-auto-transcribe
Notes
Note that the name of the file where you save the Python program must be something other than whisper. If the whisper.py file is loaded instead of the installed package, you will get the following error.
▼This is an error that whisper does not have load_model. You have loaded a file with the same name but different contents.
Traceback (most recent call last):
File ".\transcribe.py", line 1, in <module>
import whisper
File "C:\Users\mgs_1\Desktop\github-workspace\node-red-contrib-whisper\whisper.py", line 3, in <module>
model = whisper.load_model("base")
AttributeError: partially initialized module 'whisper' has no attribute 'load_model'
(most likely due to a circular import)
▼It was also discussed here. I did it too…
https://github.com/openai/whisper/discussions/143
Execute the program
This time, I recorded my own voice and tried it out.
▼I speak " mic test mic test."
▼I recorded it near a working 3D printer, and there doesn't seem to be much noise.
▼I executed a simple program first.
import whisper
model = whisper.load_model("base")
result = model.transcribe("マイクテスト.wav", language='japanese')
print(result["text"])▼After execution, the output was in text.

You can select the size of the model with whisper.load_model(). base took about 7 seconds to process, tiny took about 3 seconds.
README also shows the relative speed of the different models. If large, the slowest model, is 1, tiny is 32 times faster and base is 16 times faster.
I guess it would be good to choose one model depending on how you use it. My laptop is not that fast, and I only need to process short sentences, so I think tiny is fine.
However, it seems to be less accurate. I tried other voice recordings, but they turned out to be homonyms or strange sentences in Japanese. But I think homonyms can't be helped…
▼The type of language seems to be written in tokenizer.py.
https://github.com/openai/whisper/blob/main/whisper/tokenizer.py
▼I changed the language from japanese to english and it seemed to change properly.
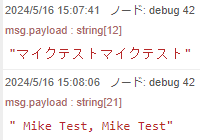
I tried another sample program.
▼The program here seems to be processed by shifting the window every 30 seconds.
import whisper
model = whisper.load_model("base")
# load audio and pad/trim it to fit 30 seconds
audio = whisper.load_audio("マイクテスト.wav")
audio = whisper.pad_or_trim(audio)
# make log-Mel spectrogram and move to the same device as the model
mel = whisper.log_mel_spectrogram(audio).to(model.device)
# detect the spoken language
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
# decode the audio
options = whisper.DecodingOptions()
result = whisper.decode(model, mel, options)
# print the recognized text
print(result.text)
path = 'whisper.tmp'
with open(path, mode='w', encoding='UTF-8') as f:
f.write(result.text)
With this program, the process was slow and sometimes took 50 seconds. It also took a long time to identify the language that was spoken.
It seems to process every 30 seconds, and I guess it is designed to process long audio files. In this case, since it was a short audio file, it does not seem suitable.
I saved the output text to a file at the end. This was tried because when I ran it in Node-RED, the text was displayed broken, so I tried to save it.
▼It is properly displayed in Japanese.
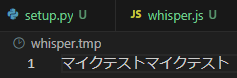
If this file is loaded, it could be displayed in Node-RED without broken characters.
Finally
With tiny, although the processing is fast, it seems to take about 3 seconds. It may be necessary to improve the processing time when real-time performance is required.
▼More examples were noted on the Discussion page. You may find some useful things to look for here.
https://github.com/openai/whisper/discussions/categories/show-and-tell
▼While searching, I found an article on real-time transcription.
▼There is an article on Qiita about speeding up Whisper! It is designed to speed up the process.
https://qiita.com/halhorn/items/d2672eee452ba5eb6241
I guess the disadvantage of running it locally is that it depends on the machine specs. Considering this, I feel that it is well worth paying for the use of the API provided by OpenAI.
Now that I understand roughly how to use it, I'm thinking of making a node for Node-RED later.
▼I already have it in shape, but I'm still thinking about what to do with the options.