Trying Out Ollama Part 6 (Combining Local LLM with Web Search Results using Node-RED)
Introduction
In this post, I combined the Python-based web search functionality I tested previously with a local LLM. I recently learned that the method of supplementing data that an LLM hasn't learned with the latest information from the internet is called RAG (Retrieval-Augmented Generation).
▼IBM's article on RAG (mentions "Agentic RAG" as well):
https://www.ibm.com/jp-ja/think/topics/agentic-rag?mhsrc=ibmsearch_a&mhq=rag
▼AWS's article on RAG:
https://aws.amazon.com/jp/what-is/retrieval-augmented-generation
I’m not entirely sure if my setup qualifies strictly as RAG, but I tested the combination of web search results and a local LLM using Node-RED.
▼Previous articles:
Trying Out Ollama Part 4 (Conversations Between LLMs, Gemma3:4B, Python, Node-RED)
Info This article is translated from Japanese to English. Introduction In this post, I tried using Ollama to facilitate a conversation between two local LLMs.I…

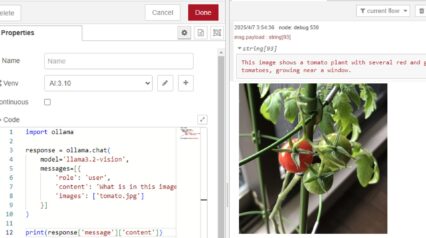
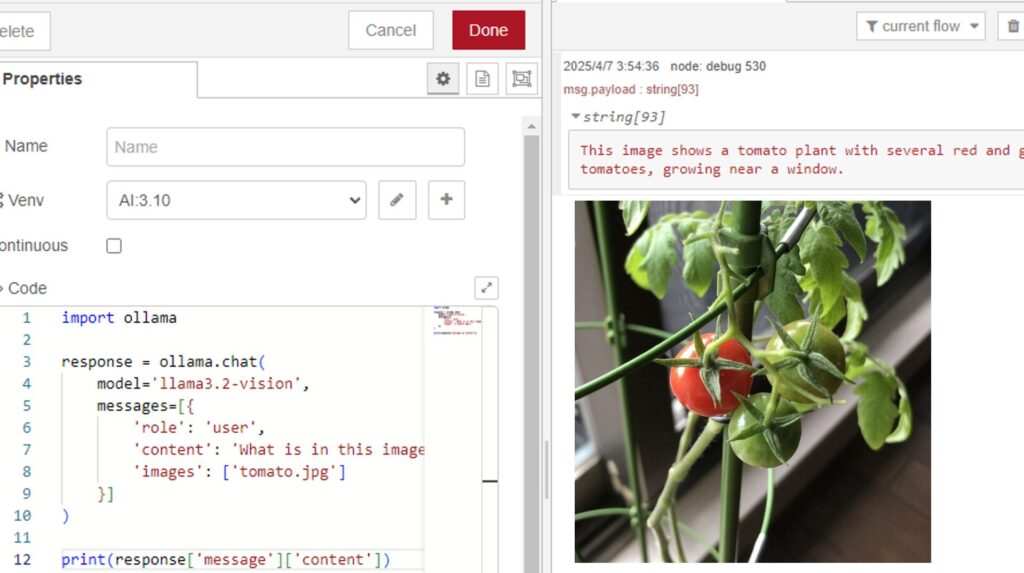
Trying Out Ollama Part 5 (Multimodal Processing of Images and Text with llama3.2-vision)
Info This article is translated from Japanese to English. Introduction In this post, I tried multimodal processing of images and text using llama3.2-vision wit…
Creating the Flow
To run Python in Node-RED, I used the "python-venv" node that I developed. It allows you to create a Python virtual environment and execute code as a Node-RED node.
▼I wrote about the development history at the end of last year (Japanese):
https://qiita.com/background/items/d2e05e8d85427761a609
For the search functionality, I used a Python package that utilizes DuckDuckGo.
▼I used it in this article:
Searching with Python and Summarizing with a Local LLM (Ollama, Node-RED)
Info This article is translated from Japanese to English. Introduction In this post, I experimented with a Python-based search program to automate information …
The local LLM is launched as a TCP server using the Ollama Python library, and it is capable of maintaining conversation history.
▼I used it in this article:
Trying Out Ollama Part 3 (Usage in Python, Node-RED, Gemma 3:4B)
Info This article is translated from Japanese to English. Introduction In this post, I checked how to use Ollama with Python and set it up so that it can be ex…
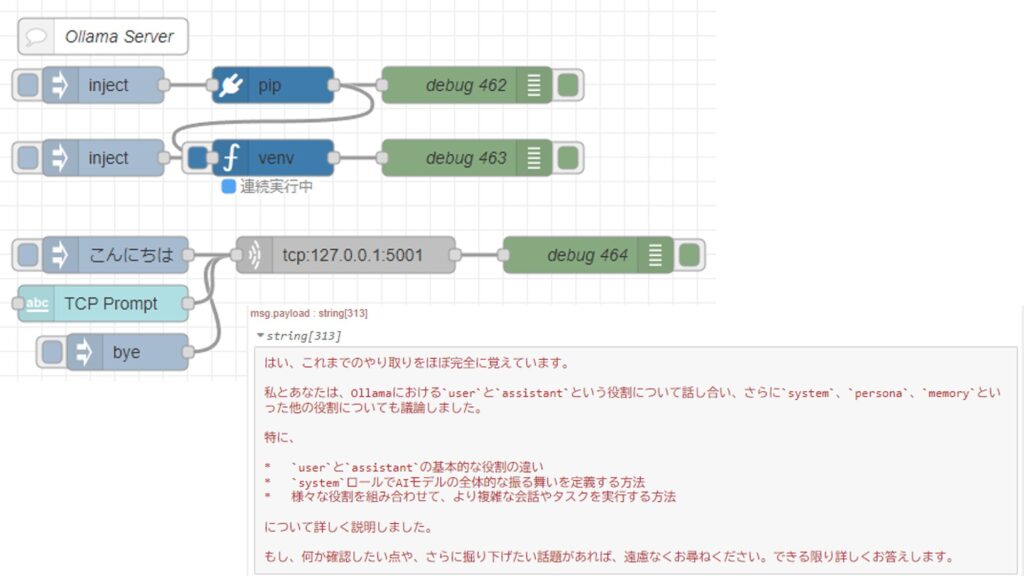
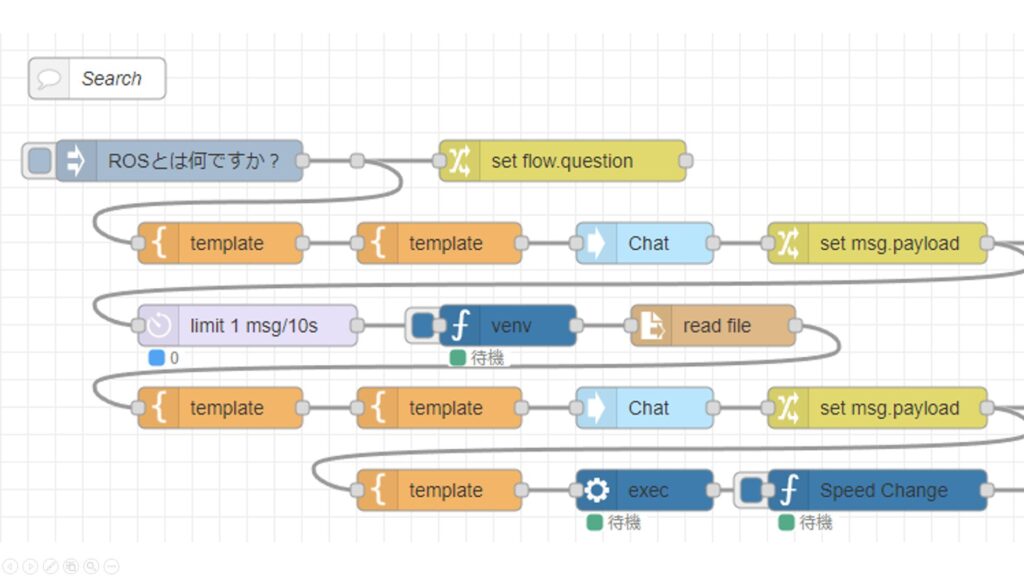
After some trial and error, I ended up with the following flow.
▼Full view of the flow:
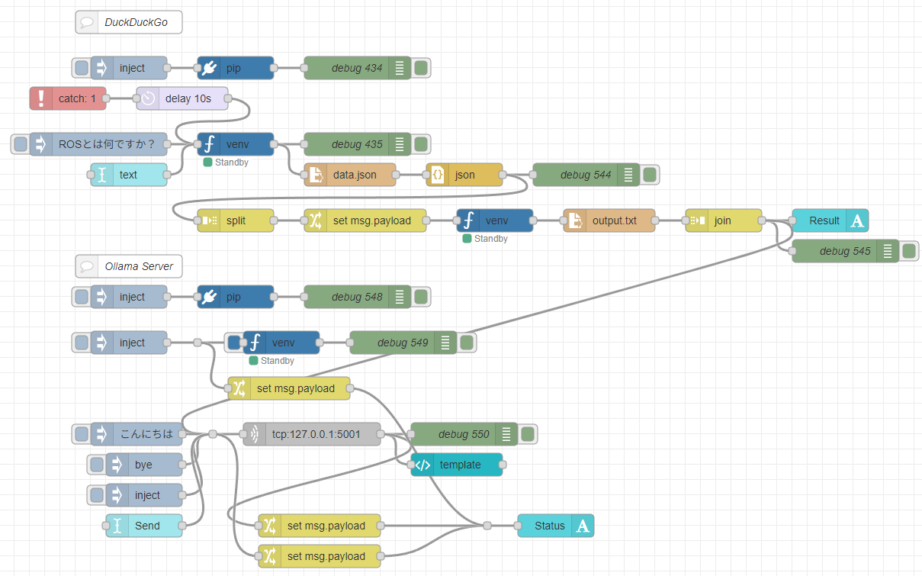
The search results are saved to a JSON file. Since the contents include URLs, the flow reads the necessary information from the linked HTML data and compiles it into a single text file. This file is then sent to the local LLM.
▼This is the kind of content being sent to the local LLM:

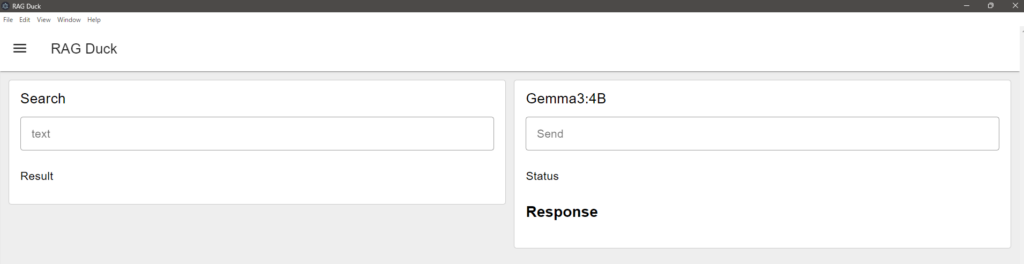
The UI is built using Dashboard 2.0. It allows for both searching and interacting with the local LLM.
▼The dashboard screen looks like this:
Trying It Out
As a test for "new information" that a local LLM likely wouldn't know, I asked about "Genesis," which was only released on GitHub last December.
▼I previously tested Genesis in this article:
Trying Out Genesis Part 1 (Environment Setup and Running Sample Programs)
Info This article is translated from Japanese to English. Introduction In this post, I tried out a physics simulation software called Genesis.It was released o…
I passed the search results for the term "Genesis Simulation" to Gemma3:4B.
▼It successfully summarized the search results.
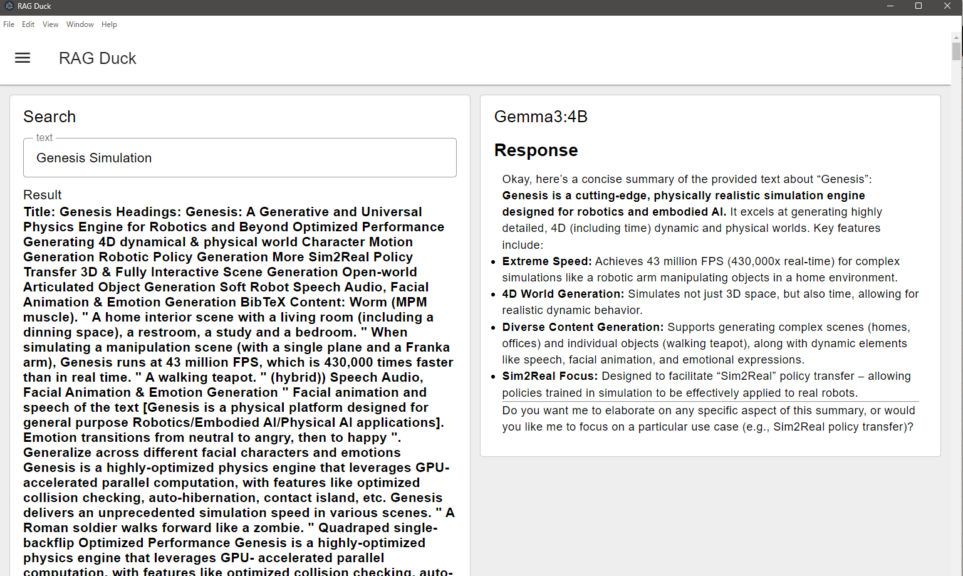
I also made it possible to ask follow-up questions based on these results. Before using the search function, I asked Gemma3:4B if it already knew about Genesis.
▼It suggested something that looked like a mobile game. It clearly didn't know about the simulation engine.

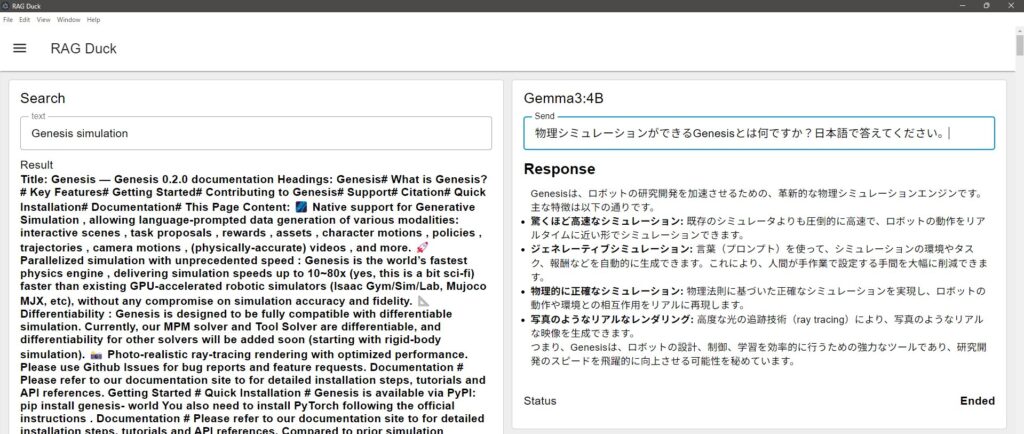
After running the search, I asked the same question.
▼It returned an answer regarding the latest Genesis simulation engine.
I asked ChatGPT the same question for comparison.
▼It suggested something completely different initially.

▼Once the search function was enabled, it returned an answer referencing the latest information.

I also asked about "MuJoCo."
▼I previously tested MuJoCo in this article:
Trying Out MuJoCo Part 1 (Environment Setup and Running Sample Programs)
Info This article is translated from Japanese to English. Introduction In this post, I tried out a software called MuJoCo, which can perform physics simulation…

I searched for "MuJoCo simulation."
▼Once the search was executed, the LLM provided a summary.
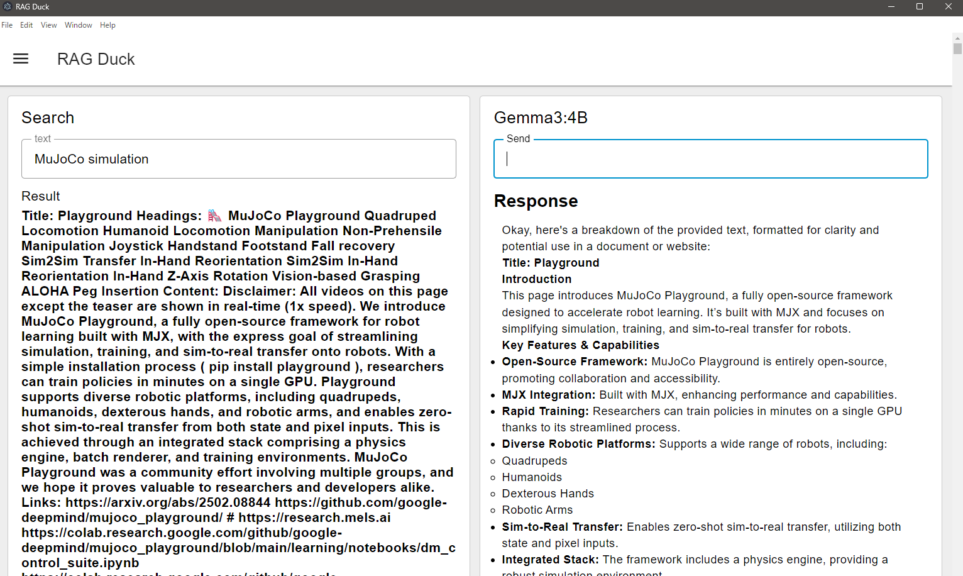
Since the response was in English, I asked it to translate it into Japanese.
▼It provided a Japanese summary, specifically about "MuJoCo Playground."
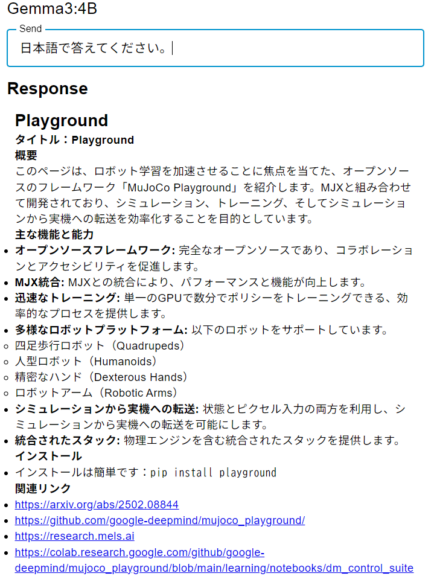
This was actually the first time I had heard of "MuJoCo Playground." I’d like to try it out soon.
▼There was an interesting demo video on the site:
▼MuJoCo Playground GitHub repository:
https://github.com/google-deepmind/mujoco_playground
▼I found the paper on arXiv. It was published in February 2025—just about two months ago. It was so new that I didn't even know it existed.
https://arxiv.org/html/2502.08844v1
Finally
I successfully combined search functionality with a local LLM in Node-RED. Since local LLMs inherently lack knowledge of the latest information, integrating a search function seems crucial.
Even for me, keeping up with the latest news is difficult, and I wasn't aware of MuJoCo Playground until this search result appeared. I plan to expand this flow further to automate my information gathering.